
오늘도 전처리에 대해 배워보려고 합니다. 오늘은 전처리중 스케일링과 원핫인코딩에 대해 배워보도록하겠습니다.
스케일링
스케일링(scaling)이란 데이터를 전처리 하는 과정중 하나로, 데이터의 범위 또는 범위를 같게 설정해 주는 것입니다.
주로 사용되는 개념으로는
- Standardization (표준화)
- 특성들의 평균을 0, 분산을 1로 만들어 특성들을 정규분포로 만드는 것입니다.
- Normalization (정규화)
- 특성들을 특정 범위(ex,[0,1])로 스케일링 하는 것입니다.
* 주의사항
- scaler는 fit과 transform 매서드를 지니고 있습니다.
- 훈련 데이터에는 fit_transform(), 테스트 데이터에는 transform() 메서드를 적용해야합니다.
원핫 인코딩
원핫 인코딩(one-hot encoding)이란 3가지 특성을 가집니다.
- 고유 값에 해당하는 칼럼은 1, 나머지는 0 이것을 원-핫 벡터(ont-hot vector)라고 합니다.
- 0으로 이루어진 벡터에 단 한개의 1의 값으로 해당 데이터의 값을 구별합니다.
- 딥러닝,데이터 마이닝,자연어 처리 등 많은 분야에서 사용합니다.
데이터셋 만들기
input
from patsy import demo_data
import pandas as pd
df=pd.DataFrame(demo_data('x1','x2','x3','x4','x5'))
df output
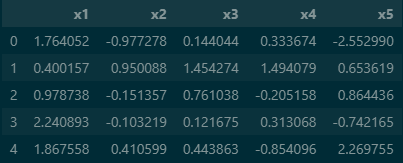
patsy로 데모데이터를 만들어 pands를 이용하여 데이터프라임을 변형시켜 줍니다.
Boxplot 이용
input
df.boxplot()output
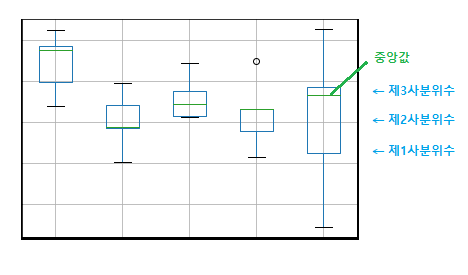
boxplot 함수를 이용하여 데이터의 분포를 확인합니다. 박스는 데이터의 범위, 초록선은 데이터의 중앙값을 나타내줍니다.
스케일링
input
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
df2=scaler.fit_transform(df) #평균 0, 표준편차 1이 되도록 스케일링
df3=pd.DataFrame(df2, columns=df.columns)
df3 output
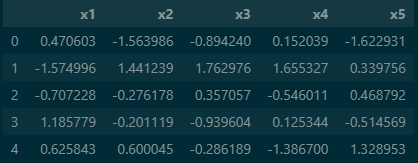
StandardScaler함수를 통해 데이터를 스케일링 해주면 평균이 0 표준편차가 1이 되도록 스케일링을 진행할 수 있습니다.
스케일링한 데이터 boxplot확인
input
df3.boxplot()output
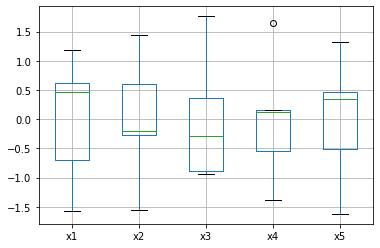
이번에는 이상값을 넣어 데이터가 어떻게 바뀌는지 확인해 보겠습니다.
배열만들기
input
import numpy as np
X=np.arange(7).reshape(7,1) #7행 1열의 2차원 배열
Xoutput
array([[0],
[1],
[2],
[3],
[4],
[5],
[6]])
0~7까지 배열을 만들어 주고,
배열 스케일링
input
scaler=StandardScaler()
scaler.fit_transform(X)output
array([[-1.5],
[-1. ],
[-0.5],
[ 0. ],
[ 0.5],
[ 1. ],
[ 1.5]])
스케일링한 데이터에 이상치(outlier) 넣기
input
X2=np.vstack([X, [[1000]]]) #세로로 쌓음
X2 output
array([[ 0],
[ 1],
[ 2],
[ 3],
[ 4],
[ 5],
[ 6],
[1000]])
1000이라는 이상치를 vstrack함수를 이용하여 넣어줍니다.
스케일링 해보기
input
scaler.fit_transform(X2) output
array([[-0.38705669],
[-0.38402392],
[-0.38099115],
[-0.37795839],
[-0.37492562],
[-0.37189286],
[-0.36886009],
[ 2.64570872]])
스케일링 후에도 이상치(outlier)의 영향력이 강하다는 것을 알 수있습니다. 이런 데이터는 잘못된 영향을 초례할 수 있기때문에
input
from sklearn.preprocessing import RobustScaler
scaler=RobustScaler()
# 이상치의 영향력을 감소시키기 위해 중앙값 0, IQR(InterQuartile Range)이 1이 되도록 변환
scaler.fit_transform(X2)output
array([[-1.00000000e+00],
[-7.14285714e-01],
[-4.28571429e-01],
[-1.42857143e-01],
[ 1.42857143e-01],
[ 4.28571429e-01],
[ 7.14285714e-01],
[ 2.84714286e+02]])
standardscaler가 아닌 robustscarler를 해줍으로써 이상치의 영향력을 감소 시킬 수 있습니다.
데이터 세팅하기
input
df=pd.DataFrame(['A','B','AB','O'],columns=['x'])
df output

원-핫 인코딩
input
df2=pd.get_dummies(df3['x'],prefix='blood')
df2output
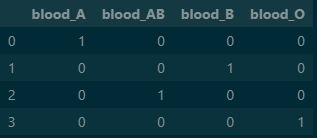
모든 칼럼이 나뉘어지면서 0과 1로 원-핫 인코딩이 된 것을 확인 할 수 있습니다. 1이 어느 곳에 들어가는 지에 따라 나타내주는 값이 달라지기 때문에 원-핫 인코딩을 사용할때는 주의가 필요합니다.
여기까지 전처리에 대해 알아 보았습니다. 오늘도 고생하셨습니다.
😁 power through to the end 😁
