
오늘은 데이터를 전처리하는 방법을 배워보도록 하겠습니다.
전처리(Preprocessing)
전처리란 예비적인 조작을 뜻하는 단어로, 데이터를 전처리 한다는 것은 데이터를 분석 및 처리에 적합한 형태로 변형시키는 과정을 말합니다.
제가 해볼 전처리는 결측값 처리, 스케일링, 원핫인코딩으로 이 시간에는 결측값 처리에 대해 배워 보도록 하겠습니다.
결측값 처리
먼저 결측값이란 알려지지 않고, 수집되지 않거나 잘못 입력된 데이터 세트들의 값입니다.
예시로 프로그래밍 언어 데이터를 분석하려고 하는데 한국어, 영어 등이 들어가 있다면 잘못된 필드가 삽입되어있어 유요하지 않은 값으로 가정하여 공백으로 처리해주어야 합니다.
제가 처음에 많이 하던 실수를 말씀드리자면, 데이터를 전처리 할 때 변수에 저장하지 않는다면 값이 저장되지 않습니다. 예시로 drop을 쓴다면 test.drop()이 아닌
test = test.drop()처럼 해주어야합니다.
데이터 생성하기
input
from io import StringIO
import pandas as pd
test_csv = StringIO("""
test1,test2,test3,test4,test5
1,0.1,"1",2023-01-07,A
2,,,2023-02-12,B
3,,"3",2023-03-30,C
,0.4,"4",2023-04-02,A
5,0.5,"5",2023-04-01,B
,,,2023-05,C
7,0.7,"7",,A
8,0.8,"8",2023-07-08,B
9,0.9,,2023-08-09,C
""")
df = pd.read_csv(test_csv,dtype={"x1": pd.Int64Dtype()},parse_dates=[3])
df
#NaN : Not a Number 결측값 output
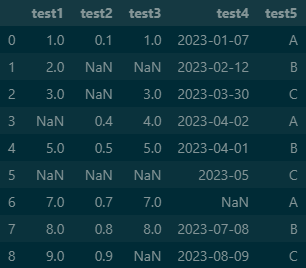
Io 모듈을 이용하여 예시 데이터를 만들었습니다만, 엑셀 파일에 직접 만드셔도 되고, NaN이라는 결측값을 처리하기 위해서 예시로 만든 것이니 데이터를 복잡하게 만드실 필요없습니다.
pandas 모듈을 통해 만들어진 데이터프레임으로 바꾸어줍니다.
결측값 찾기
input
df.isnull()output

isnull 함수는 NaN 값을 찾을 때 사용되는 함수로 NaN 값인 곳을 True로 출력해 줍니다.
matrix 사용하기
input
import missingno as msno
import matplotlib.pyplot as plt
msno.matrix(df)
#흰색 - 결측값
#스파크라인(spark line) - 각 샘플의 데이터 완성도를 표현output

matrix 또한 NaN값을 찾아주는 모듈입니다. 데이터의 NaNr값의 위치를 직관적으로 알 수 있습니다.
bar 사용하기
input
msno.bar(df)#필드별 데이터 완성도output
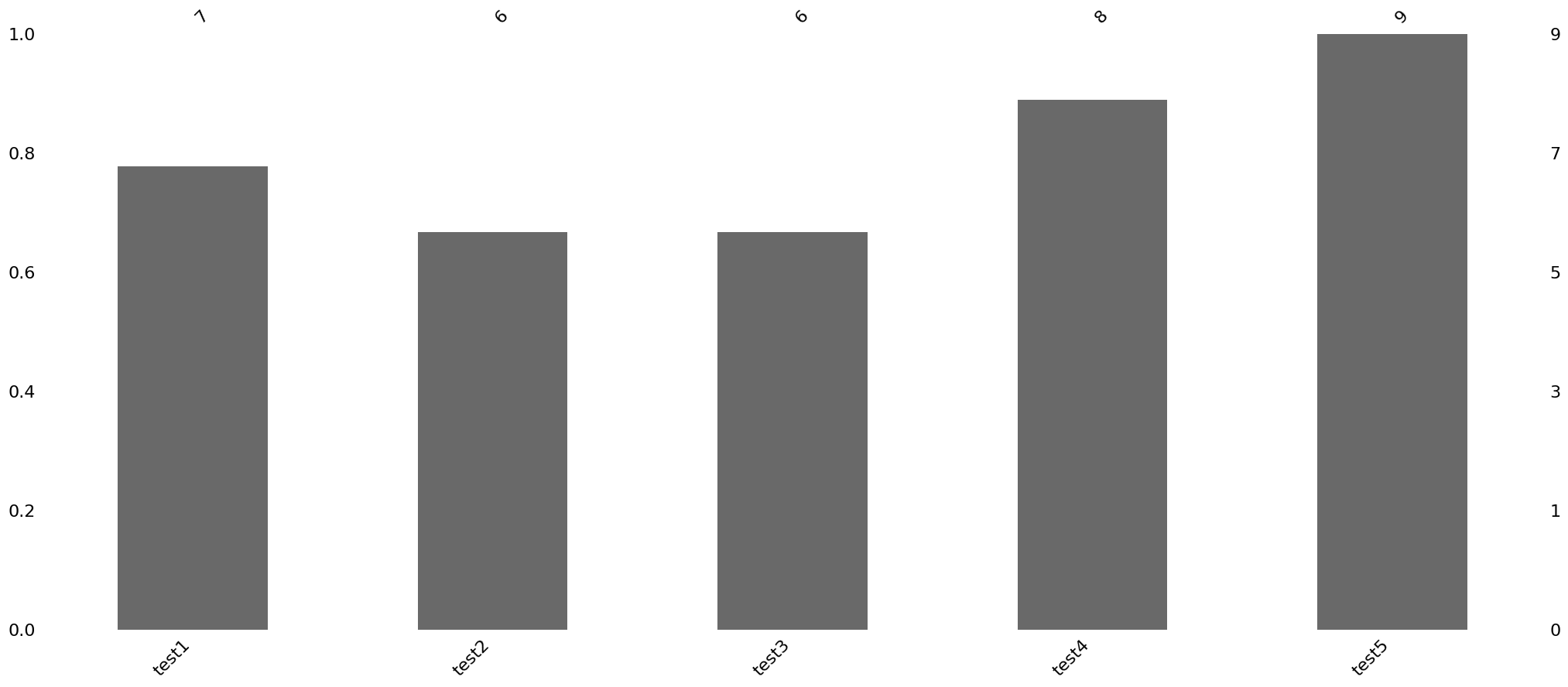
bar 함수는 데이터의 완성도를 확인 하는 함수입니다. 데이터의 NaN값의 양을 직관적으로 알 수 있습니다.
결측값 채우기
input
from sklearn.impute import SimpleImputer
#결측값을 최빈수로 채우는 전략
imputer=SimpleImputer(strategy='most_frequent') # most_frequent : 최빈값, mean : 평균값, median : 중앙값
# fit_transform(데이터) 데이터의 패턴을 분석하고 변환 작업
df=pd.DataFrame(imputer.fit_transform(df),columns=df.columns)
dfoutput
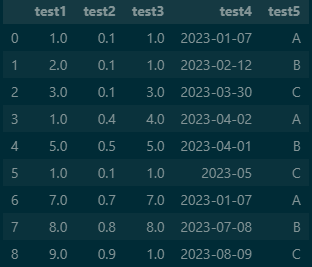
simpleimputer 함수를 이용하여 결측값을 최빈값으로 대체해 줄 수 있습니다. 예상 데이터를 컴퓨터가 계산에 넣어주는 것입니다.
다 사용한 데이터로 여러가지 더 배워보도록 하겠습니다.
데이터 삭제
input
df = df.drop(['test3'],axis=1)
dfoutput
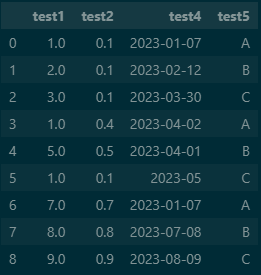
test3인 칼럼이 삭제 되었습니다. axis = 1 은 열을 뜻하기 때문에 test3이 가진 모든 열을 삭제 할 수 있습니다. (행은 axis = 0입니다.)
특정 열의 결측값 갯수 찾기
input
df.iloc[:,2:3].isnull().sum()output
test4 0
dtype: int64
이미 데이터를 처리하여 결측값이 없습니다만, iloc을 이용하여 [행인덱스:행인덱스,열인덱스:열인덱스]을 행범위 열범위를 정해 원하는 데이터만 추출하여 사용할 수 있고, isnull()의 갯수를 sum()함수를 이용하여 결측값의 갯수를 측정할 수 있습니다.
Seaborn로 dataset 사용하기
input
import seaborn as sns
titanic=sns.load_dataset('titanic')
titanic.tail()output
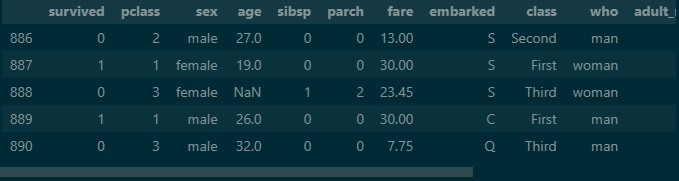
Seaborn 모듈에서 제공해주는 데이터셋들이 있습니다. 그 중 titanic 데이터 셋을 활용하여
결측값 제거
input
#titanic.dropna() #결측값이 있는 모든 행 삭제
#titanic.dropna(axis=1) #필드 제거 axis = 1 (행) axis = 0 (열)
#titanic.dropna(thresh=7, axis=1) # 7개를 기준으로 필드 제거
#50% 기준
titanic=titanic.dropna(thresh=int(len(titanic)*0.5),axis=1)
msno.matrix(titanic)output

결측값이 50% 이상 있는 데이터는 결과값에 영향이 없으므로 아예 삭제를 시켜 줍니다.
simpleimputer 사용하기
input
from sklearn.impute import SimpleImputer
#결측값을 최빈수로 채우는 전략
imputer=SimpleImputer(strategy='most_frequent') # most_frequent : 최빈값, mean : 평균값, median : 중앙값
# fit_transform(데이터) 데이터의 패턴을 분석하고 변환 작업
titanic=pd.DataFrame(imputer.fit_transform(titanic),columns=titanic.columns)
titanic output
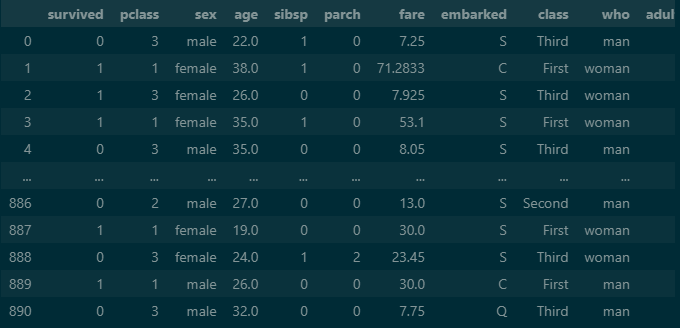
most_frequent(최빈값)을 이용하여 NaN값들의 예상치를 채워 줍니다.
출발지 결측값 제거
input
#범주형 데이터 - 최빈수로 채우는 전략
imputer_embark_town=SimpleImputer(strategy='most_frequent')
titanic['embark_town']=imputer_embark_town.fit_transform(titanic[['embark_town']])
titanic['embarked']=imputer_embark_town.fit_transform(titanic[['embarked']])output
embark_town은 출발지에 대한 데이터입니다. 해당 데이터 칼럼은 최빈수로 결측값을 채워줍니다.
age 결측값 확인
input
import numpy as np
print(np.mean(titanic.age))
print(np.median(titanic.age))
plt.hist(titanic.age) #히스토그램
plt.title('age')
plt.show()
#수치형 데이터 - 평균 또는 중위수로 채우는 전략
# 정규분포(좌우대칭형) - 평균
# 비정규분포 - 중위수 output
28.566969696969696
24.0
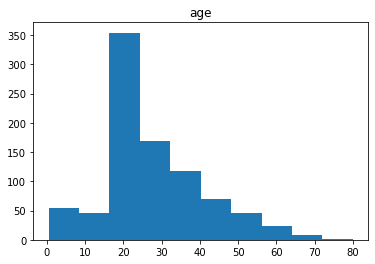
수치형 데이터(숫자형)는 평균 또는 중위수로 주로 다룹니다.
해당 데이터는 20대에 몰려 있기 때문에 비정규분포이기에 중위수로 결측값을 채우려고 합니다.
결측값 채우기
input
imputer_age=SimpleImputer(strategy='median') #중위수로 채우는 전략
titanic['age']=imputer_age.fit_transform(titanic[['age']])
msno.matrix(titanic)output
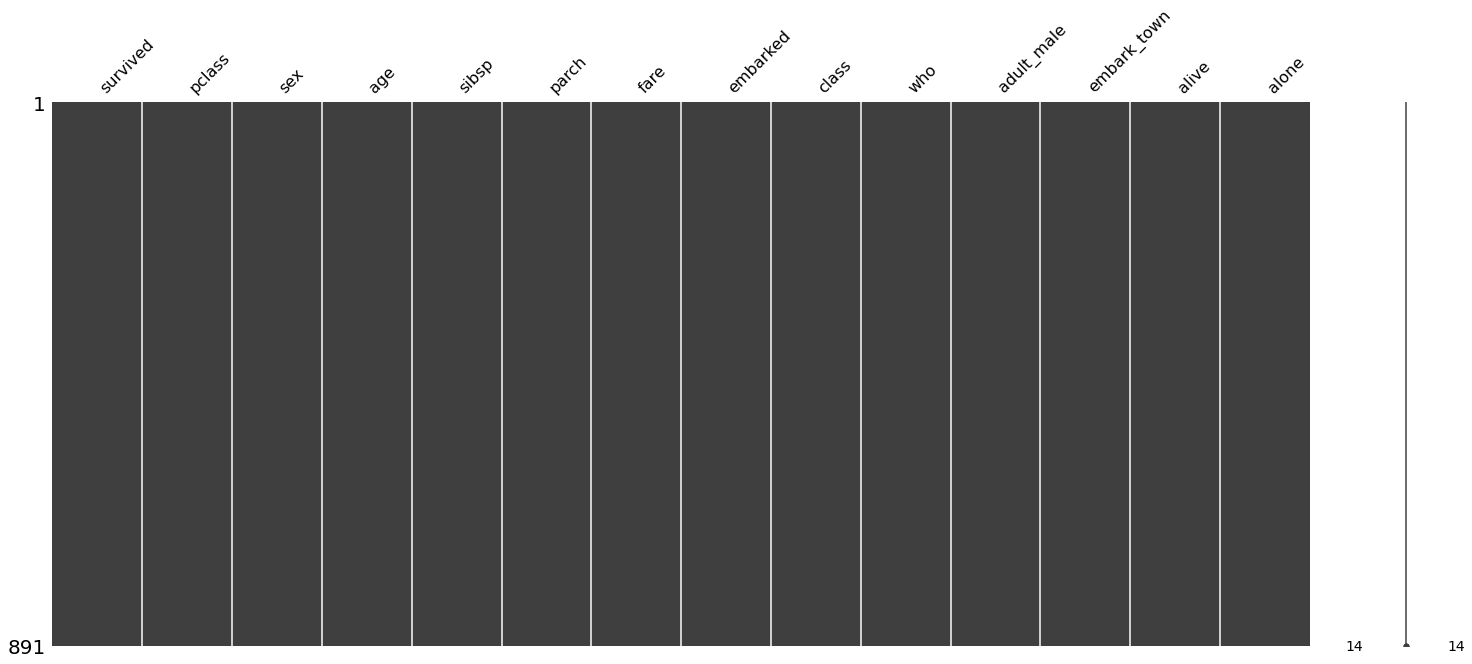
결측값 처리 후와 처리 전모든 결측값이 최빈수와 중위수로 채워졌기 때문에 그림이 빈칸이 없게 됩니다.
이상으로 결측값처리에 대해 간단하게 배워보았습니다. 역시 데이터는 어렵습니다만.. 모두 잘하실거라 믿습니다. 혹시나 틀린부분이 있다면 알려주시면 감사하겠습니다.
😁 power through to the end 😁
