
이번시간은 전시간에 이어서 ANN을 이용하여 대용량데이터를 분석해 보려고합니다.
데이터셋 불러오기
input
from sklearn import datasets
import numpy as np
iris=datasets.load_iris()
X=iris.data[:, :4]
y=iris.target
idx=np.arange(X.shape[0])
print(idx)
np.random.seed(0)
np.random.shuffle(idx)
print(idx)
X=X[idx]
y=y[idx]output
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107
108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125
126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143
144 145 146 147 148 149][114 62 33 107 7 100 40 86 76 71 134 51 73 54 63 37 78 90 45 16 121 66 24 8 126 22 44 97 93 26 137 84 27 127 132 59 18 83 61 92 112 2 141 43 10 60 116 144 119 108 69 135 56 80 123 133 106 146 50 147 85 30 101 94 64 89 91 125 48 13 111 95 20 15 52 3 149 98 6 68 109 96 12 102 120 104 128 46 11 110 124 41 148 1 113 139 42 4 129 17 38 5 53 143 105 0 34 28 55 75 35 23 74 31 118 57 131 65 32 138 14 122 19 29 130 49 136 99 82 79 115 145 72 77 25 81 140 142 39 58 88 70 87 36 21 9 103 67 117 47]
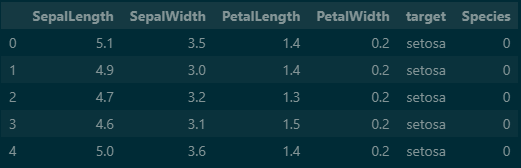
iris 데이터셋을 pandas를 이용하여 데이터프레임화 시키면 다음과 같은 모형입니다. 해당 모형의 petalWidth 까지 X로 설정 target을 y, Species를 제외 시켰습니다.
스케일링
input
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
# scaler.fit(X)
# X=scaler.transform(X)
X=scaler.fit_transform(X)StandardScaler을 이용하여 데이터를 표준화 시켜줍니다.
ANN 설정
input
from sklearn.model_selection import GridSearchCV
from sklearn.neural_network import MLPClassifier
params={
'hidden_layer_sizes':[
(10,),(50,),(100,),(10,10),(50,50),(100,100)
],
'activation': ['tanh','relu'],
'alpha': [0.0001, 0.01]
}
model=MLPClassifier(random_state=0, max_iter=5000)
clf=GridSearchCV(model, param_grid=params, cv=3)
clf.fit(X,y)output
Params 부분만 전 시간과 다른데 이것은 은닉충등의 옵션의 최적화를 하기 위해 사용하는 것입니다.
정확도 확인
input
print(clf.best_score_)
print(clf.best_estimator_)output
0.9733333333333333
MLPClassifier(activation='tanh', hidden_layer_sizes=(50,), max_iter=5000,
random_state=0)
최적화된 옵션과 정확도를 알 수 있습니다.
데이터 분류
input
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,stratify=y,random_state=0)연습과 검증 데이터로 나누어 줍니다.
분류된 데이터 스케일링
input
scaler=StandardScaler()
scaler.fit(X_train)
X_train=scaler.transform(X_train)
X_test=scaler.transform(X_test)분류된 데이터를 다시 스케일링하여 표준화 시켜줍니다.
batch 설정
input
from sklearn.metrics import accuracy_score
def batch(X1, y1, n):
x_size=len(X1)
for idx in range(0, x_size, n):
yield X1[idx:min(idx+n, x_size)], y1[idx:min(idx+n,x_size)]
clf=MLPClassifier(max_iter=1000, random_state=0)
clf.fit(X_train, y_train)
pred=clf.predict(X_test)
print(accuracy_score(y_test, pred))output
0.9666666666666667
batch 작업을 하기 위해 함수를 만들어 줍니다. batch라는 것은 예시로 500개의 데이터가 있을 때 batch를 25로 설정하면 25개씩 총 20번 학습하는 것입니다. 해당 내용은 tensorflow 부분에서 상세히 서술할 예정입니다.
학습시키기
input
def batch(X1, y1, n):
x_size=len(X1)
for idx in range(0, x_size, n):
yield X1[idx:min(idx+n, x_size)], y1[idx:min(idx+n,x_size)]
clf2=MLPClassifier(random_state=0)
points_tr=[]
points_te=[]
samp=batch(X_train, y_train, 10)
for idx, (chunk_X, chunk_y) in enumerate(samp):
print(idx)
clf2.partial_fit(chunk_X, chunk_y, classes=[0,1,2])
pred=clf2.predict(X_train)
point=accuracy_score(y_train, pred)
points_tr.append(point)
print('학습용:',point)
pred=clf2.predict(X_test)
point=accuracy_score(y_test, pred)
points_te.append(point)
print('검증용:',point)output
0
학습용: 0.48333333333333334
검증용: 0.5
1
학습용: 0.525
검증용: 0.5333333333333333
2
학습용: 0.6416666666666667
검증용: 0.6333333333333333
3
학습용: 0.725
검증용: 0.7
4
학습용: 0.7833333333333333
검증용: 0.7333333333333333
5
학습용: 0.825
검증용: 0.7666666666666667
6
학습용: 0.8416666666666667
검증용: 0.7666666666666667
7
학습용: 0.8333333333333334
검증용: 0.8
8
...
검증용: 0.8
11
학습용: 0.8583333333333333
검증용: 0.8
다음과 같이 학습 정확도가 점점 상승하는 것을 확인 할 수 있습니다.
정확도 상승폭 확인
input
import matplotlib.pyplot as plt
plt.plot(range(1,13),points_tr,label='Train')
plt.plot(range(1,13),points_te,label='Test')
plt.ylabel('Accuracy')
plt.xlabel('samples')
plt.legend()
plt.show()output
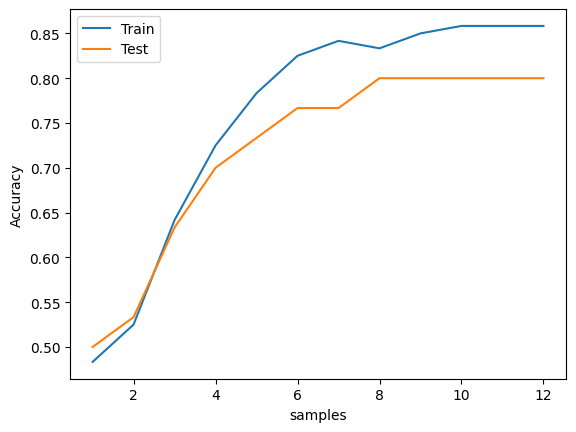
다음과 같이 정확도가 증가하는 것을 확인이 되는데, 해당 내용을 확인하는 이유는 정확도 상승률이 적은 시점부터 강제로 학습을 종료시키기 위함입니다.
정확도를 높이기 위해 학습을 더욱 진행한다면 과적합이 나와 오히려 데이터의 정확도만 뻥튀기 되는 경우가 생깁니다.
이번 시간은 은 저번 시간에 이어 ANN을 이용하여 대용량 데이터를 분석해 보았습니다.
다음시간에는 활성화 함수 및 batch함수를 만들 때 사용한 방법에 대해 추가적으로 설명해 보도록하겠습니다.
😁 power through to the end 😁
