
오늘은 인공신경망(Artificial Neural Network,ANN)에 대해서 배워보도록 하겠습니다.
인공신경망(ANN)
인공신경망(Artificial Neural Network,ANN)이란 딥러닝의 기초가 되는 기계학습 알고리즘(컴퓨터가 인지/추론/판단)입니다.
사람의 신경망 원리와 구조를 모방하여 만들어진 알고리즘 입니다.
중요 특징으로는
| 인공신경망 | 신체 |
|---|---|
| 노드(node) | 뉴런 |
| 레이어(layer) | 여러 뉴런이 모여있는 단위 |
| 가중치(weight) | 신호의 세기 |
| 임계값(bias) | 할성함수에 의해 구해진 망의 총합을 다음 층으로 넘길 때 기준값 |
신체의 뉴런(신경계와 신경조직을 이루는 기본 단위)을 기준으로 노드 레이어 등으로 모방되어 제작된 것을 인공신경망이라고 합니다.
구성
1. 입력층(input layer)
- 외부의 자극을 받아 들이는 뉴런의 집합(다수의 입력 데이터의 입력을 담당)
2. 은닉충(hidden layer)
- 입력 값을 넘겨받는 층으로 입력층과 출력층 사이에 존재하는 층
- 활성화 함수를 사용하여 최적의 가중치(weight)와 임계값(bias)를 찾아내는 역할
3. 출력층(output layer)
- 최종 판단을 출력하는 뉴런의 집합(데이터의 출력을 담당)
활성화함수(activation function)
-입력받은 신호에 따라 적절한 처리후 출력하는 함수
-출력된 신호가 다음 단계에서 활성화 되는지 결정
-step function등 활성화 함수 존재
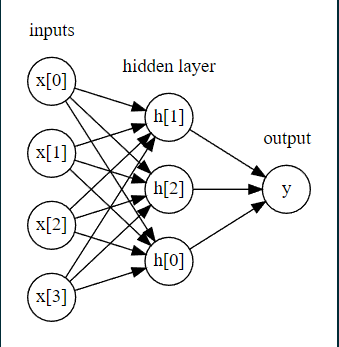
다음 사진과 같은 모형을 인공신경망이라고 합니다.
장단점
장점
- 인공지능의 학습을 통해 더 나은 의사결정을 할 수 있음
- 질적 변수나 양적 변수에 관계없이 모두 분석 가능
- 입력 변수들 간의 비선형 조합이 가능
- 예측력이 우수
단점
- 과적합(overfitting)
- 매개변수의 최적값을 찾기 어려움
- 시간과 하드웨어 성능이 뒷받침해야함
- 개인의 정보를 침해 할 수 있음
- 결과 해석이 어려움
- 분석시 변두들을 랜덤하게 넣기 때문에 결과가 일정하지 않음
ANN의 방법 추가 2가지
DNN(Depp Neural Network)
-ANN 기법에서 은닉충을 늘력 학습 능력향상(은닉충2개이상)
-DNN을 이용한 알고리즘인 CNN,RNN등이 있음
CNN(Convolutional Necural Network,합성신경망)
-기존의 방식은 데이터의 지식을 추출하여 학습하는것이 아닌 데이터의 특징을 추출하 패턴 파악
-Convaoution과 pooling의 과정으로 이루어짐
-convolution 망을 추가해서 인근 픽셀들의 가중치를 조절 후 신호를 만듦
인공신경망 예시
input
mglearn.plots.plot_two_hidden_layer_graph()output
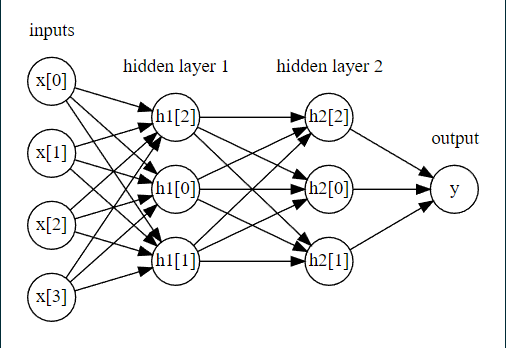
두개의 은닉충과 input, output을 확인 할 수 있습니다.
데이터셋 불러오기
input
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=100, noise=0.25, random_state=3)모델 분류
input
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,stratify=y,random_state=0)여기 까지는 다른 학습과 동일합니다.
모델 학습
input
from sklearn.neural_network import MLPClassifier
# 1개의 hidden layer, 100개의 hidden node
model=MLPClassifier(random_state=0, max_iter=5000).fit(X_train,y_train)
print(model.score(X_train,y_train))
print(model.score(X_test,y_test))output
0.925
0.9
hidden layer와 hidden node은 디폴트 값으로 1과 100으로 설정하고 max_iter를 이용하여 5000회 까지만 반복학습 하도록 설정해 줍니다.
시각화
input
mglearn.plots.plot_2d_separator(model, X_train, fill=True, alpha=0.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)output
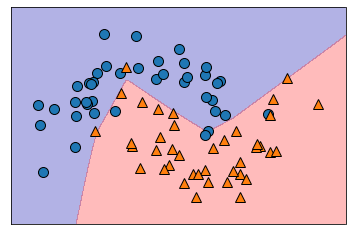
node수 조절
input
# hidden node를 10개로 줄인 모형
model=MLPClassifier(random_state=0, max_iter=1000, hidden_layer_sizes=[10]).fit(X_train,y_train)
print(model.score(X_train,y_train))
print(model.score(X_test,y_test))output
0.85
0.85
시각화
input
mglearn.plots.plot_2d_separator(model, X_train, fill=True, alpha=0.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)output
은닉충 조절하기
input
# hidden layer를 2개로 늘린 모형
model=MLPClassifier(random_state=0, max_iter=1000, hidden_layer_sizes=[10,10]).fit(X_train,y_train)
print(model.score(X_train,y_train))
print(model.score(X_test,y_test))output
0.8375
0.85
시각화
input
mglearn.plots.plot_2d_separator(model, X_train, fill=True, alpha=0.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)output
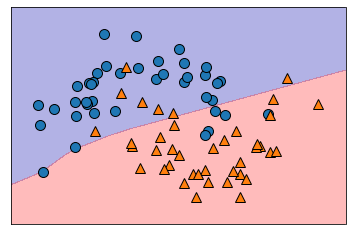
은닉충 조절
input
# hidden layer 3개
model=MLPClassifier(random_state=0, max_iter=1000, hidden_layer_sizes=[100,100,100]).fit(X_train,y_train)
print(model.score(X_train,y_train))
print(model.score(X_test,y_test))output
1.0
1.0
시각화
input
mglearn.plots.plot_2d_separator(model, X_train, fill=True, alpha=0.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)output
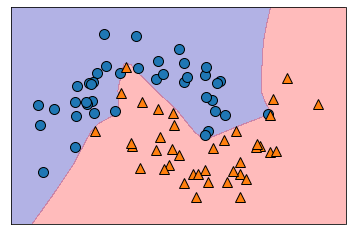
은닉충과 노드수를 조절함으로써 데이터의 정확도를 높일 수 있습니다. 해당 방식은 직접 하나씩 하였지만 이 또한 파이프라인을 이용하여 찾을 수 있습니다.
글이 길어져 여기서 마치고, 다음 시간에는 인공신경망에 대해 좀 더 알아보도록 하려고합니다.
😁 power through to the end 😁
