읽기 귀찮으면 들으세요: https://www.youtube.com/watch?v=YvSz9ydv2vg
TLDR:
- LLM 사용자 측면: 좋은 성능의 AI 모델을 무료로 제공. API 가격도 OpenAPI 모델보다 훨씬 저렴
- 주가 측면: 경쟁사와 비교했을때 모델 개발에 필요한 비용이 훨씬 낮아 AI 수혜주들의 주가 하락이 발생함
Deepseek가 뭔가요?
Deepseek은 중국 항저우의 AI 스타트업 회사입니다. Liang Wenfeng이라는 젊은 CEO가 운영하고 있습니다. 딥시크의 AI 모델은 chatgpt처럼 웹 사이트를 통해 사용해볼 수 있습니다.
https://chat.deepseek.com/
Deepseek가 왜 유명해졌나요?
딥시크는 최근 공개한 R1 모델 때문에 많은 관심을 가지고 있습니다.
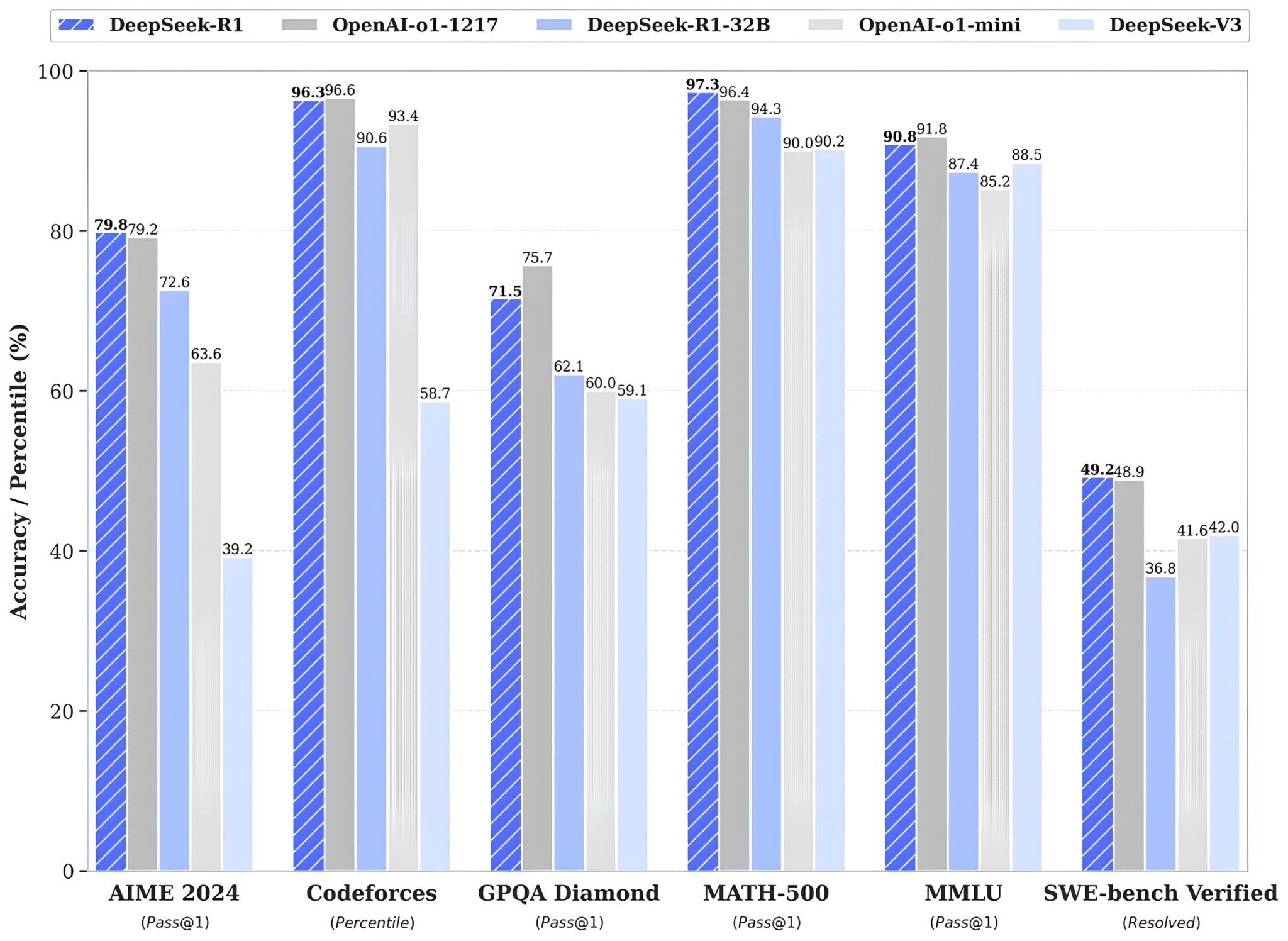
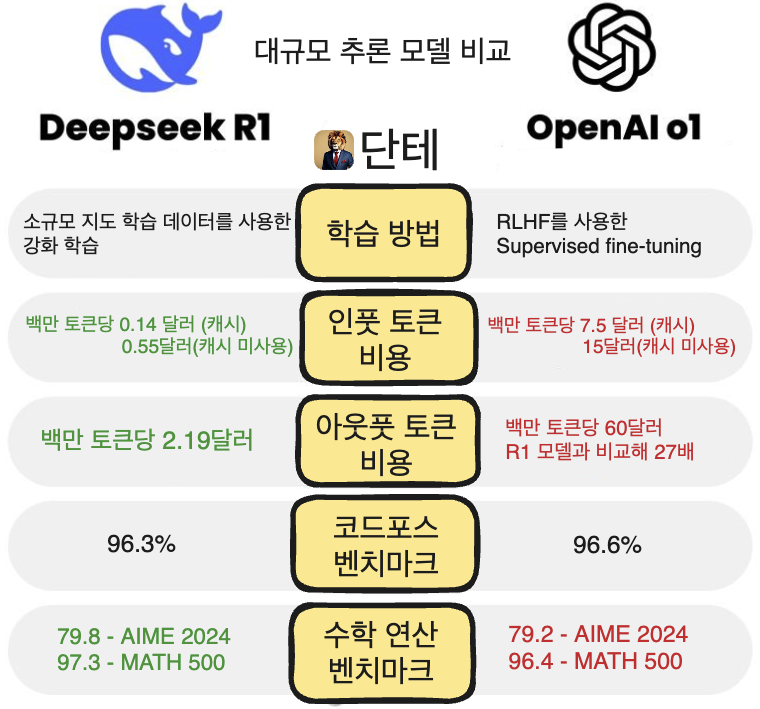
딥시크는 벤치마크의 많은 항목에서 R1이 Open AI의 o1(최신 모델)모델과 비교했을 때 대등하거나 더 좋은 평가를 받았다고 이야기하고 있습니다.
o1모델을 무제한 사용하기 위해서는 Open AI에서 최근에 출시한 Pro 플랜을 구독해야 하는데 200달러를 지불해야 합니다. 개인으로서는 부담되는 금액일 수밖에 없는데 시기적절하게 딥시크가 R1을 무료사용으로 풀었기에 hyped 된 것으로 보고 있습니다.
CEO Liang Wenfeng은 10년 이상의 시니어 개발자 및 연구자들보다는 주니어/미들급 연차의 인원을 선호하는 경향을 보이는데 한 인터뷰에서를 인용하자면 그는 고연차의 사람들은 주어진 일에 대해 어떻게 처리해야 하는지에 대해 정의한다면 낮은 연차의 사람들은 비교적으로 반복적인 실험을 통해 최고의 접근방법에 대해 깊히 생각함으로써 실제 상황에 맞는 솔루션을 찾기 때문이라고 말합니다.
Deepseek VS Open AI
비용 및 성능
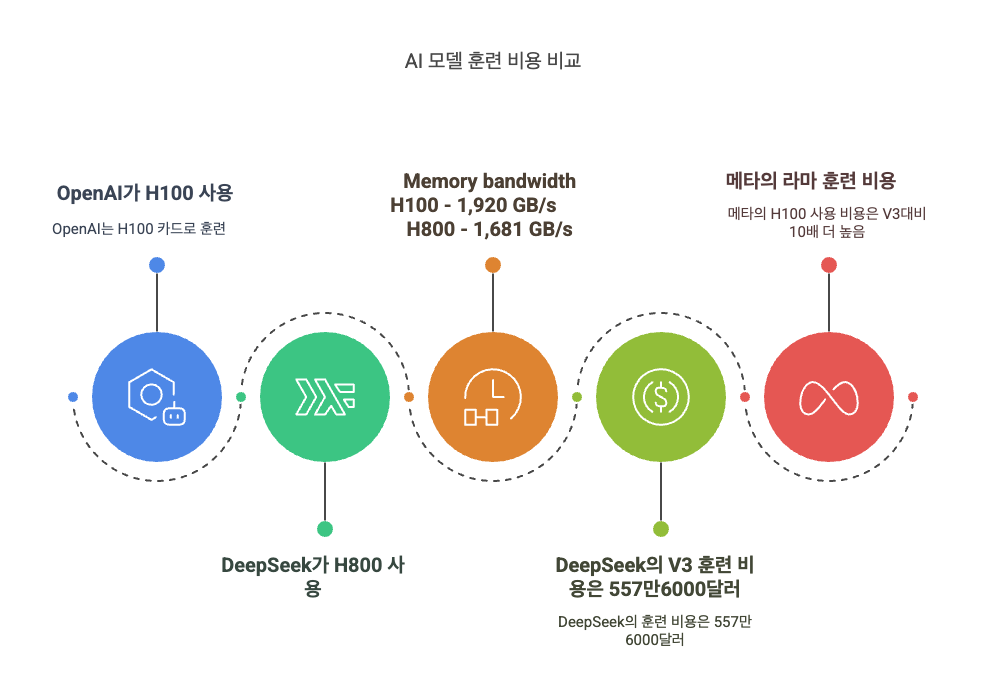
훈련 비용
Open AI는 모델 학습에 엔비디아의 H100 그래픽 카드 모델을 사용하고 딥시크는 엔비디아에서 H100보다는 저가용 그래픽 카드 모델인 H800을 사용합니다. H800은 H100에 비해 메모리 대역폭이 절반 정도입니다.
H100 한대로 학습시키는 시간보다 H800으로 학습시키는 시간이 2배가 걸린다고 보면 되겠습니다. 그럼에도 불구하고 딥시크의 V3 모델에 투입된 개발 비용은 557만6000달러(한화 약 78억8000만원)인데 메타가 최신 AI 모델인 라마(Llama) 3 모델을 엔비디아의 고가 칩 H100으로 훈련한 비용과 비교하면 10분의 1 수준이어서 화제가 되었습니다.
사용 비용
저는 chatGPT Plus 플랜을 구독 중인데 o1, o1-mini 모델 사용시 Quota가 제한적으로 정해져 있어 열심히 작업하는 날이면 하루에도 정해진 Quata를 다 사용하고는 합니다. 무제한으로 사용하기 위해서는 아래와 같은 선택지가 있는데
- 200달러 지불하고 pro 플랜 구독
- Web UI 사용하지 않고 API로 사용
API 사용시 R1 모델보다 27배 비싼 60달러를 지불해야 합니다.
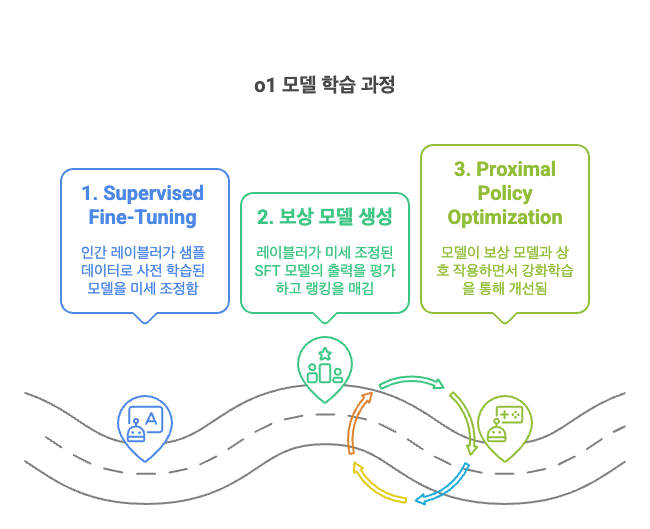
RLHF: 강화 학습에 인간 피드백 기반 보상 모델을 사용하여 반복적으로 학습시켜 사람이 선호하는 응답을 내보내도록 유도하는 것
SFT: Supervised Fine Tuning의 줄임말 미세 조정을 통해 LLM을 특정 작업에 특화되게 하는 것
나스닥 주가, 주의할 점 및 로컬 머신으로 사용하는 방법
엔비디아 주가와 나스닥 주가
AI 학습 비용이 더 낮음에도 좋은 성능의 모델을 만든 딥시크로 인해 AI 붐의 수혜를 받고 있는 엔비디아의 주가가 딥시크 런칭 이후 17% 폭락했고 나스닥도 3% 가량 하락했습니다.

웹 UI 사용시 조심할 점
딥시크 R1 모델 사용은 https://chat.deepseek.com/ 에서 가능한데 사이트 사용시 검색 및 개인정보가 미래 중국 정부에서 활용될 수 있기에 찜찜하다면 사용하지 말아야 합니다.

로컬 머신으로 사용하기
이를 우회할 수 있는 방법이 있는데 딥시크의 R1 모델은 충분한 성능의 컴퓨터를 소유하고 있는 사람이면 로컬 환경에서 무료로 R1 모델을 사용할 수 있기에 Ollama를 사용해 딥시크 R1 모델을 실행시킬 수 있습니다.
Ollama는 LLM을 로컬 환경에서 쉽게 사용할 수 있게 도와주는 커맨드라인 툴이며 맥북에서 실행시킬 수 있습니다. Ollama는 오픈소스 프로젝트입니다. 모델 사용시 외부 API를 사용하지 않기에 인터넷 연결이 되지 않아도 모델 추론을 실행시킬 수 있습니다. Ollama만 설치하면 커맨드라인으로만 사용할 수 있지만 Ollama + 다운받은 모델 조합으로 데스크탑 앱에서 실행을 도와주는 데스크탑 앱도 있으므로 로컬에서 모델 사용시 Ollama는 필수입니다.
Ollama

VScode와 로컬 환경에서 딥시크 R1 모델을 결합한다면 커서를 사용하지 않고도 코드 작성에 도움을 받을 수 있다는 뜻입니다.
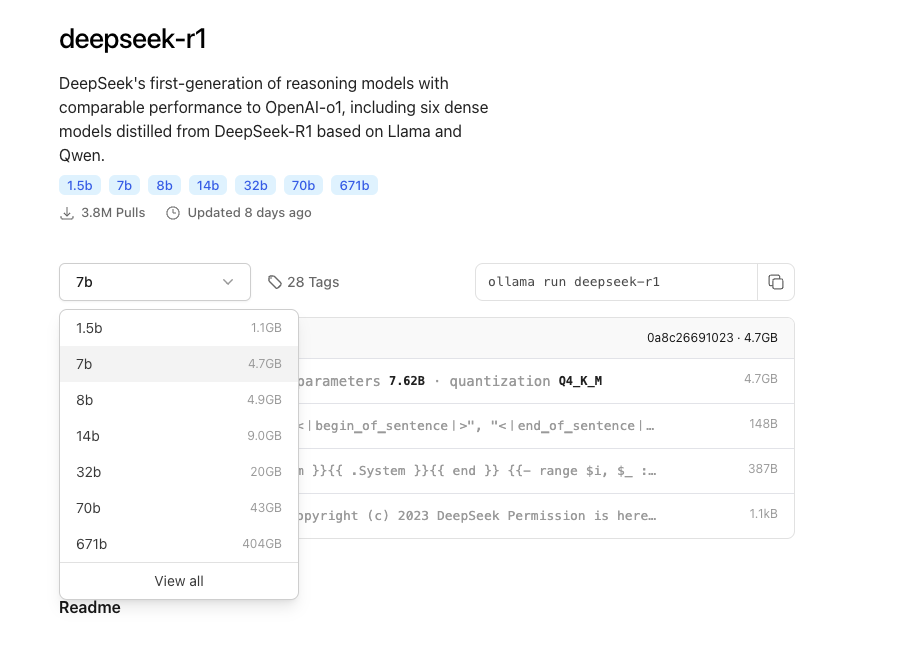
개인적인 의견이지만 최소 70b 파라메터 모델을 사용해야 만족할만한 성능을 사용할 수 있다. CPU만 활용해 모델을 돌리는 것은 컴퓨터 발열과 출력 토큰 속도 저하의 요인이 되므로 고성능 GPU를 사용해야 실사용하는데 무리가 없다.
하지만 개인이 가진 컴퓨터의 성능에 따라 모델의 성능이 크게 차이가 나므로 모든 사람이 로컬에서 AI 모델을 돌리는 건 어려운 일입니다. 이에 대한 대안으로 딥시크 API key를 발급받아 Cline VSCode 확장 프로그램에서 딥시크 모델을 사용할 수 있습니다.
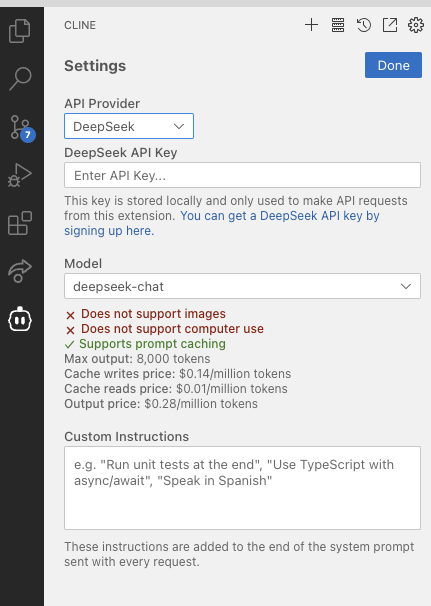
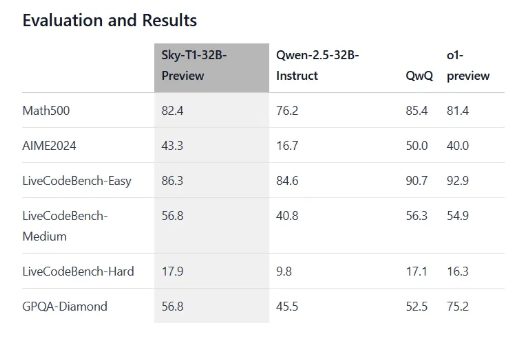
딥시크 hype은 뒷북일 수 있습니다.
o1모델과 유사한 성능을 보이거나 벤치마크의 몇 종목에서 더 나은 부분을 보인 것은 딥시크 R1 모델이 처음은 아닙니다. 인터넷에 검색만 해보더라도 Sky-T1 preview 모델이 Math-500 및 여러 부분에서 좋은 평가를 받은 것을 볼 수 있습니다.
https://decrypt.co/300956/free-reasoning-ai-model-beats-openai-o1-chatgpt