
이번 시간에는 컴퓨터가 수치 데이터를 어떻게 나타내고 저장하는지 알아본다.
지난 시간에는 트랜지스터를 사용하여 논리 게이트를 구축하고 부울문을 평가할 수 있는 방법에 대해 이야기했다.
부울대수학에서는 참과 거짓 오직 2가지 값만을 사용.
0과 1을 사용하는 하나의 이진수는 숫자를 나타내는 데 사용할 수 있다. 큰 수를 나타내고 싶다면 단순히 이진 숫자들을 더하기만 하면 된다! 이는 십진법과 동일한 방식으로 작동함. 10진수에서는 10가지의 가능한 한 자리 숫자가 있다. 0~9. 9보다 큰 수를 만들려면 그 앞 쪽에 하나의 숫자를 추가하면 된다. 이진수에서도 원리가 같음 !
ex. 십진수(decimal notation)
263은 2개의 100, 6개의 10, 3개의 1을 의미.
즉, 263 = 210^2 + 610^1 + 3*10^0
ex. 이진수()
101은 1개의 4, 0개의 2, 1개의 1을 의미.
즉, 101 = 12^2 + 0 2^1 + 1* 2^0
이를 모두 더하면 10진수에서 의미하는 5를 얻게 된다.
이제 10110111을 10진수로 바꿔볼까?

이제 덧셈을 해보자.
십진수에서 183 + 19를 하려면?
일의 자리부터 3+9 =12이므로 일의 자리에 2를 쓰고 1을 10의 자리에 받아올림해 준다.
이진수에서 10110111 + 000010011 = ?
1+1=10인 것을 기억하면 세로로 쉽게 덧셈할 수 있다.
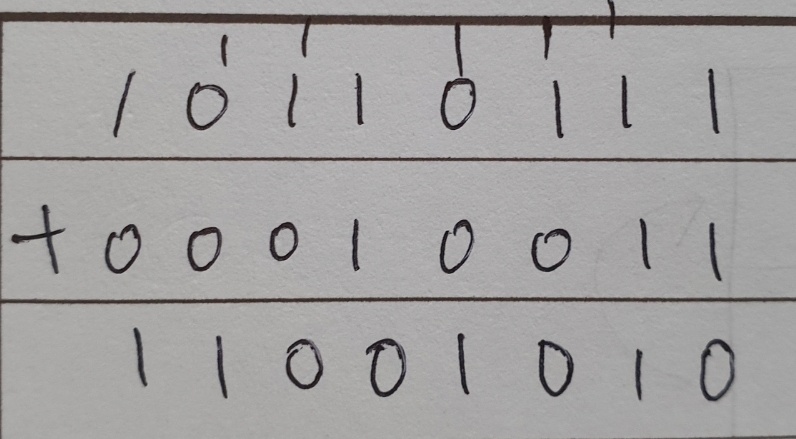
이를 10진수로 바꾸면 202가 되어 10진수끼리의 덧셈과 결과가 같음!
이진수에서 1과 0은 각각 비트라고 부른다. 만약 8비트의 숫자를 사용한다면, 해당 수의 범위는 00000000~11111111로, 0~225, 혹은 0~2^8가 된다.

8비트 게임의 경우 256가지 색의 그래픽으로 한정되었다는 것을 의미한다.
8비트는 바이트라는 특별한 단어로 불렸다. 즉, 1바이트는 8비트. 10바이트는 80비트를 의미.
1kilo byte = 1000byte = 8000bit 또는 더 정확히 표현하면,
1kilo byte = 2^10byte = 1024byte
1mb=100만byte
1gb=10억byte
오늘날 우리는 1테라바이트(8조개의 0과 1)의 저장공간이 있는 하드드라이브를 갖고 있기도 하다.
32비트로 나타낼 수 있는 가장 큰 숫자는 43억 미만의 숫자(32개의 1).
현재 컴퓨터는 32비트 색상의 그래픽을 사용하기 때문에 수백만가지 색깔로 만들어질 수 있다.
음수는 어떻게 나타내나?
대부분의 컴퓨터는 부호의 첫번째 비트에서 1을 음의 값, 0을 양의 값을 나타내는 신호로 사용한다. 그리고 나머지 31비트는 그 숫자 자체를 나타낸다. 이걸로 대략 +-2십억까지의 범위의 수를 쓸 수 있다. 이 범위면 충분하냐고? 그렇지 않다. 지구 상 인구는 70억이고 미국의 국가 채무는 20조달러에 이름. -> 64비트 숫자가 필요해.

64비트로 나타낼 수 있는 가장 큰 숫자는 대략 +-920경(9.2*10^18)
이 정도 숫자면 미국 채무보다는 적어도 한동안은 더 크지 않을까 싶다.
컴퓨터 메모리가 기가바이트, 테라바이트, 수 조 바이트로 커지면서 64비트 메모리 주소도 필요해졌다.
컴퓨터는 음수와 양수 뿐만 아니라, 정수가 아닌 다른 수도 다룰 수 있어야 한다. ex. 12.7, 원주율 등. 이를 부동 소수점(floating number)라고 한다. 부동 소수점을 나타내기 위한 여러 방법들이 개발됨. 가장 일반적인 것은 IEEE754 표준. 소수를 과학적인 표기법으로 저장한다.
ex. 625.9 = 0.6259 * 10^3로 적는다. 여기서 6259는 유효숫자, 3은 지수라고 함.
32비트 부동 소수점 표기법에서, 첫번째 비트는 양이나 음의 부호를 나타내는 숫자를 넣는 데 사용.
ex. 01000100000111000111100110011010에서
첫번째 0은 양이나 음의 부호를 나타낸다.
그 다음 8비트는 지수를 저장하는 데 사용.
나머지 23비트는 유효숫자를 나타내는 데에 사용.
컴퓨터는 문자를 나타낼 때도 숫자를 사용한다.
가장 직접적인 접근 방식은 단순하게 알파벳의 문자들에 번호를 매기는 방식. A는 1, B는 2,C는 3 이런 식으로.
영국의 유명한 작가 Francis Bacon은 1600년대에 비밀 메세지를 보낼 때 26개의 모든 알파벳을 암호화하는 데에 5비트의 연속된 순서를 사용했다. 5비트는 32가지 값을 저장할 수 있기 때문에 26개의 문자를 나타내는 데에 적합.
하지만 구두점, 숫자, 대소문자를 나타내기에는 부적합했다.
ASCII(정보 교환을 위한 미국의 표준 코드)는 1963년에 발명된 7비트 코드. 128개의 다른 값을 저장할 수 있었다. 대문자, 소문자, 0~9 범위의 숫자, @기호, 구두점 등 상징적인 것도 인코딩할 수 있게 되었다.
ex. a는 97을 의미. A는 95를 의미. :은 58을 의미. )은 41을 의미.
(띠용..?)
아스키의 특별한 명령 코드의 집합이 있었다. 줄바꿈 문자를 사용해서 다음 행으로 줄 바꿀 위치를 컴퓨터에게 알려줄 수 있도록 함.
ASCII는 초기의 표준이었기 때문에 널리 사용되었고, 특히 다른 회사에서 만든 여러 컴퓨터와 데이터를 교환하는 데에 중요하게 사용되었다. 보편적으로 정보를 교환할 수 있는 이 능력을 "상호 운용성(Interoperability)"라고 한다. 하지만 영어를 위해서만 설계되었다는 한계가 있었다. 다행히도 1바이트 안에 7비트가 아닌 8비트가 있었고,
128부터 255까지 이전에는 국제적인 문자로 사용되지 않았던 코드가 곧 대중화되었다. 미국에서 이러한 여분의 숫자들은 수학적 개념, 그래픽 요소들, 악센트 부호 등 추가적인 기호를 인코딩하는 데에 사용되었다.
라틴 문자는 보편적으로 사용되었고, 러시아 컴퓨터는 키릴 문자를 인코딩, 그리스 컴퓨터는 그리스 문자를 인코딩하는 등 국제적인 문자 코드들은 대부분의 국가에서 꽤나 잘 작동했다. 하지만 라틴 문자를 터키 컴퓨터로 열면 이해가 아예 불가능했고, 중국어나 일본어처럼 수천개의 문자를 사용하는 아시아에서 컴퓨팅이 떠오르면서 상황이 완전 박살남. 8비트안으로 한자를 모두 인코딩할 수는 없기 때문. 이에 따라 각각의 나라는 다양한 바이트의 인코딩 구조를 개발했고, 이들은 서로 호환이 되지 않았다. 일본어는 이 인코딩 문제를 뒤섞인 글자를 의미하는 'MOJIBAKE'라고도 불렀다.
그래서 유니코드가 탄생했다. 그들을 모두 지배하는 하나의 형식. 1992년에 제정된 이 프로젝트는 마침내 각각의 국제적인 제도를 없애고 하나의 보편적인 인코딩 구조로 대체하였다. 가장 일반적인 버전은 16비트 공간을 사용해서 백만개가 넘는 코드를 넣을 수 있음. 여태 사용되었던 모든 언어(100가지가 넘는 종류의 문자 12만개 이상+수학적 기호+이모티콘 등도 포함 가능!!)에 있는 각각의 글자를 지정하기에 충분하다. 아스키는 문자를 이진수로 인코딩하는 체계(MP3, GIF 등 다른 파일 형식들이 사용하는 체계)를 정의했음. 이진수를 사용해 음악 안에 있는 소리, 영화나 사진 안에 있는 픽셀의 색상들을 인코딩했다.
다음 시간에는 우리가 어떻게 컴퓨터가 이진 시스템을 조작하기 시작했는지 이야기한다.
