요새 LLM 모델이 정말 많이 나오고 있는데 최근에 Llama2가 완전! 오픈소스로 나왔다고 한다. Llama1에 비해 뭐가 바뀌었나.. 봤더니 실질적으로 token의 길이를 늘려 context length를 늘린 것과 parameter 갯수와 fine tuning, 미세 조정, RLHF 등등... 학습을 시키는 부분에 대해서 차이가 있을 뿐 다른 부분은 차이가 없었다. Large Language Model에서 Large에 방점이 찍힌... 느낌? 그리고 dialog, chat data에 최적화되어 있다고 한다.
Llama의 architecture
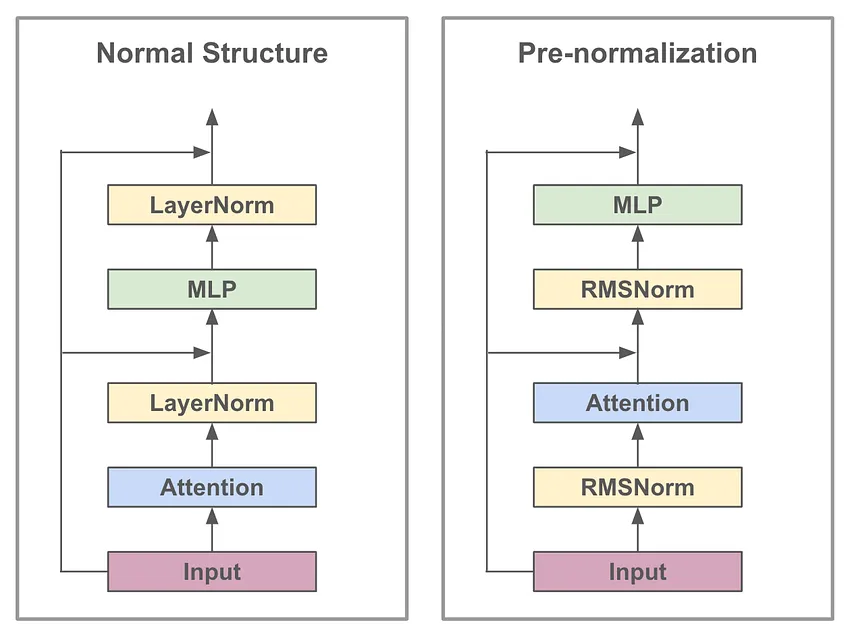
Llama2는 normal transfomer block의 pre-normalization variant를 사용한다. 많은 transformer 구조가 layer normalization을 채택하여 사용하고 있지만, Llama는 위 그림의 오른쪽과 같이 Root Mean Square Layer Normalization (RMS Norm)로 layer normalization을 대체하여 사용한다. 연산이 더 단순화된 기법이기 때문에 layer normalization에 비해 10~50% 향상된 효율성을 달성했다.
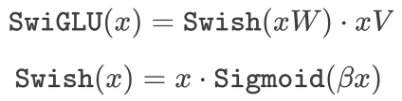
그리고 Llama는 SwiGLU라는 activation 함수를 사용하며 위와 같이 공식화될 수 있다. 3개의 행렬 곱을 사용하기 때문에 일반적으로 사용되는 ReLU에 비해 계산 비용이 더 많이 들지만, 사용 중인 계산량이 일정하게 유지되는 상황에서도 다른 activation 함수에 비해 성능이 향상되는 장점이 있다.
Llama의 특이한 점 중 하나는 positional embedding에서 절대적 혹은 상대적 위치에 대한 정보를 사용하는 대신 sequece에서 token의 절대적 위치와 상대적 위치 사이의 균형을 찾는 RoPE 기법을 사용한다. 이는 회전 행렬로 절대 위치를 encoding하고, 상대 위치 정보를 직접 self-attention 작업에 추가한다. 이는 sequence length가 더 긴 작업에 대해 이점을 가지므로 다양한 LLM에서 이를 채택하고 있다. (ex. PALM)
그래서 뭐가 바뀌었나?
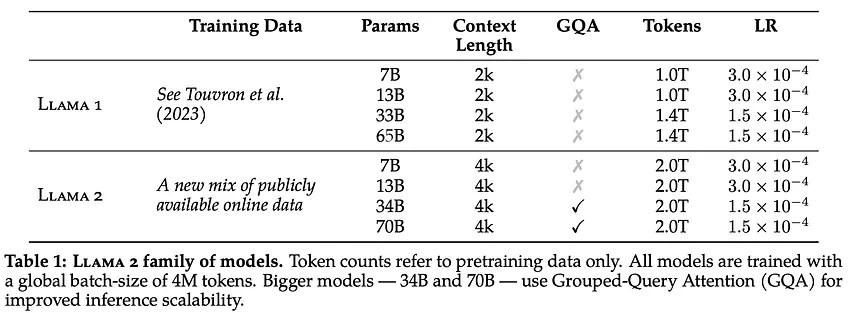
위는 Llama1과 Llama2가 무슨 차이가 있는지 간략히 표로 도식화한 것이다. 앞서 언급했듯이 Llama2는 Llama1에 대해 sequence 길이를 더 늘리고 pre-training, fine-tuning, safety 측면에서의 차이만 있기 때문에 위의 내용을 보면 크게 다른 점이 보이지 않는다. 그 외의 차이로는 Llama2가 GQA (Group Query Attention)을 채택하고 있다는 것이다.
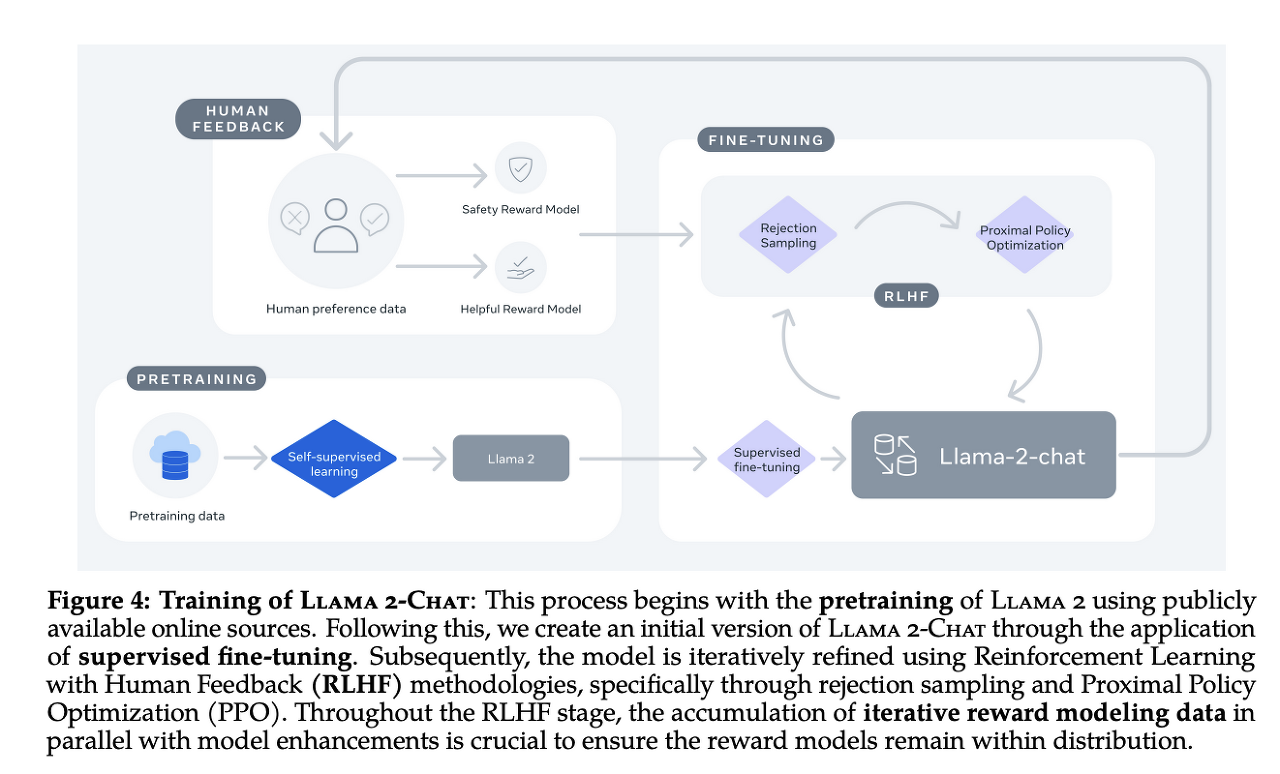
Llama2의 전체적인 코드 구조를 보면 어떤 방식과 과정을 통해 Llama2가 더 긴 sequence에 대해 context를 이해하고 대화 상황에 최적화 되었으며 성능 향상을 이뤄냈는지 대략적으로 알 수 있다.
GQA
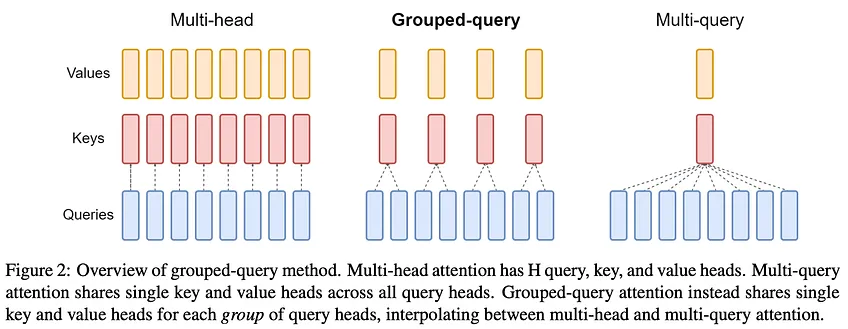
GQA란 multi-head causal self-attention 기법의 수정된 표준 기법이다. 이 링크를 통해 GQA에 대해 자세히 알 수 있다.
https://devocean.sk.com/blog/techBoardDetail.do?ID=165192&boardType=techBlog
더 많은 데이터 = 더 좋은 모델
LLM에서 흔히 통용되는 말이다. 더 많은 data를 학습하고 tuning된 모델일 수록 LLM은 더 general task를 잘 다룰 수 있으며 성능이 향상되는 모습을 보여왔다.
이 명제에 따라 Llama2가 더 우수한 성능을 도출해낸 과정을 살펴보자.
Pre-training
Llama2는 Llama1과 같이 공개된 데이터셋만을 이용해 pre-training을 했다. 이는 충분한 컴퓨팅 소스를 갖고 있는 사람들이 pre-trained process를 공개적으로 복제할 수 있도록 하기 위함이었다. 대신, Llama2는 공개된 데이터셋들을 그대로 이용하지 않고, 고품질이면서 사실로 판단된 소스들만 의도적으로 sampling하여 혼합된 데이터셋을 만들어 사용했다. 여러 데이터셋의 고품질 내용만 혼합하여 pre-training dataset을 이전보다 40% 늘렸으며, 이를 통해 Llama2는 이전에 비해 보유한 지식의 기반이 더 향상되었다.
Supervised Fine-tuning
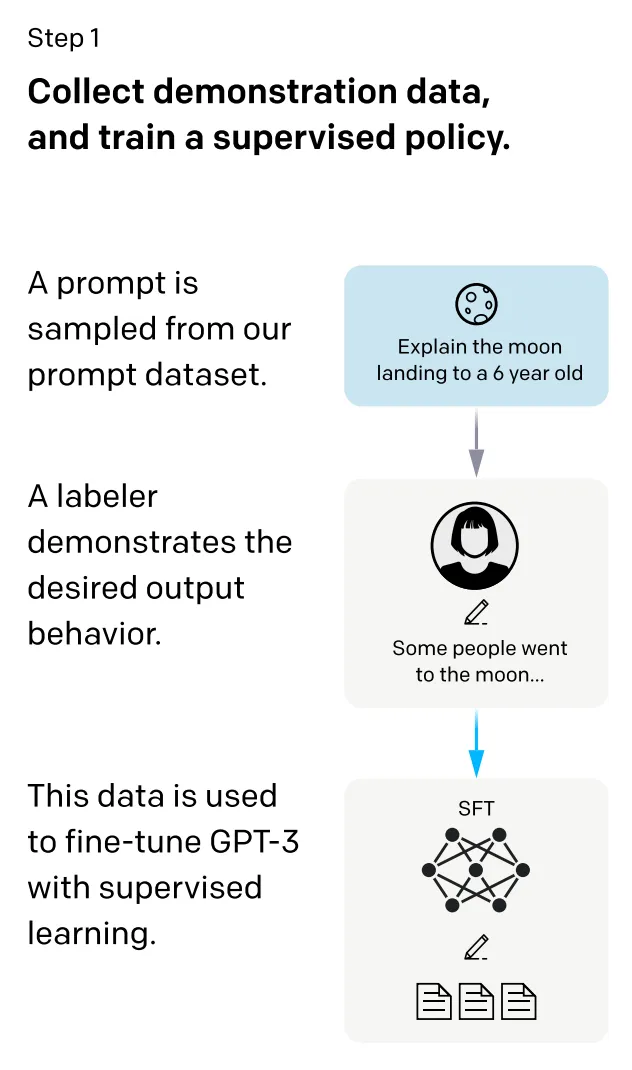
Llama2는 독점 모델(GPT-4)와 같이 광범위한 대화의 양과 인간 피드백에 의한 격차를 줄이기 위해 그와 유사한 방식으로 대규모 dataset을 사용해 fine-tuning된 Llama2-Chat을 생성한다. (가능한 완전 오픈소스를 제공하기 위해 노력하는 것의 일환이다.)
여기서 SFT의 두 단계를 수행하는데 첫 번째는 더 많은 양의 공개 데이터에 대해서 학습하는 것이고 두 번째는 훨씬 더 높은 품질로 선별된 소규모 데이터에 대해서 학습하는 것이다. 고품질 데이터셋을 위해 공개 데이터셋을 수집함에 있어서 필터링을 위해 심혈을 기울이고 있는 것으로 보인다.
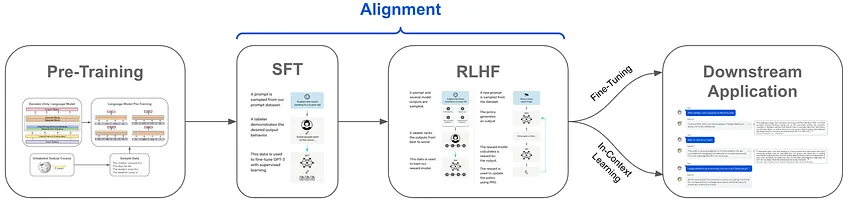
또한, Llama2 chat은 위와 같이 alignment된 training 구조를 사용하여 hallucination을 줄이고 unsafe question을 피하고자 한다. 여기서 유용성과 안정성을 위해 SFT와 RLHF를 모두 사용했다는 점에서 특이하다.
RLHF
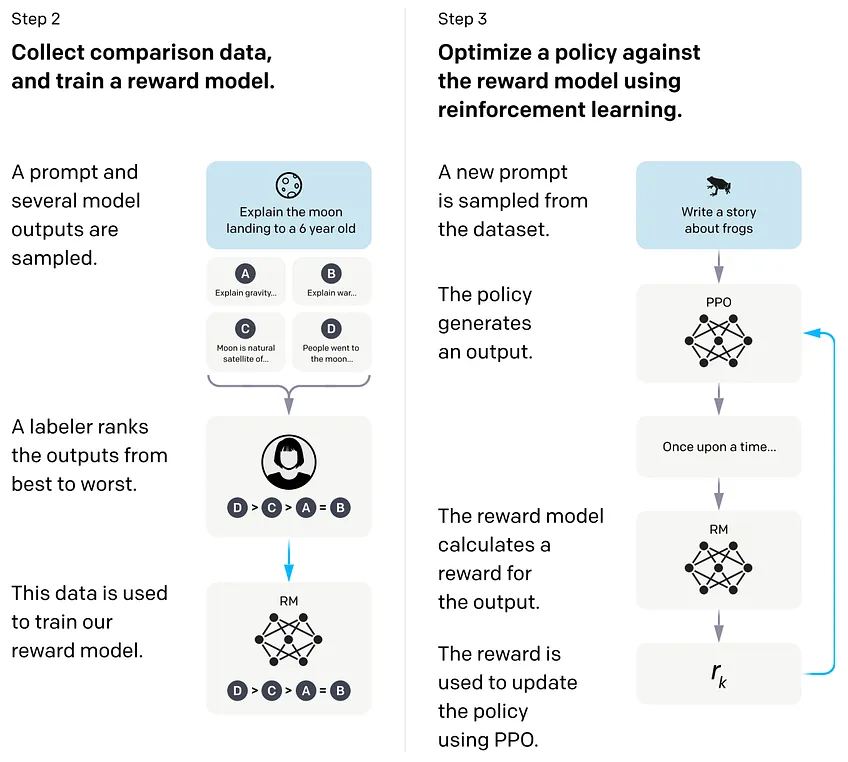
SFT는 많은 LLM에서 채택되고 있는만큼 성능이 확실하나 alignment의 목표를 정확히 포착해서 선별하고 관리함에 있어서는 부족할 수 있다. 이 때문에 직접 인간이 이에 대해 피드백을 하고 이를 품질 향상에 이용하는 것이 제시되었다. 인간이 피드백을 함으로써 그 선호도 점수에 따라 LLM을 최적화하는 것이다.
이러한 인간 피드백 방식을 통해 Risk Categories와 Attack Vector를 고려해 Chat 상황에서의 위험성을 배제하고자 한다. (safety 향상)
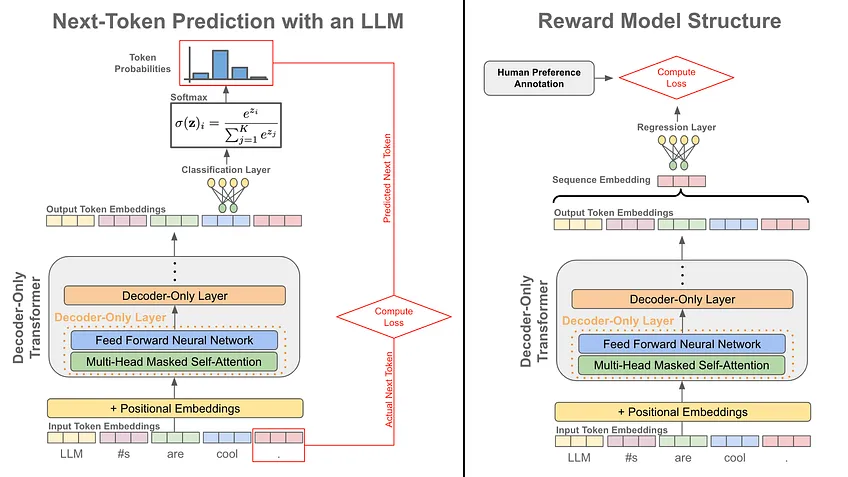
위와 같이 인간의 피드백을 수집한 다음에는 이에 대해 reward model을 훈련한다. 이 모델은 prompt-response 쌍에 대해 정확한 선호도 점수를 자동으로 얻어내며 이를 통해 RL을 사용해 LLM을 fine-tuning한다. 그에 대한 연산은 아래와 같다.

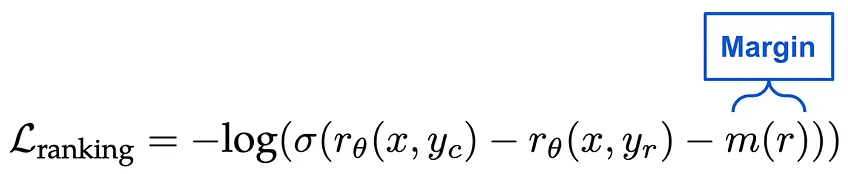
참고한 링크:
https://cameronrwolfe.substack.com/p/llama-2-from-the-ground-up
https://datacook.tistory.com/108
https://dajeblog.co.kr/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-llama2/
https://moon-walker.medium.com/chatgpt%EC%97%90-%EC%A0%81%EC%9A%A9%EB%90%9C-rlhf-%EC%9D%B8%EA%B0%84-%ED%94%BC%EB%93%9C%EB%B0%B1-%EA%B8%B0%EB%B0%98-%EA%B0%95%ED%99%94%ED%95%99%EC%8A%B5-%EC%9D%98-%EC%9B%90%EB%A6%AC-eb456c1b0a4a
