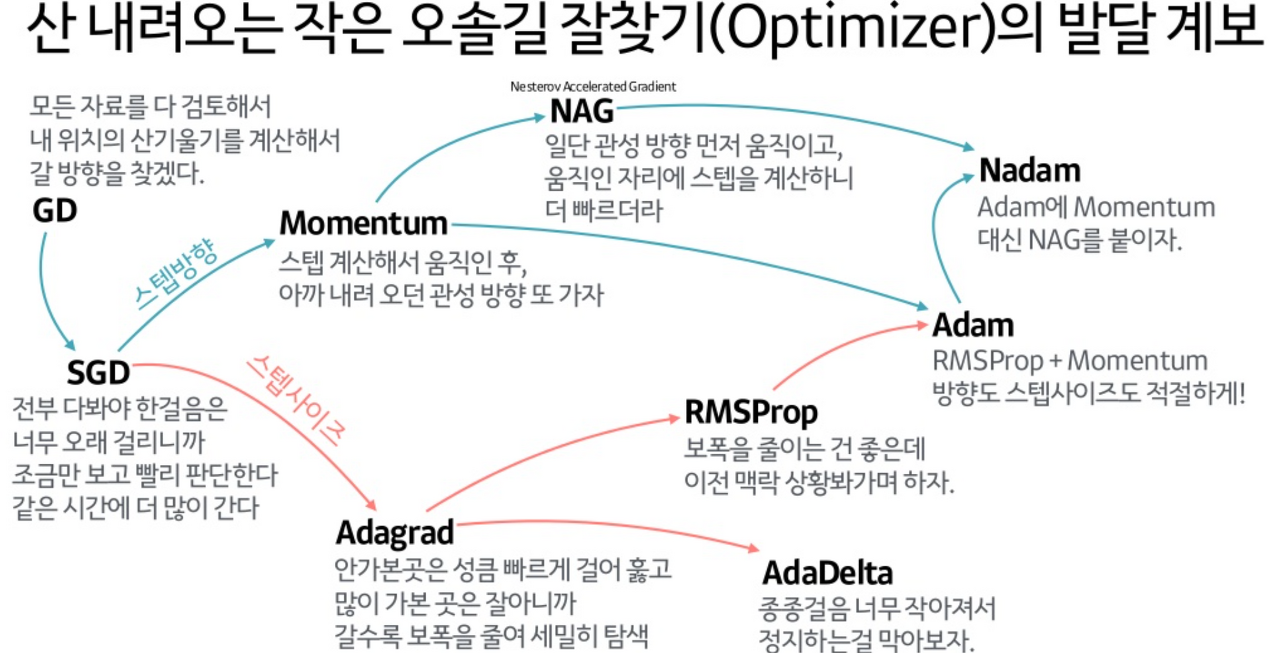
Adam... 그동안 AI 개발 프로젝트 진행하면서 자주 봤던 optimizer 중 하나이다. 주로 SGD랑 Adam 둘 중 하나를 쓰고 웬만하면 Adam이 성능이 더 좋지만... 가끔 연산량 과다로 memory가 터지면 어쩔 수 없이 SGD를 썼어야 했다.
둘다 Stochastic objective function에 대한 first-order gradient-based optimization 기법이라는 점에서 공통점이 있다. Adam과 SGD의 가장 큰 차이는 SGD는 gradient descent에서 step size를 조절하는 역할을 한다면, Adam은 step size 뿐만 아니라 descent direction까지 조절한다는 점이다. (step size는 gradient 1차 미분 값이고 , direction은 gradient 2차 미분 값이다.)
Main Algorithm

Adam은 기본적으로 Stochastic optimization이다. stochastic optimization이란 확률적인 연산에 의존해 최적화를 이루는 것을 의미하며 gradient를 얼마나 어느 방향으로 줄여나가느냐에 따라 local minima가 될지, global minima가 될지 모르는 상황에서 검색 공간을 탐색하거나 이미 탐색한 것을 활용하면서 균형을 맞춰나가는 알고리즘이다.
위 알고리즘에서 필요로 하는 매개변수
- Step size α
- Decay rates β1, β2 (Exponential decay rates for the moment extimates (0~1)) -> hyper parameter
- Stochastic Objective Function f(θ), θ: parameters (weight) <- f(θ)의 최소화가 Adam의 목표
- initial parameter vector θ0
알고리즘
- 1st, 2nd moment vector <- 초기화 / time step <- 초기화
- parameter θt가 더 이상 수렴하지 않을 때까지 아래 내용을 반복
- 1) time step += 1
- 2) stochastic objective function으로 이전 time step의 gradient 계산 (미분)
- 3) biased 1st, 2nd moment 값 계산
- 4) 초기 momentum 값이 0이 되지 않도록 bias-correction 적용
- 5) weight update
- 최종 weight return
위 과정에서 1st momentum과 2nd momentum은 각각 AdaGrad, RMSProp의 역할을 하여 weight update 횟수에 따라 learning rate(step size)를 다르게 한다. (update를 많이 한 weight일 수록 v_t값이 커짐.)
More details
Update rule
step size를 효과적으로 선택하는 것이 중요하며 2개의 upper bound가 있음.
1st case: sparsity case -> 하나의 gradient가 모든 time step에서 0이 되는 경우에는 step size를 크게 해서 update 변화량을 크게 만든다.
2nd case: 일반적인 update 상황에서는 보통 β1=0.9, β2=0.99로 설정해서 적용하고 step size를 작게 해서 update 변화량을 작게 한다.
Initialization bias correction
각 moment를 (1-b)로 나누는 이유는 E[v_t](2nd moment의 기댓값)가 E[g_t](실제로 구해야 하는 2nd moment 값)에 근사하게 하기 위해서 이다. 여기서 b에 time step 제곱을 하는 건 다음 step으로 가면서는 계산된 momentum 값을 살리기 위해서로 보임....아마두?
Results
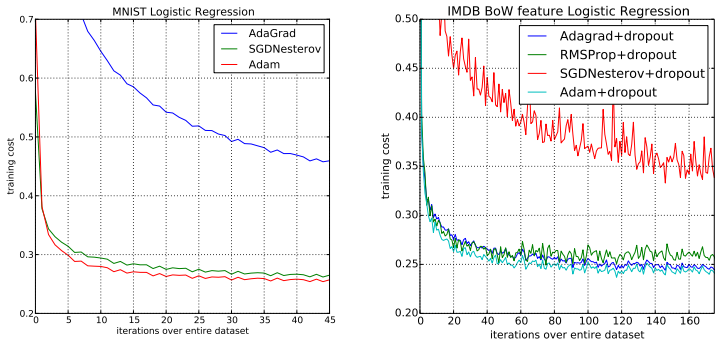
MNIST 데이터셋을 사용해서 logistic regression 모델에 여러 optimizer를 적용해 테스트한 결과 성능 측면에서 Adam이 우수한 것을 볼 수 있다.
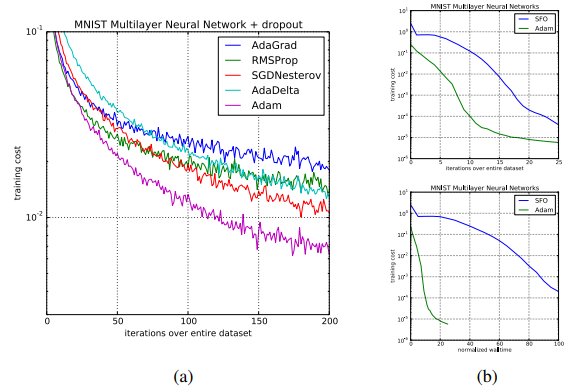
MNIST 데이터셋을 사용해 Neural Network를 사용한 경우에도 Adam의 성능이 제일 좋게 나타난다.
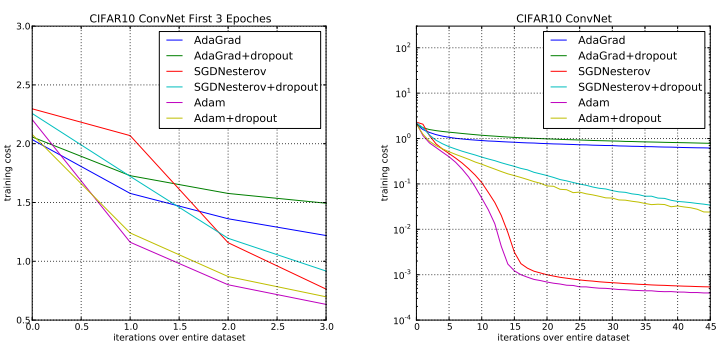
CIFAR-10 데이터셋을 사용해 CNN 모델과 여러 optimizer를 적용한 테스트에서도 Adam의 성능이 우수했다.
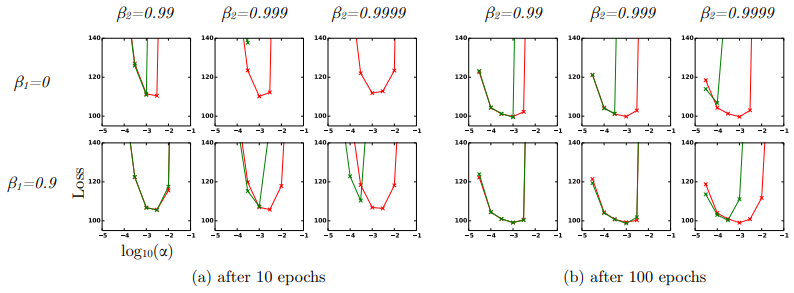
위는 bias correction에서 β1, β2의 값을 몇으로 둘 때가 성능이 좋았는지 비교한 것인데 위에서 언급한 것과 같이 일반적으로 0.9, 0.99로 두는 것이 가장 좋다.
