Intro
캐글에서 다른 캐글러가 공유한 흉부 엑스선 이미지 데이터셋으로 딥러닝 모델링을 연습해보았다.
흉부 엑스선 이미지를 보고 폐렴을 진단하는 모델을 만드는 것으로, 정상인의 엑스선인지 폐렴 환자의 엑스선인지 판별하는 이중분류 문제이다.
경진대회가 아니라 정해진 평가지표도 없고 제출도 없으니 임의로 평가지표를 정해 모델링을 연습해보도록 한다.
EDA
데이터 둘러보기
-
csv파일이 아니라 다른 방식으로 데이터를 불러온다.
# 데이터 경로 data_path = '/kaggle/input/chest-xray-pneumonia/chest_xray/' # 훈련, 검증, 테스트 데이터 경로 설정 train_path = data_path + 'train/' valid_path = data_path + 'val/' test_path = data_path + 'test/' -
훈련, 검증, 테스트 데이터가 각각 몇개 있는지 확인해본다.
from glob import glob print(f'훈련 데이터 개수 : {len(glob(train_path + "*/*"))}') print(f'검증 데이터 개수 : {len(glob(valid_path + "*/*"))}') print(f'테스트 데이터 개수 : {len(glob(test_path + "*/*"))}')
-
glob 모듈을 통해 지정한 형식과 일치하는 경로를 모두 찾는다. "*/*"은 모든 디렉터리 및 파일을 의미 한다.
-
검증 데이터는 16개로 개수가 적어 신뢰성이 떨어진다.
-
-
타깃값별 개수를 구해 정상 이미지, 폐렴 이미지의 개수를 알아본다.
all_normal_imgs = [] # 모든 정상 이미지를 담을 리스트 초기화 all_pneumonia_imgs = [] # 모든 폐렴 이미지를 담을 리스트 초기화 for cat in ['train/', 'val/', 'test/']: data_cat_path = data_path + cat # 정상, 폐렴 이미지 경로 normal_imgs = glob(data_cat_path + 'NORMAL/*') pneumonia_imgs = glob(data_cat_path + 'PNEUMONIA/*') # 정상, 폐렴 이미지 경로를 리스트에 추가 all_normal_imgs.extend(normal_imgs) all_pneumonia_imgs.extend(pneumonia_imgs) print(f'정상 흉부 이미지 개수 : {len(all_normal_imgs)}') print(f'폐렴 흉부 이미지 개수 : {len(all_pneumonia_imgs)}')
코드를 입력하세요-
타깃값의 비율이 어떻게 되는지 파이그래프로 알아본다.
import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline mpl.rc('font', size=15) plt.figure(figsize=(7, 7)) label = ['Normal', 'Pneumonia'] # 타깃값 레이블 # 타깃값 분포 파이 그래프 plt.pie([len(all_normal_imgs), len(all_pneumonia_imgs)], labels=label, autopct='%.1f%%');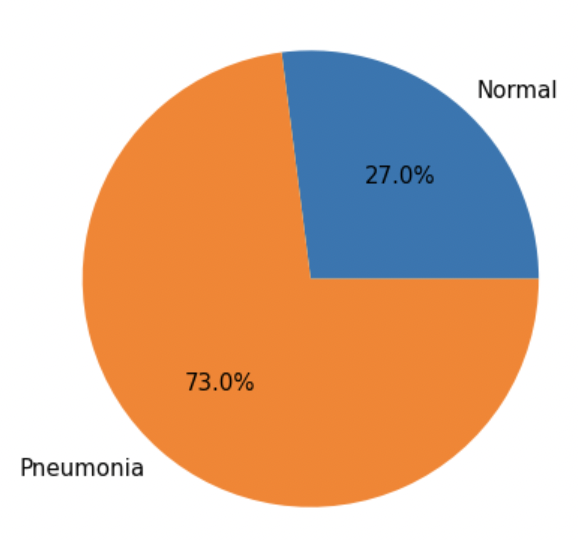
- 정상 이미지 27%, 폐렴 이미지 73%의 분포를 갖는다.
-
이미지의 경로를 이용해 이미지를 출력해본다.
import matplotlib.gridspec as gridspec import cv2 def show_image(img_paths, rows=2, cols=3): assert len(img_paths) <= rows*cols # 이미지가 행/열 개수보다 많으면 오류 발생 mpl.rc('font', size=8) plt.figure(figsize=(15, 8)) grid = gridspec.GridSpec(rows, cols) # 서브플롯 배치 # 이미지 출력 for idx, img_path in enumerate(img_paths): image = cv2.imread(img_path) # 이미지 파일 읽기 ax = plt.subplot(grid[idx]) ax.imshow(image) # 이미지 출력# 정상 엑스선 이미지 경로(마지막 6장) num_of_imgs = 6 normal_img_paths = all_normal_imgs[-num_of_imgs:] # 이미지 출력 show_image(normal_img_paths)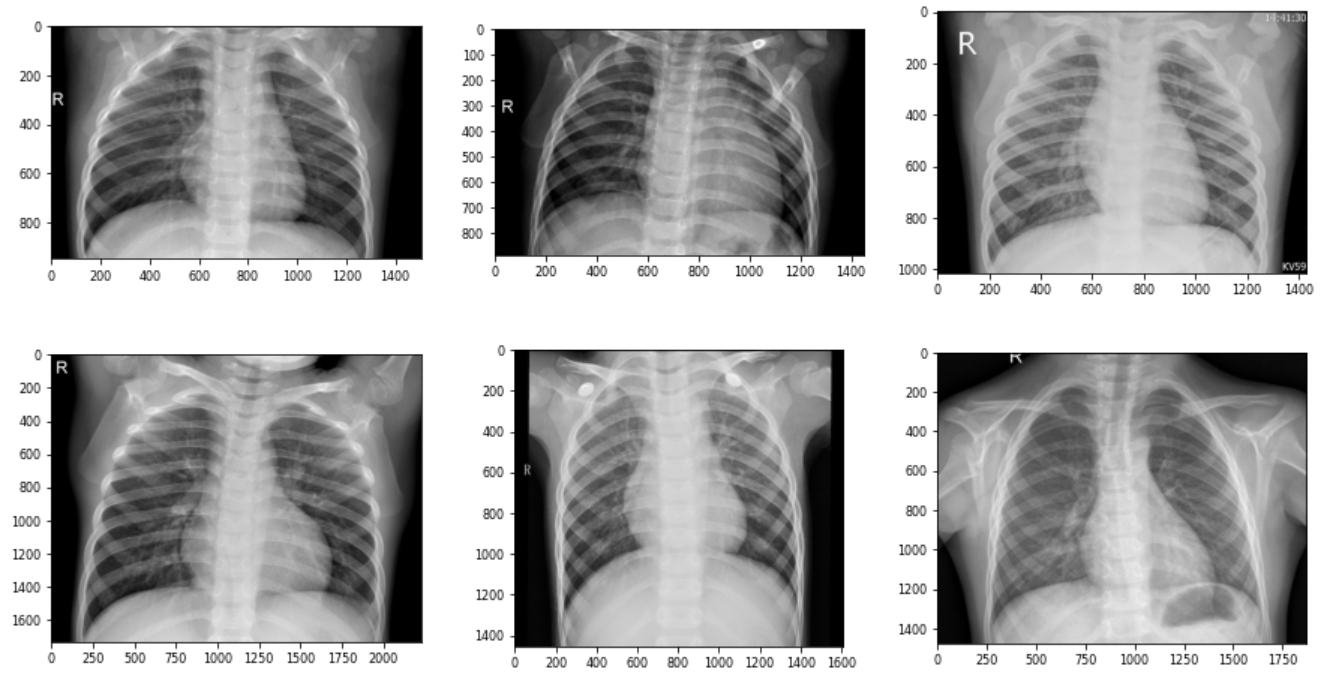
# 폐렴 엑스선 이미지 경로(마지막 6장) pneumonia_img_paths = all_pneumonia_imgs[-num_of_imgs:] # 이미지 출력 show_image(pneumonia_img_paths)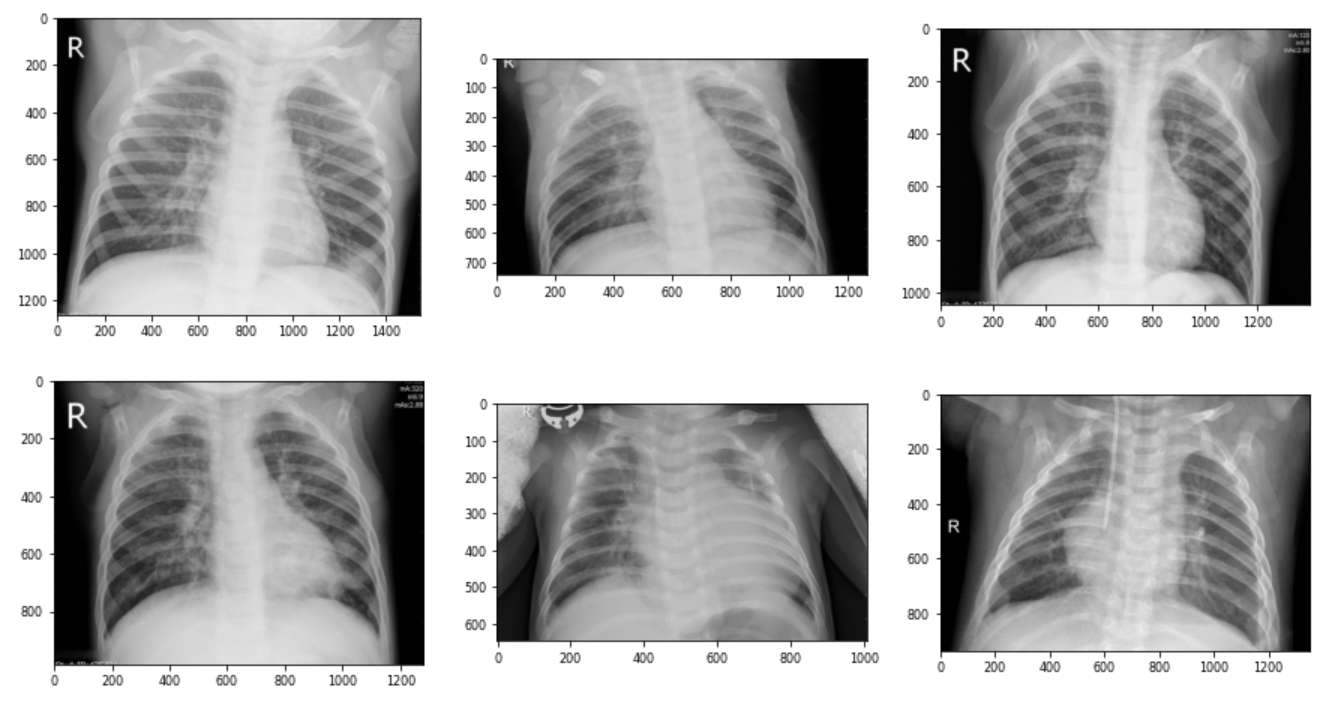
- 이미지 크기가 제각각이라 나중에 변환기를 통해 이미지 크기를 일치시켜주도록 한다.
Baseline Model
-
시드값을 고정하고 GPU 장비를 설정한다.
import torch # 파이토치 import random import numpy as np import os # 시드값 고정 seed = 50 os.environ['PYTHONHASHSEED'] = str(seed) random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False torch.backends.cudnn.enabled = Falsedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu') -
데이터를 불러올 때는 데이터 경로를 설정한다.
# 데이터 경로 data_path = '/kaggle/input/chest-xray-pneumonia/chest_xray/' # 훈련, 검증, 테스트 데이터 경로 설정 train_path = data_path + 'train/' valid_path = data_path + 'val/' test_path = data_path + 'test/' -
훈련, 검증데이터가 이미 분리되어 제공되기에 분리하는 단계를 생략하고, 데이터셋 클래스를 직접 정의하지 않고 ImageFolder라는 데이터셋 생성기를 사용해 생성한다.
-
그에 앞서 데이터 증강을 위한 이미지 변환기를 만들어준다.
from torchvision import transforms # 훈련 데이터용 변환기 transform_train = transforms.Compose([ transforms.Resize((250, 250)), # 이미지 크기 조정 transforms.CenterCrop(180), # 중앙 이미지 확대 transforms.RandomHorizontalFlip(0.5), # 좌우 대칭 transforms.RandomVerticalFlip(0.2), # 상하 대칭 transforms.RandomRotation(20), # 이미지 회전 transforms.ToTensor(), # 텐서 객체로 변환 transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]) # 정규화 # 테스트 데이터용 변환기 transform_test = transforms.Compose([ transforms.Resize((250, 250)), transforms.CenterCrop(180), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])- 훈련 데이터용 변환기와 테스트 데이터용 변환기를 만들어주고, Resize()로 이미지 크기를 일정하게 조정해주었다.
-
타깃값이 같은 이미지끼리 디렉터리로 구분되어 있으면 ImageFolder 클래스로 데이터셋을 만들 수 있다.
from torchvision.datasets import ImageFolder # 훈련 데이터셋 datasets_train = ImageFolder(root=train_path, transform=transform_train) # 검증 데이터셋 datasets_valid = ImageFolder(root=valid_path, transform=transform_test)-
ImageFolder()는 root 파라미터의 경로에 있는 이미지들로 바로 데이터셋을 만든다. transform 파라미터에는 데이터셋을 만들 때 적용할 이미지 변환기를 전달한다.
-
타깃값이 같은 데이터들이 같은 디렉터리에 모여있을 때만 이 ImageFolder()를 사용할 수 있다.
-
-
멀티프로세싱을 사용하기 위해 데이터 로더의 시드값을 고정한다.
def seed_worker(worker_id): worker_seed = torch.initial_seed() % 2**32 np.random.seed(worker_seed) random.seed(worker_seed) # 제너레이터 시드값 고정 g = torch.Generator() g.manual_seed(0) -
데이터 로더를 만들어주는데, 배치 크기는 8로 설정해준다.
from torch.utils.data import DataLoader batch_size = 8 loader_train = DataLoader(dataset=datasets_train, batch_size=batch_size, shuffle=True, worker_init_fn=seed_worker, generator=g, num_workers=2) loader_valid = DataLoader(dataset=datasets_valid, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g, num_workers=2) -
EfficientNet을 불러오고 device 장비에 할당한다.
from efficientnet_pytorch import EfficientNet # 모델 생성 model = EfficientNet.from_pretrained('efficientnet-b0', num_classes=2) # 장비 할당 model = model.to(device)
-
가장 간단한 efficientnet-b0을 사용하고, 이진분류 문제이므로 num_classes=2로 설정한다.
-
Tensor 객체가 갖는 구성요소의 총 개수를 구하는 numle()을 통해 모델의 파라미터 개수를 구해본다.
print('모델 파라미터 개수 :', sum(param.numel() for param in model.parameters()))
- 파라미터는 약 4백만개로 매우 많은 편이라 복잡한 모델이고, 훈련 시간이 오래 걸린다.
-
-
손실 함수 CrossEntropyLoss와 옵티마이저 Adam을 설정해준다.
import torch.nn as nn criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01) -
나중에도 사용하기 위해 훈련 함수를 만들어 준다. 애폭 수만큼 훈련과 검증을 반복하며 최적 모델 가중치를 찾아 반환하는 구조로 만든다.
from sklearn.metrics import accuracy_score # 정확도 계산 함수 from sklearn.metrics import recall_score # 재현율 계산 함수 from sklearn.metrics import f1_score # F1 점수 계산 함수 from tqdm.notebook import tqdm # 진행률 표시 막대 def train(model, loader_train, loader_valid, criterion, optimizer, scheduler=None, epochs=10, save_file='model_state_dict.pth'): valid_loss_min = np.inf # 최소 손실값 초기화 (검증 데이터용) # 총 에폭만큼 반복 for epoch in range(epochs): print(f'에폭 [{epoch+1}/{epochs}] \n-----------------------------') # == [ 훈련 ] ============================================== model.train() # 모델을 훈련 상태로 설정 epoch_train_loss = 0 # 에폭별 손실값 초기화 (훈련 데이터용) # '반복 횟수'만큼 반복 for images, labels in tqdm(loader_train): # 이미지, 레이블(타깃값) 데이터 미니배치를 장비에 할당 images = images.to(device) labels = labels.to(device) # 옵티마이저 내 기울기 초기화 optimizer.zero_grad() # 순전파 : 이미지 데이터를 신경망 모델의 입력값으로 사용해 출력값 계산 outputs = model(images) # 손실 함수를 활용해 outputs와 labels의 손실값 계산 loss = criterion(outputs, labels) # 현재 배치에서의 손실 추가 (훈련 데이터용) epoch_train_loss += loss.item() loss.backward() # 역전파 수행 optimizer.step() # 가중치 갱신 if scheduler != None: # 스케줄러 학습률 갱신 scheduler.step() # 훈련 데이터 손실값 출력 print(f'\t훈련 데이터 손실값 : {epoch_train_loss/len(loader_train):.4f}') # == [ 검증 ] ============================================== model.eval() # 모델을 평가 상태로 설정 epoch_valid_loss = 0 # 에폭별 손실값 초기화 (검증 데이터용) preds_list = [] # 예측값 저장용 리스트 초기화 true_list = [] # 실젯값 저장용 리스트 초기화 with torch.no_grad(): # 기울기 계산 비활성화 for images, labels in loader_valid: images = images.to(device) labels = labels.to(device) outputs = model(images) loss = criterion(outputs, labels) epoch_valid_loss += loss.item() # 예측값 및 실제값 preds = torch.max(outputs.cpu(), dim=1)[1].numpy() true = labels.cpu().numpy() preds_list.extend(preds) true_list.extend(true) # 정확도, 재현율, F1 점수 계산 val_accuracy = accuracy_score(true_list, preds_list) val_recall = recall_score(true_list, preds_list) val_f1_score = f1_score(true_list, preds_list) # 검증 데이터 손실값 및 정확도, 재현율, F1점수 출력 print(f'\t검증 데이터 손실값 : {epoch_valid_loss/len(loader_valid):.4f}') print(f'\t정확도 : {val_accuracy:.4f} / 재현율 : {val_recall:.4f} / F1 점수 : {val_f1_score:.4f}') # == [ 최적 모델 가중치 찾기 ] ============================== # 현 에폭에서의 손실값이 최소 손실값 이하면 모델 가중치 저장 if epoch_valid_loss <= valid_loss_min: print(f'\t### 검증 데이터 손실값 감소 ({valid_loss_min:.4f} --> {epoch_valid_loss:.4f}). 모델 저장') # 모델 가중치를 파일로 저장 torch.save(model.state_dict(), save_file) valid_loss_min = epoch_valid_loss # 최소 손실값 갱신 return torch.load(save_file) # 저장한 모델 가중치를 불러와 반환-
에폭별로 검증 데이터 손실값을 구할 땐 에폭마다 최소 손실값이 나오면 최소 손실값을 갱신하고 모델 가중치를 저장한다.
-
예측값과 실제값을 저장하는 부분에서 예측값 preds를 구할 때, 평가지표로 정확도, 재현율, F1점수를 이용할 것이므로 이산값(0또는 1)로 바꾸어 구해준다. 최댓값을 구하는 torch.max()로 예측 확률을 이산값으로 바꿔준다.
-
최적 모델 가중치를 찾는 부분에서, 현재 에폭의 손실값이 최소 손실값 이하면 모델 가중치를 저장하고 기존 최소 손실값을 현재 에폭의 손실값으로 갱신한다. torch.save()의 파라미터 model.state_dict()는 모델 가중치를 뜻하고, save_file()은 저장하려는 파일명이다. 모든 훈련과 검증을 마치면 저장한 파일을 읽어와 반환한다. train()함수의 반환값은 save_file에 저장된 모델 가중치로, 전체 에폭에서 가장 검증 데이터 손실값이 작은 모델 가중치를 반환하는 것이다.
-
-
만든 train()함수로 모델을 훈련하고 손실값, 정확도, 재현율, F1 점수를 출력해본다.
# 모델 훈련 model_state_dict = train(model=model, loader_train=loader_train, loader_valid=loader_valid, criterion=criterion, optimizer=optimizer)
- 9번째 에폭에서 검증 데이터 손실값이 가장 작아 이때의 모델 가중치가 최적 모델 가중치이다. 이 최적 모델 가중치는 model_state_dict에 저장되어 있고, 이 가중치로 모델의 가중치를 갱신한다.
# 최적 가중치 불러오기 model.load_state_dict(model_state_dict)
- 9번째 에폭에서 검증 데이터 손실값이 가장 작아 이때의 모델 가중치가 최적 모델 가중치이다. 이 최적 모델 가중치는 model_state_dict에 저장되어 있고, 이 가중치로 모델의 가중치를 갱신한다.
-
이제 테스트 데이터로 결과를 예측하고 실젯값과 비교한다. 먼저 테스트 데이터셋과 데이터 로더를 생성한다.
datasets_test = ImageFolder(root=test_path, transform=transform_test) loader_test = DataLoader(dataset=datasets_test, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g, num_workers=2) -
테스트 데이터로 결과를 에측하는 predict()함수를 만들어준다. 모델과 테스트 데이터 로더를 파라미터로 전달받아 예측값을 반환하는 구조이다. 세번째 파라미터 return_true에서 값이 True면 실젯값과 에측값을 같이 반환하고 False면 에측값만 반환한다.
def predict(model, loader_test, return_true=False): model.eval() # 모델을 평가 상태로 설정 preds_list = [] # 예측값 저장용 리스트 초기화 true_list = [] # 실제값 저장용 리스트 초기화 with torch.no_grad(): # 기울기 계산 비활성 for images, labels in loader_test: images = images.to(device) labels = labels.to(device) outputs = model(images) preds = torch.max(outputs.cpu(), dim=1)[1].numpy() # 예측값 true = labels.cpu().numpy() # 실제값 preds_list.extend(preds) true_list.extend(true) if return_true: return true_list, preds_list else: return preds_list- predict()함수를 사용해 예측값을 구한다. true_list에 실젯값, preds_list에 예측값을 저장했다.
true_list, preds_list = predict(model=model, loader_test=loader_test, return_true=True)
- predict()함수를 사용해 예측값을 구한다. true_list에 실젯값, preds_list에 예측값을 저장했다.
-
실젯값과 예측값을 이용해 정확도, 재현율, F1 점수를 출력해 최종 점수를 살펴본다.

성능 개선
-
모델 3개(EfficientNet-B1, EfficientNet-B2, EfficientNet-B3)를 앙상블해 성능을 개선하도록한다. 모델 파라미터가 많을수록 복잡한 이미지를 더 잘 구분하고 성능이 좋지만 단순한 이미지를 구분하는데 쓰면 오히려 오버피팅으로 평가 점수가 떨어질 수 있으니 적당한 B1, B2, B3모델을 사용한다. 모델을 각각 훈련한 뒤 각 모델이 예측한 결과를 앙상블하도록 한다.
-
3개의 모델을 다루기 편하게 모델들을 저장할 리스트를 만든다.
models_list =[] # 모델 저장용 리스트 -
EfficientNet-B1, EfficientNet-B2, EfficientNet-B3를 생성하고 장비에 할당한 뒤 리스트에 저장한다.
from efficientnet_pytorch import EfficientNet # 모델 생성 efficientnet_b1 = EfficientNet.from_pretrained('efficientnet-b1', num_classes=2) efficientnet_b2 = EfficientNet.from_pretrained('efficientnet-b2', num_classes=2) efficientnet_b3 = EfficientNet.from_pretrained('efficientnet-b3', num_classes=2) # 장비 할당 efficientnet_b1 = efficientnet_b1.to(device) efficientnet_b2 = efficientnet_b2.to(device) efficientnet_b3 = efficientnet_b3.to(device) # 리스트에 모델 저장 models_list.append(efficientnet_b1) models_list.append(efficientnet_b2) models_list.append(efficientnet_b3) -
생성한 각 모델의 파라미터 개수를 출력해본다.
for idx, model in enumerate(models_list): num_parmas = sum(param.numel() for param in model.parameters()) print(f'모델{idx+1} 파라미터 개수 : {num_parmas}')
-
손실 함수 CrossEntropyLoss를 설정하고 옵티마이저 AdamW를 모델 각각에 설정해준다.
import torch.nn as nn criterion = nn.CrossEntropyLoss()optimizer1 = torch.optim.AdamW(models_list[0].parameters(), lr=0.0006, weight_decay=0.001) optimizer2 = torch.optim.AdamW(models_list[1].parameters(), lr=0.0006, weight_decay=0.001) optimizer3 = torch.optim.AdamW(models_list[2].parameters(), lr=0.0006, weight_decay=0.001) -
get_cosine_schedul_with_warmup()을 사용해 스케줄러를 설정해준다. 앞서 설정한 옵티마이저를 전달하고 에폭을 20으로 늘린다.
from transformers import get_cosine_schedule_with_warmup epochs = 20 # 총 에폭 # 스케줄러 scheduler1 = get_cosine_schedule_with_warmup(optimizer1, num_warmup_steps=len(loader_train)*3, num_training_steps=len(loader_train)*epochs) scheduler2 = get_cosine_schedule_with_warmup(optimizer2, num_warmup_steps=len(loader_train)*3, num_training_steps=len(loader_train)*epochs) scheduler3 = get_cosine_schedule_with_warmup(optimizer3, num_warmup_steps=len(loader_train)*3, num_training_steps=len(loader_train)*epochs) -
Baseline model에서 정의한 train()함수를 이용해 세 모델을 순차적으로 훈련시켜준다.
# 첫 번째 모델 훈련 model_state_dict = train(model=models_list[0], loader_train=loader_train, loader_valid=loader_valid, criterion=criterion, optimizer=optimizer1, scheduler=scheduler1, epochs=epochs) # 첫 번째 모델에 최적 가중치 적용 models_list[0].load_state_dict(model_state_dict)# 두 번째 모델 훈련 model_state_dict = train(model=models_list[1], loader_train=loader_train, loader_valid=loader_valid, criterion=criterion, optimizer=optimizer2, scheduler=scheduler2, epochs=epochs) # 두 번째 모델에 최적 가중치 적용 models_list[1].load_state_dict(model_state_dict)# 세 번째 모델 훈련 model_state_dict = train(model=models_list[2], loader_train=loader_train, loader_valid=loader_valid, criterion=criterion, optimizer=optimizer3, scheduler=scheduler3, epochs=epochs) # 세 번째 모델에 최적 가중치 적용 models_list[2].load_state_dict(model_state_dict)- model_list, optimizer, scheduler 파라미터에 각각 모델에 맞는 인수를 전달한다. model_list에는 최적 가중치로 갱신된 모델들이 저장된다.
-
훈련을 마친 세 모델로 각각 예측을 하고 결과를 앙상블하기 위해 먼저 테스트 데이터셋과 데이터 로더를 생성한다.
datasets_test = ImageFolder(root=test_path, transform=transform_test) loader_test = DataLoader(dataset=datasets_test, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g, num_workers=2) -
Baseline에서 정의했던 predict()함수를 가져와 모델 3개에 각각 예측을 수행해준다.
true_list, preds_list1 = predict(model=models_list[0], loader_test=loader_test, return_true=True)preds_list2 = predict(model=models_list[1], loader_test=loader_test)preds_list3 = predict(model=models_list[2], loader_test=loader_test)-
실젯값이 있어야 평가점수를 산출할 수 있기에 첫 번째 모델에서 실젯값과 예측값을 모두 반환해준다.
-
실젯값 true_list와 세 모델로 예측한 값 preds_list1, preds_list2, preds_list3을 구했고, 모델별 평가 점수를 출력해본다.
print('#'*5, 'efficientnet-b1 모델 예측 결과 평가 점수', '#'*5) print(f'정확도 : {accuracy_score(true_list, preds_list1):.4f}') print(f'재현율 : {recall_score(true_list, preds_list1):.4f}') print(f'F1 점수 : {f1_score(true_list, preds_list1):.4f}')
print('#'*5, 'efficientnet-b2 모델 예측 결과 평가 점수', '#'*5) print(f'정확도 : {accuracy_score(true_list, preds_list2):.4f}') print(f'재현율 : {recall_score(true_list, preds_list2):.4f}') print(f'F1 점수 : {f1_score(true_list, preds_list2):.4f}')
print('#'*5, 'efficientnet-b3 모델 예측 결과 평가 점수', '#'*5) print(f'정확도 : {accuracy_score(true_list, preds_list3):.4f}') print(f'재현율 : {recall_score(true_list, preds_list3):.4f}') print(f'F1 점수 : {f1_score(true_list, preds_list3):.4f}')
- B1~B3 모델은 Baseline 모델인 B0 모델보단 점수가 높지만 숫자가 높다고 반드시 점수가 높은 것만은 아니다.
-
-
성능을 향상시키기 위해 세 모델의 예측값을 앙상블해준다. 세 예측값을 모두 합친 뒤 3으로 나누고 반올림해준다.
ensemble_preds = [] for i in range(len(preds_list1)): pred_element = np.round((preds_list1[i] + preds_list2[i] + preds_list3[i])/3) ensemble_preds.append(pred_element) -
실젯값과 앙상블 예측 결과를 비교해 최종 평가 점수를 구해본다.
print('#'*5, '최종 앙상블 결과 평가 점수', '#'*5) print(f'정확도 : {accuracy_score(true_list, ensemble_preds):.4f}') print(f'재현율 : {recall_score(true_list, ensemble_preds):.4f}') print(f'F1 점수 : {f1_score(true_list, ensemble_preds):.4f}')
- 개별 모델보다 높은 점수를 얻을 수 있다.
최종
-
경진대회가 아니라 데이터셋 영역에서 데이터셋을 받아 모델링을 연습할 수 있었는데, 훈련 단계와 예측 단계의 함수를 미리 만들어 두어 여러 모델에 적용할 수 있었다.
-
github에 해당 코드를 올려두었다.
참고: 머신러닝·딥러닝 문제해결 전략 (캐글 수상작 리팩터링으로 배우는 문제해결 프로세스와 전략)
