Intro
캐글의 병든 잎사귀 식별 경진대회 'Plant Pathology 2020 - FGVC7' compeition에 참가해 여러 딥러닝 모델 성능 향상 기법을 연습해보았다.
여러 잎사귀 사진을 보고, 딥러닝 모델을 활용해 잎사귀가 어떤 질병에 걸렸는지 식별하는 다중분류 문제이다.
잎사귀가 특정 타깃값일 확률을 예측하면 된다.
EDA
-
데이터 둘러보기
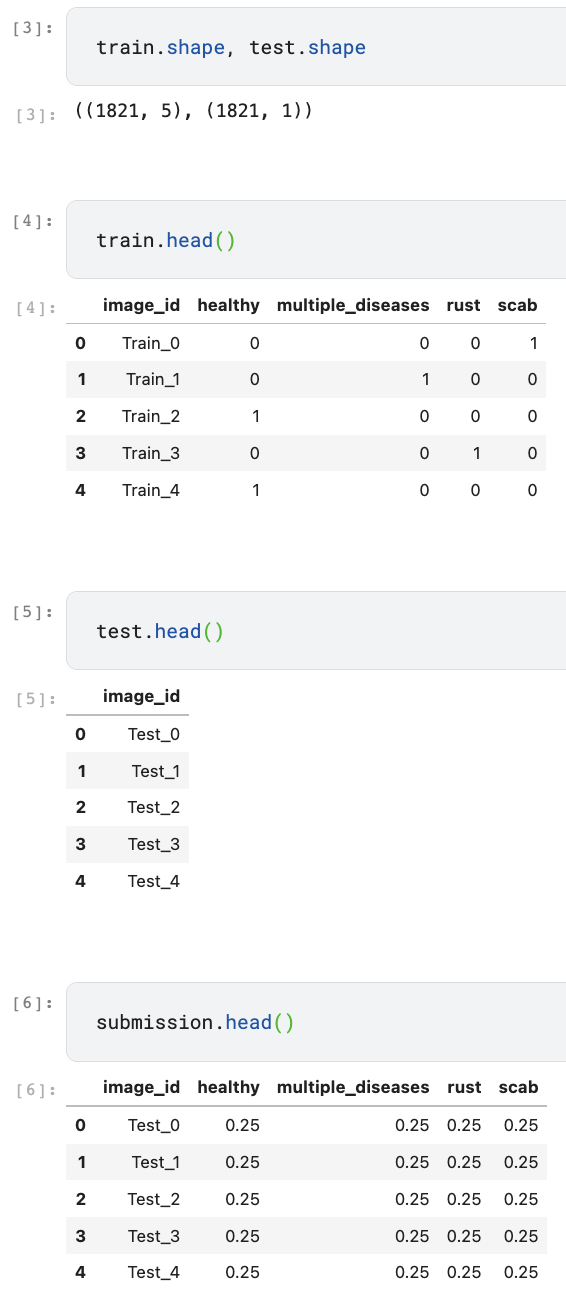
- train, test, submission data를 살펴보면, training, test data의 개수가 같은걸 알 수 있고, training data는 원-핫 인코딩 형식으로 되어있음을 알 수 있다.
-
데이터 시각화
-
데이터를 타깃값별로 나눠 각 타깃값에 해당하는 데이터가 몇개인지 그래프로 살펴본다.
# 데이터를 타깃값별로 추출 healthy = train.loc[train['healthy']==1] multiple_diseases = train.loc[train['multiple_diseases']==1] rust = train.loc[train['rust']==1] scab = train.loc[train['scab']==1]- healthy, multiple_diseases, rust, scab 변수에 각 타깃값의 데이터를 할당했으니 파이그래프로 살펴보도록 한다.
import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline mpl.rc('font', size=15) plt.figure(figsize=(7, 7)) label = ['healthy', 'multiple diseases', 'rust', 'scab'] # 타깃값 레이블 # 타깃값 분포 파이 그래프 plt.pie([len(healthy), len(multiple_diseases), len(rust), len(scab)], labels=label, autopct='%.1f%%');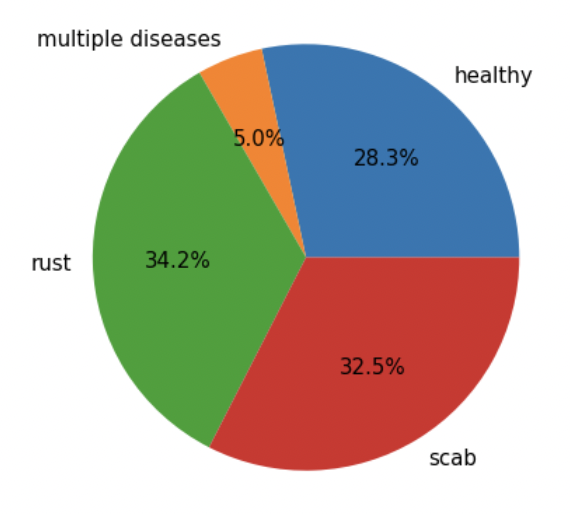
- multiple diseases을 보면 다른 타깃값에 비해 비율 차이가 크기 때문에 나중에 훈련, 검증 데이터를 나눌 때 타깃값 비율에 맞게 나누어 준다.
-
각 타깃값에 해당하는 이미지를 출력해본다.
import matplotlib.gridspec as gridspec import cv2 # OpenCV 라이브러리 def show_image(img_ids, rows=2, cols=3): assert len(img_ids) <= rows*cols # 이미지가 행/열 개수보다 많으면 오류 발생 plt.figure(figsize=(15, 8)) # 전체 Figure 크기 설정 grid = gridspec.GridSpec(rows, cols) # 서브플롯 배치 # 이미지 출력 for idx, img_id in enumerate(img_ids): img_path = f'{data_path}/images/{img_id}.jpg' # 이미지 파일 경로 image = cv2.imread(img_path) # 이미지 파일 읽기 image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 이미지 색상 보정 ax = plt.subplot(grid[idx]) ax.imshow(image) # 이미지 출력# 각 타깃값별 image_id(마지막 6개) num_of_imgs = 6 last_healthy_img_ids = healthy['image_id'][-num_of_imgs:] last_multiple_diseases_img_ids = multiple_diseases['image_id'][-num_of_imgs:] last_rust_img_ids = rust['image_id'][-num_of_imgs:] last_scab_img_ids = scab['image_id'][-num_of_imgs:]- show_image()함수로 잎사귀 이미지를 출력해서 살펴볼 수 있다.

- show_image()함수로 잎사귀 이미지를 출력해서 살펴볼 수 있다.
-
Baseline Model
- 데이터 준비과정에서 이미지 변환기로 데이터를 증강해주고, 사전 훈련된 모델을 사용해 전이 학습을 진행한다.
시드값 고정 및 GPU 장비 설정
-
먼저 시드값을 고정하고 GPU 장비를 설정한다.
import torch # 파이토치 import random import numpy as np import os # 시드값 고정 seed = 50 os.environ['PYTHONHASHSEED'] = str(seed) random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False torch.backends.cudnn.enabled = Falsedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu') device
데이터 준비
-
데이터를 불러오고 훈련, 검증 데이터로 분리한다. 이때 타깃값이 골고루 분포되도록 stratify 파라미터에 타깃값 4개를 전달한다.
import pandas as pd # 데이터 경로 data_path = '/kaggle/input/plant-pathology-2020-fgvc7/' train = pd.read_csv(data_path + 'train.csv') test = pd.read_csv(data_path + 'test.csv') submission = pd.read_csv(data_path + 'sample_submission.csv')from sklearn.model_selection import train_test_split # 훈련 데이터, 검증 데이터 분리 train, valid = train_test_split(train, test_size=0.1, stratify=train[['healthy', 'multiple_diseases', 'rust', 'scab']], random_state=50) -
데이터셋 클래스도 정의해준다.
import cv2 from torch.utils.data import Dataset # 데이터 생성을 위한 클래스 import numpy as np class ImageDataset(Dataset): # 초기화 메서드(생성자) def __init__(self, df, img_dir='./', transform=None, is_test=False): super().__init__() # 상속받은 Dataset의 __init__() 메서드 호출 self.df = df self.img_dir = img_dir self.transform = transform self.is_test = is_test # 데이터셋 크기 반환 메서드 def __len__(self): return len(self.df) # 인덱스(idx)에 해당하는 데이터 반환 메서드 def __getitem__(self, idx): img_id = self.df.iloc[idx, 0] # 이미지 ID img_path = self.img_dir + img_id + '.jpg' # 이미지 파일 경로 image = cv2.imread(img_path) # 이미지 파일 읽기 image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 이미지 색상 보정 # 이미지 변환 if self.transform is not None: image = self.transform(image=image)['image'] # 테스트 데이터면 이미지 데이터만 반환, 그렇지 않으면 타깃값도 반환 if self.is_test: return image # 테스트용일 때 else: # 타깃값 4개 중 가장 큰 값의 인덱스 label = np.argmax(self.df.iloc[idx, 1:5]) return image, label # 훈련/검증용일 때- __init__메서드의 is_test 파라미터에 True를 전달하면 데이터셋을 테스트용으로, False를 전달하면 훈련/검증용으로 만든다.
- __getitem__()메서드로 데이터를 가져올 때 지정한 is_test 값을 확인해 테스트 데이터용이라면 이미지 데이터만, 훈련/검증용이라면 타깃값도 함께 반환한다.
- 훈련/검증용일 때 타깃값은 4가지 중 가장 큰 값의 인덱스가 된다.
-
albumentations가 제공하는 데이터 증강용 이미지 변환기를 정의해준다.
# 이미지 변환을 위한 모듈 import albumentations as A from albumentations.pytorch import ToTensorV2 -
훈련 데이터용 변환기를 먼저 정의해준다. 여러 변환기를 Compose()메서드로 묶어 사용한다.
# 훈련 데이터용 변환기 transform_train = A.Compose([ A.Resize(450, 650), # 이미지 크기 조절 A.RandomBrightnessContrast(brightness_limit=0.2, # 밝기 대비 조절 contrast_limit=0.2, p=0.3), A.VerticalFlip(p=0.2), # 상하 대칭 변환 A.HorizontalFlip(p=0.5), # 좌우 대칭 변환 A.ShiftScaleRotate( # 이동, 스케일링, 회전 변환 shift_limit=0.1, scale_limit=0.2, rotate_limit=30, p=0.3), A.OneOf([A.Emboss(p=1), # 양각화, 날카로움, 블러 효과 A.Sharpen(p=1), A.Blur(p=1)], p=0.3), A.PiecewiseAffine(p=0.3), # 어파인 변환 A.Normalize(), # 정규화 변환 ToTensorV2() # 텐서로 변환 ])-
Resize: 이미지 크기를 조절하는 변환기로, (높이, 너비)이다. 이미지를 크게 조정했을 때 성능이 좋아지기도 한다. 하드웨어 상태를 잘 고려해서 설정해준다.
-
RandomBrightnessContrast: 이미지의 밝기와 대비를 조절하는 변환기이다. brightness_limit으로 이미지 밝기 조절값을 설정하는데, 1에 가까울수록 밝고 -1에 가까울수록 어둡다. 0.2이면 -0.2~0.2 범위에서 적용된다는 것이다. contrast_limit으로는 이미지 대비 조절값을 설정한다. p는 적용 확률로, 0.3이면 30%의 확률로 변환기를 적용하는 것이다.
-
ShiftScaleRotate: 이동, 스케일링, 회젼 변환기이다. 이동, 스케일징, 회전 각도 조절값에 각각 0.1, 0.2, 30을 전달했으니 -0.1~0.1, -0.2~0.2, -30~30 사이에서 무작위로 선택해 적용하는 것이다.
-
Emboss(양각화 효과), Sharpen(날카롭게 만드는 효과), Blur(블러 효과) 중 하나를 선택해(OneOf) 적용한다.
-
PiecewiseAffine: 어파인 변환기로, 이동, 확대/축소, 회전 등을 하여 이미지 모양을 전체적으로 바꾸는 변환이다.
-
Normalize: 값을 정규화해주는 변환기
-
ToTensorV2: 이미지 데이터를 Tesnor 형식으로 변환해준다.
-
-
이어서 검증 및 테스트 데이터용 변환기도 정의해준다.
# 검증 및 테스트 데이터용 변환기 transform_test = A.Compose([ A.Resize(450, 650), # 이미지 크기 조절 A.Normalize(), # 정규화 변환 ToTensorV2() # 텐서로 변환 ])- 훈련 데이터와 크기를 똑같이 맞춰주고, 픽셀 값 범위를 비슷하게 해주기 위해 정규화해주고 pytorch에서 사용하기 위해 Tensor로 변환해주었다.
-
훈련 데이터셋을 만들 때는 훈련용 변환기, 검증 데이터셋을 만들때는 검증/테스트용 변환기를 전달해 데이터셋을 정의해준다.
img_dir = '/kaggle/input/plant-pathology-2020-fgvc7/images/' dataset_train = ImageDataset(train, img_dir=img_dir, transform=transform_train) dataset_valid = ImageDataset(valid, img_dir=img_dir, transform=transform_test)- 모델 훈련 시간이 오래 걸리기에 멀티프로세싱을 활용한다. seed_worker()를 정의하고 제너레이터를 생성해준다.
def seed_worker(worker_id): worker_seed = torch.initial_seed() % 2**32 np.random.seed(worker_seed) random.seed(worker_seed) g = torch.Generator() g.manual_seed(0)-
배치크기를 4로 하여 데이터 로더를 생성한다.
from torch.utils.data import DataLoader # 데이터 로더 클래스 batch_size = 4 loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, worker_init_fn=seed_worker, generator=g, num_workers=2) loader_valid = DataLoader(dataset_valid, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g, num_workers=2)
모델 생성
-
사전 훈련 모델을 전이학습하여 모델을 생성한다. 사전 훈련 모델(pretained model)이란 이미 한 분야에서 훈련을 마친 모델이고, 전이 학습(transfer learning)이란 사전 훈련 모델을 유사한 다른 영역에서 재훈련 시키는 기법이다. torchvision.models나 pretrained 모듈을 이용할 수 있고, 구글에 검색해 가져올 수도 있다.
-
EfficientNet 모델을 사용하도록 한다. efficientnet_pytorch 모듈을 설치하고 efficientnet-b7을 불러와 device 장비에 할당한다.
!pip install efficientnet-pytorch==0.7.1from efficientnet_pytorch import EfficientNet # EfficientNet 모델 # 사전 훈련된 efficientnet-b7 모델 불러오기 model = EfficientNet.from_pretrained('efficientnet-b7', num_classes=4) model = model.to(device) # 장비 할당
- num_classes 파라미터는 최종 출력값 개수를 의미한다. EfficientNet은 타깃값이 1000개인 이미지넷 데이터로 사전 훈련한 모델이라 최종 출력값이 1000개이므로 num_classes에 예측해야하는 타깃값 4개를 전달해준다.
모델 훈련 및 성능 검증
-
손실함수를 CrossEntropyLoss()로 정의해주고, 옵티마이저는 AdamW를 사용한다. Adam에 가중치 감쇠(weight decay)를 적용해 오버피팅을 낮춘 모델이다.
import torch.nn as nn # 신경망 모듈 # 손실 함수 criterion = nn.CrossEntropyLoss() # 옵티마이저 optimizer = torch.optim.AdamW(model.parameters(), lr=0.00006, weight_decay=0.0001) -
훈련을 할 때는 모든 에폭만큼 훈련을 마친 뒤 성능을 검증하지 않고, 매 에폭마다 검증하여 오버피팅없이 훈련이 되고 있는지 확인할 수 있게 한다.
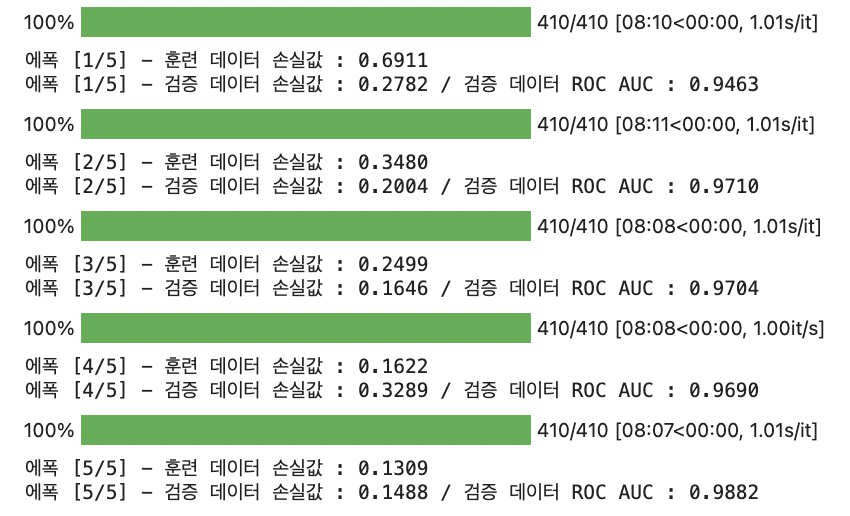
from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수 from tqdm.notebook import tqdm # 진행률 표시 막대 epochs = 5 # 총 에폭만큼 반복 for epoch in range(epochs): # == [ 훈련 ] ============================================== model.train() # 모델을 훈련 상태로 설정 epoch_train_loss = 0 # 에폭별 손실값 초기화 (훈련 데이터용) # '반복 횟수'만큼 반복 for images, labels in tqdm(loader_train): # 이미지, 레이블(타깃값) 데이터 미니배치를 장비에 할당 images = images.to(device) labels = labels.to(device) # 옵티마이저 내 기울기 초기화 optimizer.zero_grad() # 순전파 : 이미지 데이터를 신경망 모델의 입력값으로 사용해 출력값 계산 outputs = model(images) # 손실 함수를 활용해 outputs와 labels의 손실값 계산 loss = criterion(outputs, labels) # 현재 배치에서의 손실 추가 (훈련 데이터용) epoch_train_loss += loss.item() loss.backward() # 역전파 수행 optimizer.step() # 가중치 갱신 # 훈련 데이터 손실값 출력 print(f'에폭 [{epoch+1}/{epochs}] - 훈련 데이터 손실값 : {epoch_train_loss/len(loader_train):.4f}') # == [ 검증 ] ============================================== model.eval() # 모델을 평가 상태로 설정 epoch_valid_loss = 0 # 에폭별 손실값 초기화 (검증 데이터용) preds_list = [] # 예측 확률값 저장용 리스트 초기화 true_onehot_list = [] # 실제 타깃값 저장용 리스트 초기화 with torch.no_grad(): # 기울기 계산 비활성화 # 미니배치 단위로 검증 for images, labels in loader_valid: images = images.to(device) labels = labels.to(device) outputs = model(images) loss = criterion(outputs, labels) epoch_valid_loss += loss.item() preds = torch.softmax(outputs.cpu(), dim=1).numpy() # 예측 확률값 # 실제값 (원-핫 인코딩 형식) true_onehot = torch.eye(4)[labels].cpu().numpy() # 예측 확률값과 실제값 저장 preds_list.extend(preds) true_onehot_list.extend(true_onehot) # 검증 데이터 손실값 및 ROC AUC 점수 출력 print(f'에폭 [{epoch+1}/{epochs}] - 검증 데이터 손실값 : {epoch_valid_loss/len(loader_valid):.4f} / 검증 데이터 ROC AUC : {roc_auc_score(true_onehot_list, preds_list):.4f}')- 바깥 for문에서 epoch 단위로 훈련, 검증을 반복한다. 훈련단계에서만 역전파가 이루어지므로 검증 단계에서는 기울기 계산을 비활성화하고 미니배치 단위로 검증을 수행해 ROC AUC 점수를 출력한다.
- tqdm 라이브러리로 진행률 상태를 표시해준다. 시간이 오래걸리는 for문에 사용한다.
- 실제 타깃값은 원-핫 인코딩 형식으로 구한다. .cpu().numpy()는 값을 CPU에 할당하고 넘파이로 변환하는 것으로, ROC AUC를 구하기 위해 사용한다.
예측
-
테스트용 데이터셋과 데이터 로더를 생성하고 테스트 데이터로 타깃 확률을 예측한다.
dataset_test = ImageDataset(test, img_dir=img_dir, transform=transform_test, is_test=True) loader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g, num_workers=2)model.eval() # 모델을 평가 상태로 설정 preds = np.zeros((len(test), 4)) # 예측값 저장용 배열 초기화 with torch.no_grad(): for i, images in enumerate(loader_test): images = images.to(device) outputs = model(images) # 타깃 예측 확률 preds_part = torch.softmax(outputs.cpu(), dim=1).squeeze().numpy() preds[i*batch_size:(i+1)*batch_size] += preds_part- 예측값을 저장하기 위해 열이 4개인 배열을 준비하고, 타깃 예측 확률을 구한다. preds_part에 확률값을 할당하고, 이를 이용해 preds배열을 갱신한다. preds 배열에서 해당하는 행 위치에 있는 0을 배치 크기만큼 확률값들로 갱신하여 최종적으로 preds에 모든 테스트 데이터의 예측 확률값들이 저장되게 한다.
-
제출파일을 만들어 제출하면 private 점수 0.95072로 총 1318명 중 616등으로 상위 46% 정도를 기록한다.
성능 개선
- 점수를 향상시키기 위해 epoch을 늘리고, 스케줄러를 추가한다. 예측 단계에서 TTA 기법과 레이블 스무딩도 적용하도록 한다.
모델 훈련 및 성능 검증
-
손실 함수와 옵티마이저 설정까지는 Baseline과 동일하되, 스케줄러를 추가로 설정하여 훈련해준다. 스케줄러는 훈련 과정에서 학습률을 조정하는 기능을 제공한다. 학습률은 훈련 초반에 크고 점차 줄이는 것이 최적 가중치를 찾기에 유리하므로 스케줄러를 사용해준다.
-
지정한 값만큼 학습률을 증가시켰다 코사인 그래프 모양으로 감소하는 get_cosine_schedule_with_warmup() 스케줄러를 사용하도록 한다.
from transformers import get_cosine_schedule_with_warmup epochs = 39 # 총 에폭 # 스케줄러 생성 scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=len(loader_train)*3, num_training_steps=len(loader_train)*epochs)- epoch 수를 39로 늘려주었고, 스케줄러를 생성했다. 첫번째 파라미터로 옵티마이저를 전달하여 해당 옵티마이저로 가중치를 갱신할 때 스케줄러로 학습률을 조정할 수 있게 해준다. 학습률은 매 iteration마다 갱신된다. num_warmup_steps 파라미터는 몇 epoch만에 지정한 학습률에 도달할지를 의미하고, num_training_steps 파라미터는 모든 훈련을 마치는 데 필요한 반복 횟수를 의미한다.
-
Baseline 코드에서 스케줄러 갱신 코드만 추가해 모델을 훈련하며 성능을 검증해본다. (5시간 정도 소요)
from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수 from tqdm.notebook import tqdm # 진행률 표시 막대 # 총 에폭만큼 반복 for epoch in range(epochs): # == [ 훈련 ] ============================================== model.train() # 모델을 훈련 상태로 설정 epoch_train_loss = 0 # 에폭별 손실값 초기화 (훈련 데이터용) # '반복 횟수'만큼 반복 for images, labels in tqdm(loader_train): # 이미지, 레이블(타깃값) 데이터 미니배치를 장비에 할당 images = images.to(device) labels = labels.to(device) # 옵티마이저 내 기울기 초기화 optimizer.zero_grad() # 순전파 : 이미지 데이터를 신경망 모델의 입력값으로 사용해 출력값 계산 outputs = model(images) # 손실 함수를 활용해 outputs와 labels의 손실값 계산 loss = criterion(outputs, labels) # 현재 배치에서의 손실 추가 (훈련 데이터용) epoch_train_loss += loss.item() loss.backward() # 역전파 수행 optimizer.step() # 가중치 갱신 scheduler.step() # 스케줄러 학습률 갱신 # 훈련 데이터 손실값 출력 print(f'에폭 [{epoch+1}/{epochs}] - 훈련 데이터 손실값 : {epoch_train_loss/len(loader_train):.4f}') # == [ 검증 ] ============================================== model.eval() # 모델을 평가 상태로 설정 epoch_valid_loss = 0 # 에폭별 손실값 초기화 (검증 데이터용) preds_list = [] # 예측 확률값 저장용 리스트 초기화 true_onehot_list = [] # 실제 타깃값 저장용 리스트 초기화 with torch.no_grad(): # 기울기 계산 비활성화 # 미니배치 단위로 검증 for images, labels in loader_valid: images = images.to(device) labels = labels.to(device) outputs = model(images) loss = criterion(outputs, labels) epoch_valid_loss += loss.item() preds = torch.softmax(outputs.cpu(), dim=1).numpy() # 예측 확률값 # 실제값 (원-핫 인코딩 형식) true_onehot = torch.eye(4)[labels].cpu().numpy() # 예측 확률값과 실제값 저장 preds_list.extend(preds) true_onehot_list.extend(true_onehot) # 검증 데이터 손실값 및 ROC AUC 점수 출력 print(f'에폭 [{epoch+1}/{epochs}] - 검증 데이터 손실값 : {epoch_valid_loss/len(loader_valid):.4f} / 검증 데이터 ROC AUC : {roc_auc_score(true_onehot_list, preds_list):.4f}')- scheduler.step()으로 매 iteration마다 스케줄러의 학습률을 갱신한다.
- 검증 데이터 ROC AUC는 0.9866으로 Baseline에 비해 0.0207점 정도 향상되었다.
예측 및 결과 제출
-
훈련을 마치고 테스트 데이터를 활용해 예측한 뒤 제출한다. 예측에서 TTA와 레이블 스무딩 기법을 이용한다.
-
테스트 단계에서 활용하는 데이터 증강 기법인 TTA(Test-Time Augmentation)를 이용해 예측 성능을 향상시킨다. 테스트 데이터를 여러번 변형한 뒤 예측해 변환된 테스트 데이터별로 타깃 확률값을 예측해 평균을 구한다. 이렇게 하면 앙상블 효과가 있고, 테스트 데이터가 늘어난 효과를 받을 수 있다. 하지만 반드시 성능이 향상되는것만은 아니니 상황에 맞게 사용한다.
-
데이터셋과 데이터 로더를 두 개 준비하는데, 하나는 테스트 데이터 원본용, 하나는 TTA용으로 만들어준다.
# 테스트 데이터 원본 데이터셋 및 데이터 로더 dataset_test = ImageDataset(test, img_dir=img_dir, transform=transform_test, is_test=True) loader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g, num_workers=2) # TTA용 데이터셋 및 데이터 로더 dataset_TTA = ImageDataset(test, img_dir=img_dir, transform=transform_train, is_test=True) loader_TTA = DataLoader(dataset_TTA, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g, num_workers=2)- 원본용 데이터셋에는 변환기로 transform_test를 전달하고, TTA용 데이터셋에는 transform_train을 전달하여 훈련 데이터처럼 여러 변환을 적용해준다.
-
먼저 원본 테스트 데이터로 예측하고 submission_test에 저장해둔다.
model.eval() # 모델을 평가 상태로 설정 preds_test = np.zeros((len(test), 4)) # 예측값 저장용 배열 초기화 with torch.no_grad(): for i, images in enumerate(loader_test): images = images.to(device) outputs = model(images) # 타깃 예측 확률 preds_part = torch.softmax(outputs.cpu(), dim=1).squeeze().numpy() preds_test[i*batch_size:(i+1)*batch_size] += preds_partsubmission_test = submission.copy() # 제출 샘플 파일 복사 submission_test[['healthy', 'multiple_diseases', 'rust', 'scab']] = preds_test -
이어서 TTA를 7번 적용해 예측한다. TTA를 적용한 preds_tta를 구하고, 값을 평균내야 하니 TTA횟수로 다시 나누어준 후 예측한 타깃 확률을 submission_tta에 저장한다.
num_TTA = 7 # TTA 횟수 preds_tta = np.zeros((len(test), 4)) # 예측값 저장용 배열 초기화 (TTA용) # TTA를 적용해 예측 for i in range(num_TTA): with torch.no_grad(): for i, images in enumerate(loader_TTA): images = images.to(device) outputs = model(images) # 타깃 예측 확률 preds_part = torch.softmax(outputs.cpu(), dim=1).squeeze().numpy() preds_tta[i*batch_size:(i+1)*batch_size] += preds_partpreds_tta /= num_TTAsubmission_tta = submission.copy() submission_tta[['healthy', 'multiple_diseases', 'rust', 'scab']] = preds_tta -
원본 테스트 데이터로 구한 예측값과 TTA를 적용해 구한 예측값을 각각 제출 파일로 만들어준다.
submission_test.to_csv('submission_test.csv', index=False) submission_tta.to_csv('submission_tta.csv', index=False)
-
-
레이블 스무딩 기법으로 성능을 더 높여줄 수 있다. 일반화 성능을 높이기 위해 예측값을 보정해주는 기법이다. 레이블 스무딩 강도는 "(1-a) * preds + (a/K)"로, preds는 예측확률값, K는 타깃값 개수를 의미한다. a가 0이면 보정한 값이 원래 예측값과 같고, 1이면 모든 타깃 예측값이 1/K가 되므로 a가 클수록 보정 강도가 강해지는 것이다. preds가 (0,0,1,0)이고 a가 0.1이라면 레이블 스무딩을 통해 예측값을 보정하면 (0.025, 0.025, 0.925, 0.025)가 된다. 일반화 성능이 올라갈 것을 짐작할 수 있다.
def apply_label_smoothing(df, target, alpha, threshold): # 타깃값 복사 df_target = df[target].copy() k = len(target) # 타깃값 개수 for idx, row in df_target.iterrows(): if (row > threshold).any(): # 임계값을 넘는 타깃값인지 여부 판단 row = (1 - alpha)*row + alpha/k # 레이블 스무딩 적용 df_target.iloc[idx] = row # 레이블 스무딩을 적용한 값으로 변환 return df_target # 레이블 스무딩을 적용한 타깃값 반환-
함수의 파라미터를 살펴보면 target은 타깃값 이름의 리스트, alpha는 레이블 스무딩 강도, threshold는 레이블 스무딩을 적용할 최솟값을 의미한다. 이를 설정하면 타깃값이 threshold를 넘을때만 적용한다.
-
각 타깃값에 대해 threshold를 넘는지 판단하고, 넘으면 과잉 확신한 것으로 판단해 레이블 스무딩을 적용한다.
-
이 함수를 결과에 적용해 레이블 스무딩을 하고 제출 파일 submission_test_ls, submission_tta_ls파일을 만들어 준다.
alpha = 0.001 # 레이블 스무딩 강도 threshold = 0.999 # 레이블 스무딩을 적용할 임계값 # 레이블 스무딩을 적용하기 위해 DataFrame 복사 submission_test_ls = submission_test.copy() submission_tta_ls = submission_tta.copy() target = ['healthy', 'multiple_diseases', 'rust', 'scab'] # 타깃값 열 이름 # 레이블 스무딩 적용 submission_test_ls[target] = apply_label_smoothing(submission_test_ls, target, alpha, threshold) submission_tta_ls[target] = apply_label_smoothing(submission_tta_ls, target, alpha, threshold) submission_test_ls.to_csv('submission_test_ls.csv', index=False) submission_tta_ls.to_csv('submission_tta_ls.csv', index=False)
-
-
TTA와 레이블 스무딩 기법을 이용했기에 최종적으로 총 4개의 제출 파일이 만들어졌을텐데,
submission_test는 테스트 데이터 원본으로 예측한 파일,
submission_tta는 TTA를 적용한 파일,
submission_test_ls는 submission_test에 레이블 스무딩을 적용한 파일,
submission_tta_ls는 submission_tta에 레이블 스무딩을 적용한 파일이다.- 4개의 파일을 각각 제출하면 순서대로 private 점수 0.96814, 0.96861, 0.97114, 0.97141 정도의 점수를 기록하고, TTA와 레이블 스무딩을 모두 적용했을 때 가장 높은 0.97141점을 기록했다. 이는 전체 1318명 중 230등으로 상위 17.5%이다.
-
여기서 훈련 데이터를 훈련용, 검증용으로 나누지 않고 100% 훈련 데이터로 활용하면 성능이 더 올라간다. 전체 코드에서 훈련용, 검증용 데이터로 나누는 코드만 제외하면 된다. 이를 적용하면 private 점수 0.97795점까지 향상시킬 수 있다. 이는 전체 15등으로 상위 1.1% 수준이다.
최종
-
딥러닝 모델에 스케줄러를 추가하고, pretrained model(사전 훈련 모델)로 EfficientNet을 사용해 훈련하여 transfer learning하고, 예측 단계에서 TTA와 label smoothing을 적용해 성능을 개선할 수 있었다.
-
다른 pretrained model들로 훈련한 결과를 앙상블해서 더 성능을 향상시킬 수도 있을 것이다.
-
github에 해당 코드를 올려두었다.
참고: 머신러닝·딥러닝 문제해결 전략 (캐글 수상작 리팩터링으로 배우는 문제해결 프로세스와 전략)
참고: https://www.kaggle.com/code/akasharidas/plant-pathology-2020-in-pytorch/notebook
