
Intro
문장 간(혹은 문서 간) 유사도 분석에서 좋은 성능을 내고 있는 Sentence-BERT에 대해 알아보려고 한다.
논문 원제는 Sentence-BERT: Sentence Embedding using Siamese BERT-Networks이며, 최근 성능이 보완되어 발표된 Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks 논문의 근간이라고 할 수 있다.
Abstract
BERT와 RoBERTa와 같은 언어모델은 STS와 같은 sentence-pair regression 태스크에서 SOTA를 달성하였지만, 치명적인 단점이 있었으니 바로 비교할 두 개의 문장이 모두 네트워크에 입력되어야 해서 엄청난 컴퓨팅 overhead를 발생시킨다는 것이었다. 만약 BERT를 통해 10,000개의 문장 쌍을 비교한다면 약 50 million 컴퓨팅 연산 (약 ~65시간 소요)이 필요하게 된다!🤯
이러한 문제를 위해 해당 논문은 Siamese Network와 Triplet Loss를 BERT 네트워크에 사용하여 Sentence-BERT(SBERT) 라는 새로운 네트워크를 제안하였으며, cosine 유사도를 통한 의미적 유의미한 sentence embedding을 가능토록하였다.
이로 인해 BERT와 RoBERTa에서 65시간이 소요되었던 작업을 5초 이내로 수행할 수 있게되었고, STS, sentence embedding 같은 태스크에서 SOTA를 달성하게 되었다.
1. Introduction
1.1. Pair-Regression Task에서의 BERT의 한계
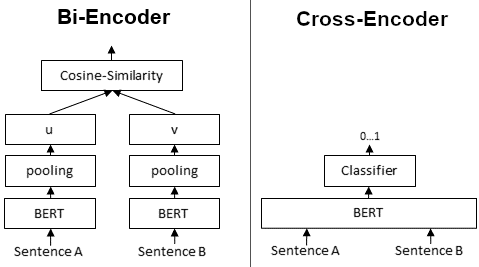
BERT는 기본적으로 cross-encoder를 사용한다.
이로 인해 비교할 두 개의 문장은 모두 transformer network를 동시에 통과하여 매번 새롭게 변환된 임베딩 값으로 계산되어야한다. 하지만 이러한 방법은 다수의 비교 쌍이 있을 경우 엄청난 컴퓨팅 연산을 필요로 한다.
만약 10,000개의 문장 비교 쌍이 있을 경우, 의 inference computation을 필요로 하게 되는데 이는 V100 GPU 기준으로도 약 65시간이 소요되는 엄청난 연산비용이다.
1.2. 기존 Sentence-Embedding 방법의 한계
Clustering 및 Semantic Search를 위한 일반적인 접근 방법은 바로 각각의 문장을 vector space에 맵핑하는 것이었다.
이러한 방법은 BERT에서도 아래와 같은 방법으로 시도되었다.
- 문장의 각 토큰 output layer의 hidden-states를 평균내는 방법

- [CLS] 토큰의 hidden state를 사용하는 방법 (context vector의 의미로서)

하지만 일반적으로 위와 같은 sentence embedding 방법은 단지 GloVe embedding을 평균하여 사용하는 것보다도 성능이 떨어진다고 알려져있다.
참고: Why Bert transformer uses [CLS] token for classification instead of average over all tokens?
1.3. 위 한계를 극복하기 위한 Sentence-BERT!😎
SBERT는 위에 열거한 한계를 극복하기 위해 Siamese network와 triplet loss를 활용한 새로운 네트워크 구조를 제안하였다.
SBERT는 기존 BERT에서 65시간이 소요되었던 10,000개의 문장 비교 작업을 5초 이내에 수행하였으며, NLI 데이터 기준 기존 Sentence-Embedding 태스크에서 SOTA를 달성하였던 InferSent에 비해 11.7점, Universal Sentence Encoder(USE)에 비해 5.5점 이상 좋은 성능을 달성하였다.
2. Model
2.1. Pooling Operation
SBERT는 BERT/RoBERTa의 output을 고정 사이즈의 sentence embedding으로 추출하기 위해 Pooling 연산을 적용하였다.
- Pooling을 위한 3가지 전략
- [CLS] 토큰의 output 값을 사용
- 모든 토큰의 output vector를 평균 (MEAN-strategy)
- 모든 토큰의 max output vector를 사용 (MAX-strategy)
본 논문에서는 defult로 MEAN-strategy를 사용한다.
2.2. Siamese/Triplet Network
 SBERT는 의미론적 유의미한 sentence embedding을 위해 Siamese/Triplet Network를 도입하였다.
SBERT는 의미론적 유의미한 sentence embedding을 위해 Siamese/Triplet Network를 도입하였다.
Siamese Network
Siamese Network는 우리가 흔히 말하는 샴 쌍둥이(siamese twins)를 생각하면 쉽다. 샴 쌍둥이들은 생김새 뿐만 아니라 신체의 일부를 공유하고 있는데 Siamese Network 또한 서로 다른 네트워크로서 존재하지만 네트워크의 weight을 서로 공유하는 형태이다.
siamese network는 아래와 같은 순서로 문장의 유사성을 학습하게 된다.
- 두 입력 문장(s1, s2)이 초기화 된 siamese network로 입력
- 두 입력 문장에 대한 임베딩 벡터 값(e1, e2)을 추출
- 두 임베딩 벡터(e1, e2)에 대해 cosine similarity 혹은 manhattan/euclidean distance 같은 방법을 통해 유사도를 계산
- 만약 두 입력 문장이 서로 같은 class라면 distance가 가까워지도록, 다른 class라면 distance가 멀어지도록 weight을 조절하며 학습
Triplet Loss
Triplet Loss는 타겟이 되는 문장(Anchor), 동일 클래스의 문장(Positive), 다른 클래스의 문장(Negative) 간의 distance를 계산하기 위한 loss function이다.
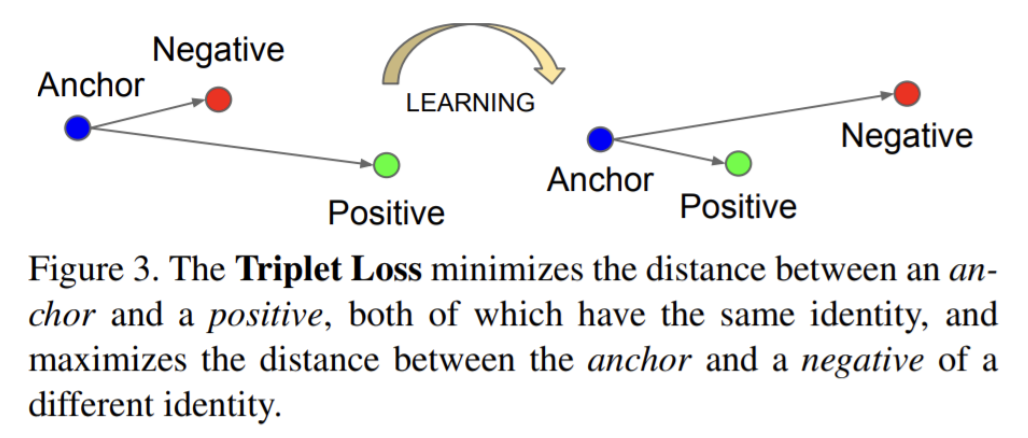
Siamese Network에서 살펴보았듯이 Anchor와 Positive의 distance는 가까워지도록, Anchor와 Negative의 distance는 멀어지도록 학습하는 것이 목표인데 이를 위해 Triplet Loss를 사용한다.
2.3. Objective Functions
Classification Objective function 🚥
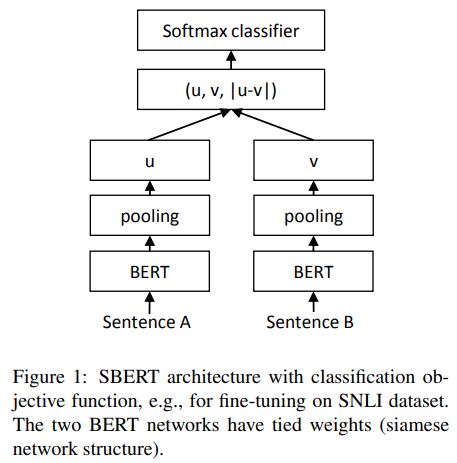
Classification Objective Function을 위해 서로 다른 임베딩 벡터인 와 에 대해 element-wise difference를 계산하고( ) 이를 학습 weight에 곱해준다 ( , 은 sentence embedding의 차원이고, 는 label의 갯수)
loss function으로는 cross-entropy loss를 사용한다.
Regression Objective Function 📈
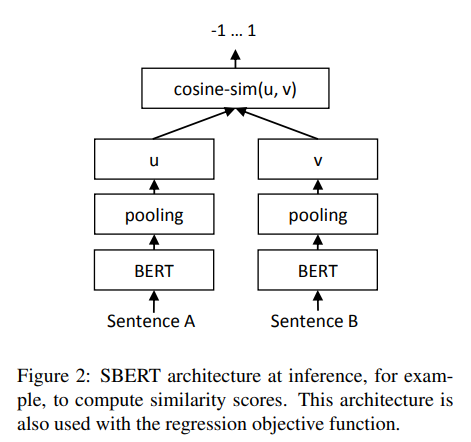
Regression Objective Function은 두개의 sentence embedding인 와 의 coinse-similarity를 계산하며 loss function으로 mean squared error를 사용한다.
Triplet Objective Function
Triplet loss에 대해서는 위에서 간단히 소개하였는데, 다시 간략히 말하자면 타겟 문장에 대해서 동일 클래스의 문장과는 거리가 가깝게, 다른 클래스의 문장과는 거리가 멀도록 하기 위해 triplet loss를 minimize한다.
2.4. Training Details
모델 학습을 위해 570,000개의 문장 쌍으로 이루어진 SNLI 데이터셋과 430,000개의 문장 쌍으로 이루어진 Multi-Genre NLI 데이터 셋이 사용되었다.
fine-tuning은 아래와 같은 조건으로 진행되었다.
- 3-way softmax classifier objective function
- 1 epoch/16 batch-size
- Adam optimizer with learning rate 2e-5
- MEAN Pooling strategy
- linear learning rate warm-up over 10% of the training data
3. Evaluation
해당 연구에서는 두 문장간의 유사도 계산을 위한 모든 실험에서 coinse simliarity가 사용되었다.
3.1. Unsupervised STS
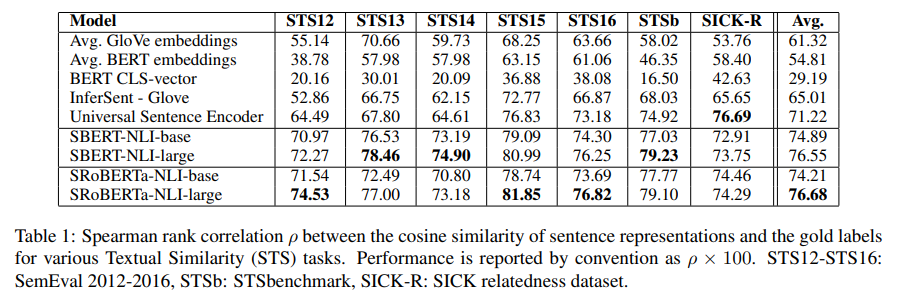
위의 표에서 중요한 점은 확실히 기존 BERT를 이용한 sentence-embedding 방식은 성능이 좋지 않다는 것이다.
'Avg. BERT embeddings' (output layer의 hidden states를 평균) 의 경우 평균 54.81을 달성하였고, 'BERT CLS-vector' (CLS 토큰의 hidden state)의 경우 29.19를 달성하였는데, 이는 모두 GloVe embedding 보다도 훨씬 낮은 성능이었다!
SBERT와 SRoBERTa의 경우 대부분 기존 임베딩 방법에 비해 높은 성능을 달성하였다. (하지만 SBERT와 SRoBERTa 사이의 성능 차이는 매우 미미하다)
3.2. Supervised STS
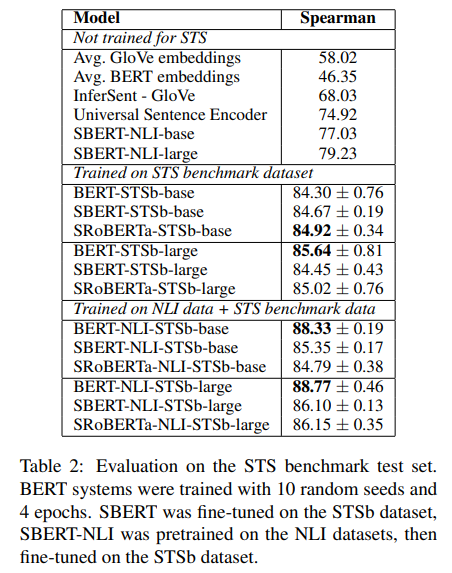
Supervised STS 데이터셋에서도 SBERT와 SRoBERTa가 기존 임베딩 방식에 비해 다소 좋은 성능을 나타내었다.
4. Computational Efficiency
Sentence Embedding은 수만개의 문장 조합을 비교하기 위해 매우 높은 컴퓨팅 속도가 요구된다. 해당 섹션에서는 SBERT, GloVe Embedding, InferSent, Universal Sentence Encoder의 연산 속도를 비교한다.
비교를 위한 데이터셋으로는 STS benchmark가 사용되었으며, 연산 서버의 경우 i7-5820K CPU @ 3.30GHz, Nvidia Tesla V100 GPU가 사용되었다.

위 결과를 보면 CPU에서 InferSent가 SBERT에 비해 65%더 빨랐는데 이는 SBERT가 12개의 Transformer 레이어를 사용하는데이 비해 InferSent가 단순한 네트워크 구조로 이루어졌기 때문이라고 설명한다.
하지만 GPU에서는 오히려 SBERT가 InferSent에 비해 9%, Universal Sentence Encoder에 비해서는 55% 더 빠른 연산 속도를 보여주었다.
5. Conclusion
위 실험을 통해 BERT가 일반적인 유사도 계산을 위한 방법론으로 적합하지 않고, 심지어 GloVe Embedding보다도 더 낮은 성능을 나타내는 것을 확인하였다.
이러한 한계를 극복하기 위해 siamese/triplet network로 학습된 Sentence-BERT(SBERT)를 제안하게 되었으며, 다양한 벤치마크에서 SOTA를 달성하게 되었다. (여기서 BERT를 쓰던 RoBERTa를 쓰던 성능에 큰 차이가 없음도 확인하였다.)
SBERT는 GPU환경에서 InferSent, Universal Sentence Encoder에 비해 더욱 빠른 연산속도를 보여주었고, 기존 BERT에서 65시간이 소요되던 일을 5초만에 수행하는 놀라운 성능을 보여주었다.
References
.jpeg)