
ChatGPT, BARD, LLaMa 등과 같은 LLM은 다재다능합니다.
In-context learning(ICL)의 성능을 증명한 GPT 모델의 등장으로 인해, 데이터 라벨링이 필요한 fine-tuning 방법론은 시간과 비용 측면에서 비효율적인 방법론이 되어버렸습니다. 하지만 ICL의 단점은 모델의 사이즈가 클수록 잘 동작한다는 것입니다. 그렇기에 language model들은 점점 거대해지고 이로인해 일반적인 환경에서는 이를 서빙하기가 힘듭니다.
그렇기에 PEFT(parameter efficient fine-tuning) 방법론도 많이 사용되곤 합니다. PEFT는 LLM을 활용하지만 LLM의 주요 파라미터는 freeze후, 일부 레이어만 학습시키는 방법으로 시간 및 비용측면에서 좀 더 효율적일 뿐만 아니라 모델 경량화 효과도 있습니다. 하지만 이도 결국 LLM을 활용해야한다는 한계는 있습니다.
프롬프트 기반의 PET(pattern exploiting training) 방법론도 활용되지만, 프롬프트의 경우 결국 사용자가 어떻게 프롬프트를 구성하느냐에 따라 성능이 천차만별로 바뀌기 때문에 일관성 측면에서 한계가 있습니다.
SetFit의 아이디어는 간단합니다. (1)Sentence Transformer를 contrastive learning으로 학습 후 (2)뒷단에 classification head를 붙여 소수의 샘플 데이터로 finetuning하는 것이 전부입니다.
SetFit은 text-classification 태스크에 적용할 수 있고 매우 적은 샘플만으로 PET, GPT와 같은 방법론에 견줄만한 성능을 보여주었습니다.
사실 text classification은 NLP 태스크 중에서도 상대적으로 쉬운 태스크라고 생각됩니다. 그렇기에 좋은 품질의 라벨링 데이터셋만 있다면 가벼운 모델로도 충분히 좋은 성능을 낼 수 있기 때문에 굳이 LLM을 사용할 필요가 없습니다. (소🐂 잡는 칼로 닭🐓 잡을 필요 없다는 이야기입니다!)
그럼 SetFit의 공식 논문인 Efficient Few-Shot Learning Without Prompts를 간단히 리뷰해보도록 하겠습니다.
Official Paper : Efficient Few-Shot Learning Without Prompts
Official Github : huggingface/setfit
Abtract
- PEFT(parameter efficient fine-tuning), PET(pattern exploiting training)등과 같은 다양한 few-shot 방법론들이 좋은 성과를 내고 있음.
- 하지만 이런 방법론들은 각각의 수동으로 만들어진 프롬프트로 인해 가변성이 높고, 높은 정확도를 위해서는 더 큰 LLM이 필요
- 이를 해결하기 위해 few-shot finetunging을 위한 efficient and prompt-free framework인 Sentence Transformer기반의 SetFit(Sentence Transformer Fine0tuning)을 제안
- SetFit은 아래와 같이 크게 2가지 방법에 의해 학습됨
- 먼저 사전학습된 ST(Sentence Transformer)에 소량의 text-pairs와 Contrastive Siamese 방법의 objective function으로 finetuning 됨
- 위의 모델은 text-embedding을 생성하기 위해 사용되고, finetuned 모델 뒷단에 classification head를 연결하여 텍스트 분류 학습 진행
- SetFit은 위와 같은 간단한 방법론만으로 PEFT, PET등과 유사한 성능을 기록
1. Introduction
- Few-shot 학습 방법론은 데이터 라벨링에 시간과 비용이 많이 들고, 라벨링된 데이터가 적은 경우를 극복하기 위한 매력적인 솔루션으로 급부상함.
- 이러한 few-shot 방법론은 일반적으로 PLM에 의해 동작하며, ICL(in-context learning), PEFT, PET등이 있음.
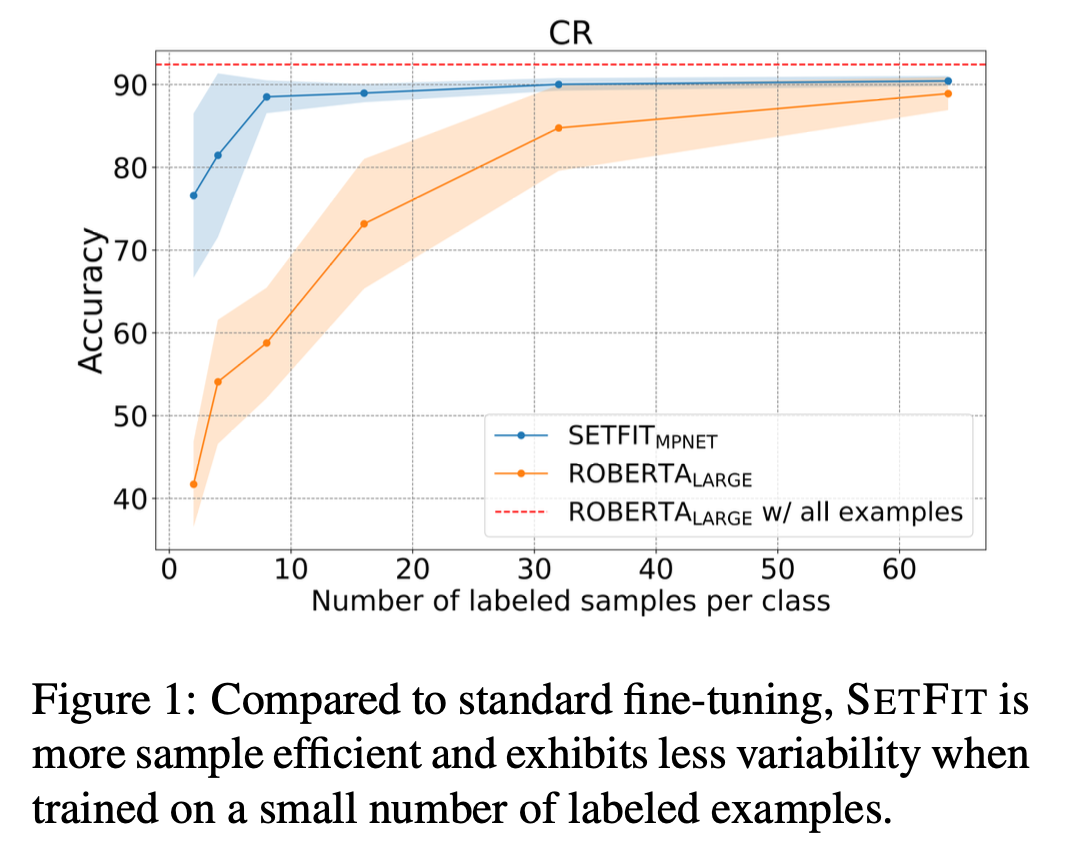
하지만 이러한 방법론들은 large-scale 언어모델에 의존하고 있기 때문에 학습하고 배포하기 위해서는 큰 규모의 인프라를 갖춰야만하는 단점이 있고, 또한 prompt에 의존적이다 보니 결과가 가변적이라는 단점이 있음. - SetFit은 PLM 및 prompt로 부터 자유롭지만, 높은 성능을 달성했음. (ex. 고객 리뷰 감성 분류 문제에서 오직 8개의 샘플만으로 전체 샘플로 finetuning된 모델만큼의 성능을 기록)
2. Related work
3. Setfit: Sentence Transformer Fine-tuning
- SetFit은 Sentence Transformer에 기반하고 있음
- Siamese and triplet network로 학습된 모델
- 텍스트 페어를 통해 두 문장이 의미적으로 유사하면 vector space내 두 문장 벡터의 distance를 minimize하고, 의미적으로 유사하지 않으면 maximize 하여 의미적 유사도를 표현하는 것이 목표
- 학습된 모델의 output은 fixed dense vector
3.1. The SetFit approach for few-shot text classification
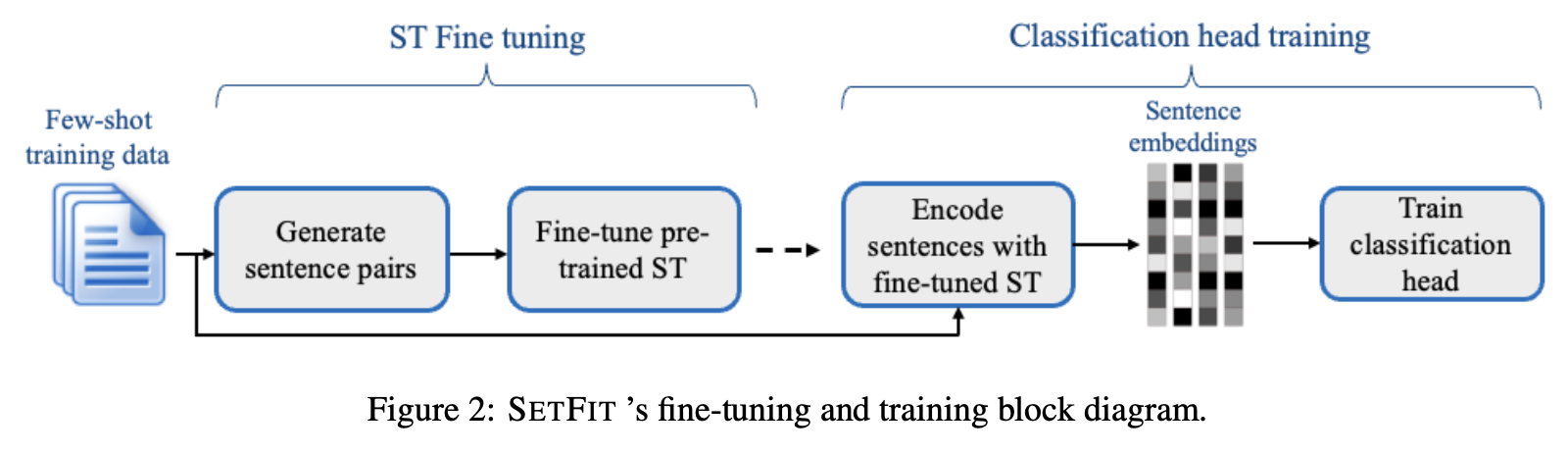
- SetFit은 먼저 ST(Sentence Transformer)을 finetuning후 classifier head를 학습시키는 투 스텝 학습 방법을 사용
Step1. ST fine-tuning
- few-shot 시나리오에서 적은 수의 샘플로도 효율적으로 학습하기 위해 Contrastive Training 방법을 적용
- Positive Triplets :
와 는 동일 클래스 에서 랜덤하게 선택된 sentence pair임- Negative Triplets :
와 는 서로 다른 클래스에서 랜덤하게 선택된 sentence pair임 ()- 최종적으로 constrastive finetuning 데이터셋()은 아래와 같음
- contrastive finetuning 접근법은 샘플의 수를 확장한다는 측면에서 이점이 있음
- 샘플이 4개 있다고 했을 때, 위 접근법으로 데이터 생성 시 샘플이 6개로 확장됨,
(가 샘플 수라고 했을 때, )
Step2. Classification head training
- step1에 의해 학습된 finetuned ST모델은 학습 데이터를 임베딩하는 역할을 수행하게 됨
- 이후 생성된 임베딩 벡터값과 라벨값을 classification head를 통해 학습
T^CH={(Emb^x_i, y_i)}
- 해당 논문에서 텍스트 분류를 위해 classification head에 사용한 모델은 Logistic Regression
Inference
예측 시 finetuned ST모델에 의해 임베딩 벡터값을 얻고, 이를 Classification Head에 통과하여 예측 수행
4. Experiments
4.1. Data
- text classification 데이터셋을 실험
4.2. SetFit models

- 3가지의 다른 모델 및 사이즈의 성능을 비교
4.3. Baselines
- SetFit의 baseline은 RoBERTa-large기반 모델
- SetFit의 성능 비교를 위해 최근 베스트 성능을 내는 few-shot 접근방법론들과 비교 (ADAPET, PERFECT, T-FEW)
5. Results
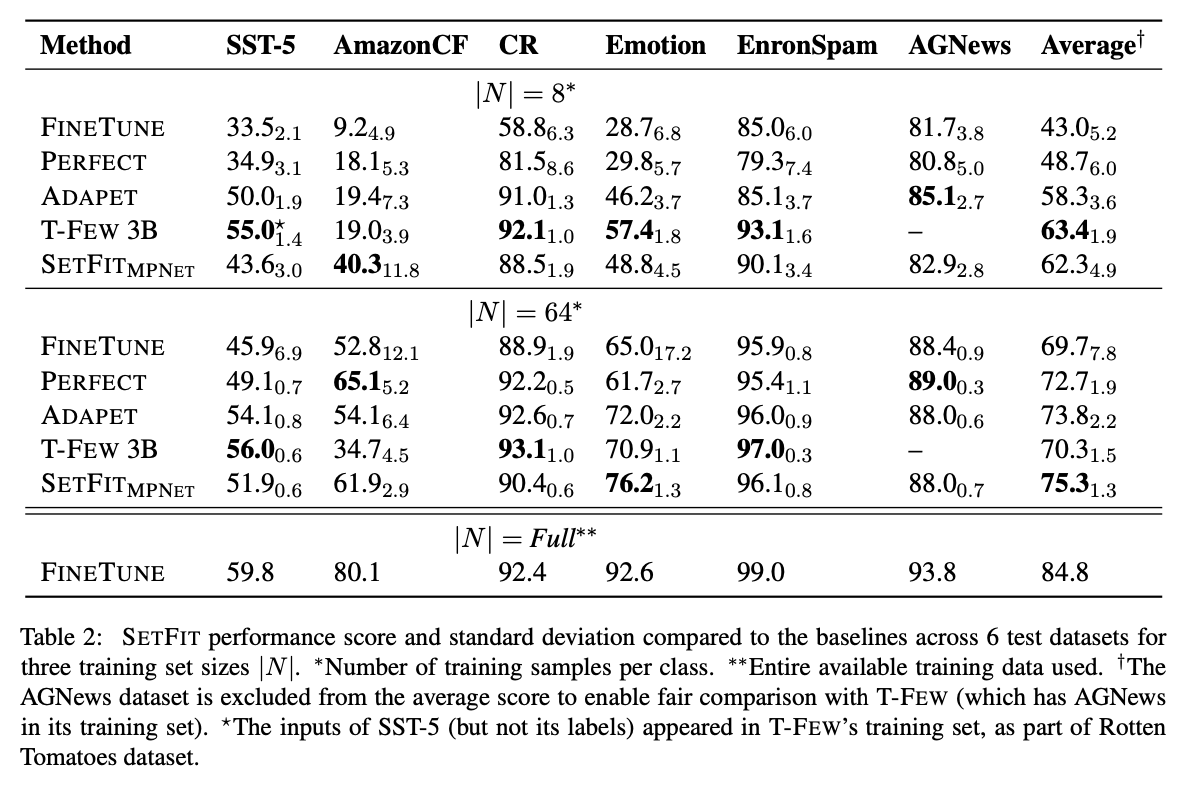
- 우선 Finetune 방법론은 샘플 수가 적을 때는 처참한 성능 수준을 보였고, full finetuning을 해야만 좋은 성능을 냄.
- 반면 SetFit의 경우, 샘플 수가 8개 일때, T-FEW 3B모델에 비해 성능이 낮지만, 샘플 수가 커질 수록 그 격차가 점점 줄어들고 대부분의 데이터셋에서 경쟁적인 성능을 보임
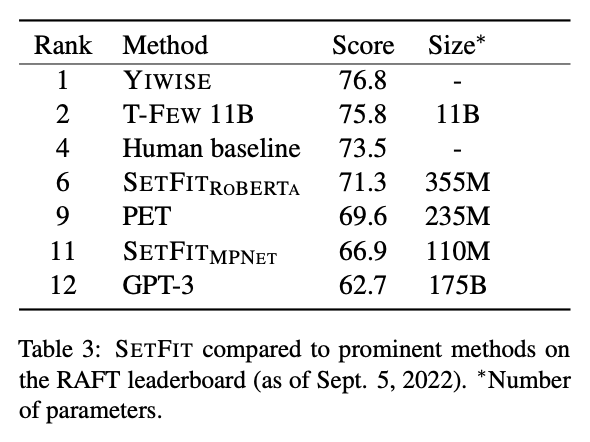
- RAFT 벤치마크에서는 SetFit-RoBERTa 모델이 PET, GPT-3모델 보다 모델 크기, 학습 및 추론 측면에서 더 뛰어난 성능을 기록
6. Multilingual Experiments
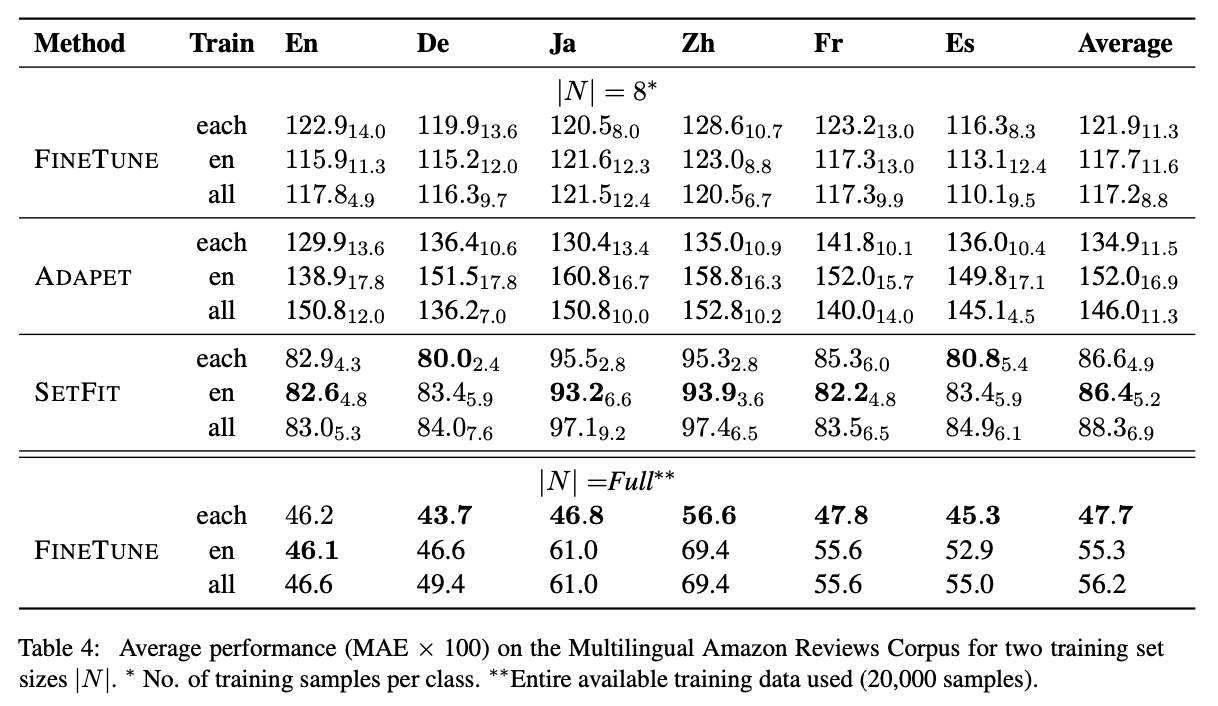
- SetFit의 다국어 성능을 구행하기 위하여 다국어 데이터셋을 통해 실험 진행
- 실험 은 each(각 언어), en(영어 전용), all(모든 언어) 3가지 환경으로 수행
- 결과적으로, SetFit은 모든 설정(N=8)에서 기준선을 능가하는 성능을 보였으며, 영어 데이터로만 학습할 때 평균 성능이 가장 좋았음.
LLM을 활용하지 않고도 적은 수의 샘플만으로 좋은 성능을 낸 SetFit의 핵심은 Contrastive Learning이 아닐까 싶습니다. 의미적으로 유사한 것과 유사하지 않은 것들간의 distance를 계산함으로써 이미 1차적으로 걸러지고 이러한 특성이 반영된 embedding vector를 지도학습함으로써 보다 의미적으로 정확한 분류가 가능했던 것 같습니다.
저는 앞으로 분류문제를 위해서는 SetFit을 적극적으로 활용할 예정입니다. 모델 학습 및 서빙에 큰 인프라 비용이 들지 않음에도 빠르고 강력하기 때문입니다.
점점 모델들이 거대해지면서 이를 활용하기가 쉽지 않은데 이러한 방법론들이 앞으로도 계속 등장해주었으면 합니다.
References
.jpeg)