[Paper Review] PEGASUS:Pre-training with Extracted Gap-sentences for Abstractive Summarization
Paper Review

Intro
최근 NLP의 downstream tasks 중 하나인 Summarization분야에 "PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization"이라는 새로운 논문(멋진 이름이다..)이 등장하여 간략하게 소개해보려고 한다.

What is Text Summarization?
Text Summarization은 자연어 처리 분야의 여러 개의 Downstram tasks중 하나이다.
이름에서부터 쉽게 알 수 있듯이 Text Summarization은 문서를 요약하는 기술을 의미한다.
Text Summarization은 크게 아래와 같이 두 가지로 분류가 된다.
1. Extractive Summarization
2. Abstractive Summarization

위 두 방식은 요약(summarization)을 한다는 측면에서는 동일하나, 그 방법에 차이가 있다.
위 예시와 같이 Extractive는 원문 텍스트로부터 주요 Sentence를 원문 그대로 추출해내는 방식이라면, Abstractive는 우리가 원문 텍스트를 보고 생각과 느낌을 한 줄 요약하듯이 표현하는 방식이라고 할 수 있다.
Extractive Summarization에서 가장 많이 알려진 알고리즘은 아무래도 Text-Rank일 것이다. 초기 구글의 검색엔진랭킹 알고리즘인 Page-Rank를 Text에 적용한 알고리즘으로, 적은 연산량으로도 좋은 성능을 내고 있다. Text-Rank알고리즘은 Document 내에서 Term-Frequency가 높고, Co-occurence가 높은 단어를 keyword로 판단하며, 그러한 keyword를 많이 갖는 Sentence를 Key-Sentence일 것이라 가정하는 알고리즘이라고 할 수 있다.
Text-Rank의 자세한 설명은 해당 링크(TextRank 를 이용한 키워드 추출과 핵심 문장 추출) 참조하면 좋을 것 같다.
Extractive Summarization vs Abstractive Summarization
둘 중에 최근 가장 활발히 연구되는 분야는 아무래도 Abstractive Summarization이다.
Abstractive방식이 Extractive방식보다 훨씬 어려운 난이도의 task일 뿐만 아니라 원문을 그대로 추출해내는 것이 아닌 다양한 표현방식으로 Generate하기 때문에 훨씬 더 다양한 분야에 사용될 수 있기 때문이다.
최근 몇 년 사이 Seqence-to-Sequence, Attention mechanism, Transformer 등과 같은 아키텍처가 등장하고 Bert와 같은 대량의 corpus로 학습된 pre-training 모델이 등장하며 이러한 generator모델의 성능도 나날이 향상되는 추세이다.
이제 아래에서 가장 최근 Abstractive Summarizaion 논문으로 등장한 PEGASUS에 대해 알아보자.
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
Abstract
최근 대량의 text corpora로 self-supervised된 pre-training Transfomers 모델들이 text summarization을 포함한 fine-tuning downstream NLP task에서 좋은 성능을 보이고 있다. 하지만, Abstractive Text Summarization의 목적에 맞게 pre-training된 모델은 찾아보기 힘들고, 더욱이 다양한 domain을 커버할만 한 체계적인 평가 방법도 부족한 상황이다.
따라서, 해당 논문에서는 대량의 text copora로 self-supervised된 encoder-decoder 기반의 pre-training Transformer 모델인 PEGASUS를 소개한다. PEGASUS의 주요 특징은 GSG(Gap sentence generation)을 사용한다는 것인데, 간단히 설명하면 MLM방식에서는 token 단위로 masking하여 masked token을 예측하는 방식으로 학습했던 것과 유사하게, GSG는 token 단위가 아닌 Importance Sentence 단위로 masking을 하여 학습을 수행한다. 여기서 말하는 Importance Sentence란 document 내에서 다른 문장에 비해 전체적인 context를 잘 설명할 수 있는 문장을 말한다.
PEGASUS 모델은 12개의 downstream summarization tasks로부터 ROUGE score를 기반으로 SOTA를 달성하였고, 그 중 6개의 데이터 셋에서 오직 1,000개의 examples만으로도 SOTA를 달성할 만큼 적은 리소스 비용으로 놀라운 성능을 나타내었다.
The Basic architecture of PEGASUS
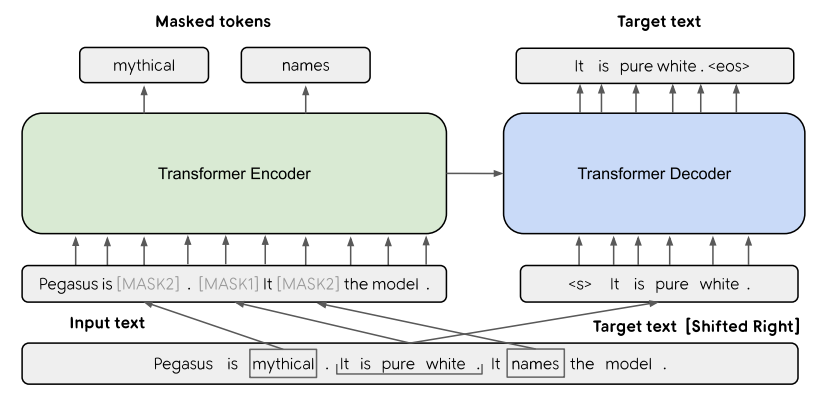
![]()
PEGASUS는 기본적으로 encoder-decoder기반의 Transformer구조를 하고 있으며, 기존 MLM(Masked Language Model)과 유사하게 Input text의 일부를 masking하여 Encoder의 input으로 보내게 된다. 하지만 기존 MLM과 다른 점은 바로 Sentence 자체를 masking한다는 점이다.
기존 MLM 모델들은 token 단위로 masking하여 masked token을 예측하는 방식으로 학습을 진행하였지만, PEGASUS는 Input Document로부터 Sentence 단위로 Masking을 한 후 남은 Sentence를 기반으로 masked sentence를 예측하는 방식으로 학습된다. 논문에서는 이러한 방식을 Gap-Sentences-Generation(GSG)라고 말하고 있다.
Gap Sentences Generation (GSG)
해당 section에서는 새로운 pre-training 방식인 GSG를 소개하고, 기존 BERT masked-language model과 비교를 수행한다.
해당 논문에서 강조하는 것 중 하나는, 좋은 성능을 얻기 위해서는 적용하고자 하는 downstream task의 목적에 맞는 pre-training 모델을 사용하고 이를 fine-tuning 하라는 것이다. 즉, 뉴스를 요약하기 위한 데이터로 학습된 모델은 뉴스 요약에 좋은 성능을 내겠지만, 영화 시나리오를 요약하는데는 전혀 맞지 않을 수 있기 때문이다. 논문의 실험부분에서 더 소개가 되는데 News관련 데이터셋으로 학습한 모델은 Non-news task에서는 좋은 성능을 내지 못했다.
Summarization을 수행하기 위해서는 input document와 그에 맞는 summary text가 쌍으로 활용되어야 한다. 하지만 단순히 extractive 방식으로 summary를 추출하게 되면 모델은 단순히 sentence를 copy하는 방식으로 학습이 되기 때문에, 저자는 최근 masking words와 contiguous spans의 성공에 영감을 받아 GSG를 수행한다고 설명한다.
GSG는 전체적으로 아래와 같은 방식으로 수행된다.
- Select and mask whole sentences form documents.
- Concatenate the gap-sentences into a pseudo-summary.
- The corresponding position of each selected gap sentence is replaced by a mask token [MASK1] to inform the model
여기서 gap sentence 비율은 GSR(Gap Sentences Ratio)에 의해 결정되는데 이는 문서의 전체 sentence에서 선택된 gap sentence의 비율을 의미하고, 다른 Masked Language Model에서의 mask rate와 유사한 개념이라고 생각하면 된다. 해당 논문에서는 GSR의 비율에 따른 성능을 실험하였는데 데이터셋에 따라 성능 편차가 있었지만, 최종적으로 GSR을 30%로 선택하였다고 한다.
Three primary strategies for gap-sentence
그렇다면 어떤 문장이 gap sentence로 선택이 되는걸까?
해당 논문은 적절한 Summarization을 위해서 gap sentence는 document내에서 다른 문장들(remaining sentence)에 비해 전체 문맥을 설명할 수 있는 중요한(important/principal) 문장이 선택되어야 한다고 한다. 이를 위해 Random, Lead, Principal이라는 3가지 전략을 사용한다.

Random은 말그대로 랜덤하게 m개의 sentence를 추출하는 것이고, Lead는 문서의 가장 첫 m개의 문장, Principal은 selected sentence와 remaining sentence간의 ROUGE1-F1 score를 기반으로 top-m개의 sentence를 선정하는 것을 말한다. (Principal 방법의 경우는 Ind/seq그리고 Orig/Uniq 옵션으로 세분화 되어 실험된다.)
아래는 document내에서 Random, Lead, Principal(Ing-Orig) 각각의 전략에 의해 선택된 sentence들을 보여준다.

Masked Language Model(MLM)
BERT에서는 input text의 15%의 token을 선택하여, 그 중 80%는 mask token으로 변환하고, 10%는 random token, 나머지 10%는 그대로 사용하게 된다.
위 첫번째 그림인 PEGASUS 모델의 아키텍처를 보면 GSG와 MLM이 동시에 적용되고 있는 것을 볼 수 있지만, 실제로는 MLM이 downstream task의 성능 향상에 영향을 주지 않아 최종 모델에서는 MLM을 포함하지 않았다고 한다.
Pre-training Corpus
pre-training을 위해 사용된 corpus는 C4와 HugeNews이다.
- C4(Colossal and Cleaned version of Common Crawl) : consist of text from 350M web-pages(750GB)
- HugeNews : a dataset of 1.5B articles (3.8TB) collected from news and news-like websites from 2013-2019
Downstream Tasks/Datasets
downstream summarization 및 재현 가능한 코드 제공을 위해 public datasets인 Tensorflow Summarization Datasets 데이터 셋을 활용하였다. 사용된 데이터 셋은 총 12개로 아래와 같다.
-Xsum
-CNN/DailyMail
-NEWSROOM
-Multi-News
-Gigaword
-arXiv
-PubMed
-BIGPATENT
-WikiHow
-Reddit TIFU
-AESLC
-BillSum
Experiments
효율적인 실험을 위하여 모델의 사이즈를 줄인 PEAGASUS-base모델(223M parameters)과 PEGASUS-large모델(568M parmeters)을 각각 비교한다.
PEAGASUS-base
- number of layers of encoder and decoder(L) : 12
- hidden size(H) : 768
- feed-forward layer size(F) : 3,072
- number of self-attention heads(A) : 12
PEGASUS-large
- number of layers of encoder and decoder(L) : 16
- hidden size(H) : 1024
- feed-forward layer size(F) : 4,096
- number of self-attention heads(A) : 16
Pre-Training Corpus
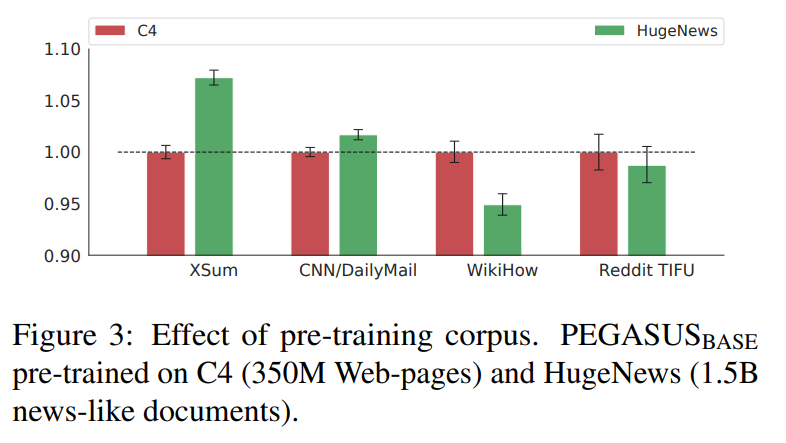
위 그림에서 볼 수 있듯이 학습시 사용된 Corpus가 무엇이냐에 따라 downstream task의 성능에 영향을 주게 된다.
HugeNews를 토대로 학습된 모델은 news 데이터 셋(XSum, CNN/DailyMail)에서는 높은 성능을 보여주고 있는 반면, non-news 데이터셋(WikiHow, Reddit TIFU)에서는 낮은 성능을 보여주고 있다.
EFFECT OF PRE-TRAINING OBJECTIVES
GSG의 성능비교를 위해 Lead, Random, Ing-Oig, Ing-Uniq, Seq-Orig, Seq-Uniq를 비교하였으며, GSR의 경우 데이터셋마다 성능 차이를 보이지만, 최종적으로 30%를 선택하였다.
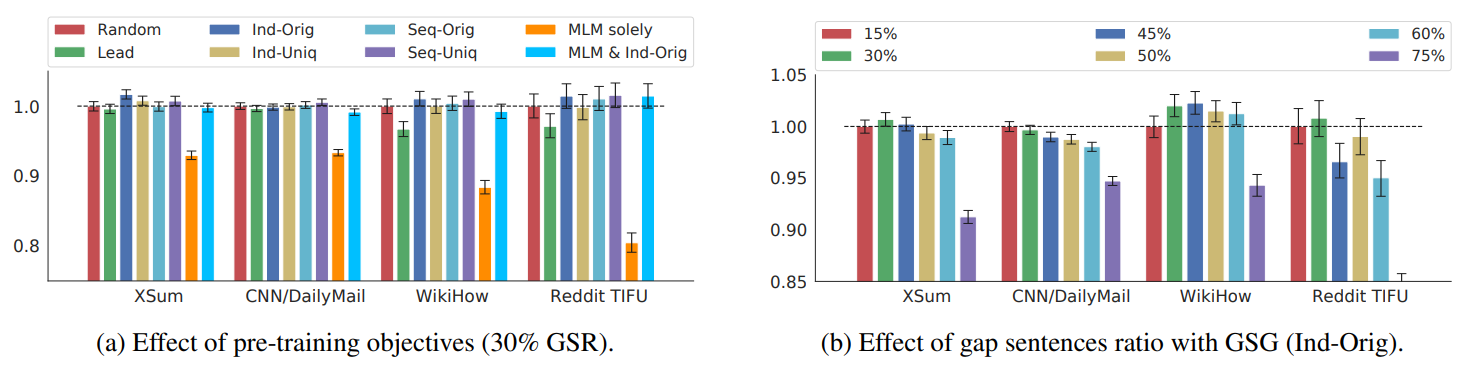
EFFECT OF VOCABULARY
실험을 위해 BPE(Byte-pair encoding)와 SentencePiece Unigram을 비교하였다.
비교결과 news 데이터셋에서는 BPE와 Unigram의 성능이 유사하였지만, non-news 데이터셋(especially WikiHow)에서는 SentencePiece Unigram모델이 훨씬 좋은 성능을 나타냈다.
위 그래프에서 볼 수 있듯이, WikiHow의 경우 Unigram이 128k일 때, Reddit TIFU는 64k일 때 best score를 나타내었기 때문에 이를 고려하여 최종적으로 SentencePiece Unigram을 사용하고 vocabulary size는 96k로 선정하였다.
Larger Model
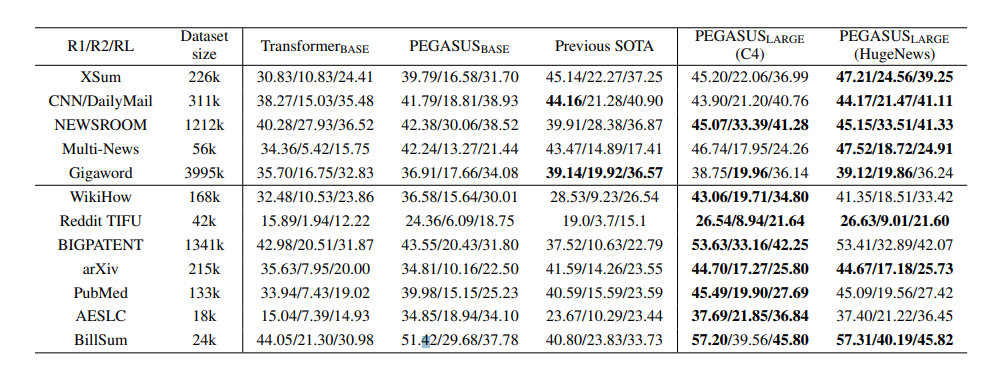
위 table에서 볼 수 있듯이, PEGASUS모델은 이전 SOTA모델 대비 모든 12개의 downstream tasks에서 모두 SOTA를 달성한 것을 확인할 수 있다.
Zero and Low-Resource Summarization
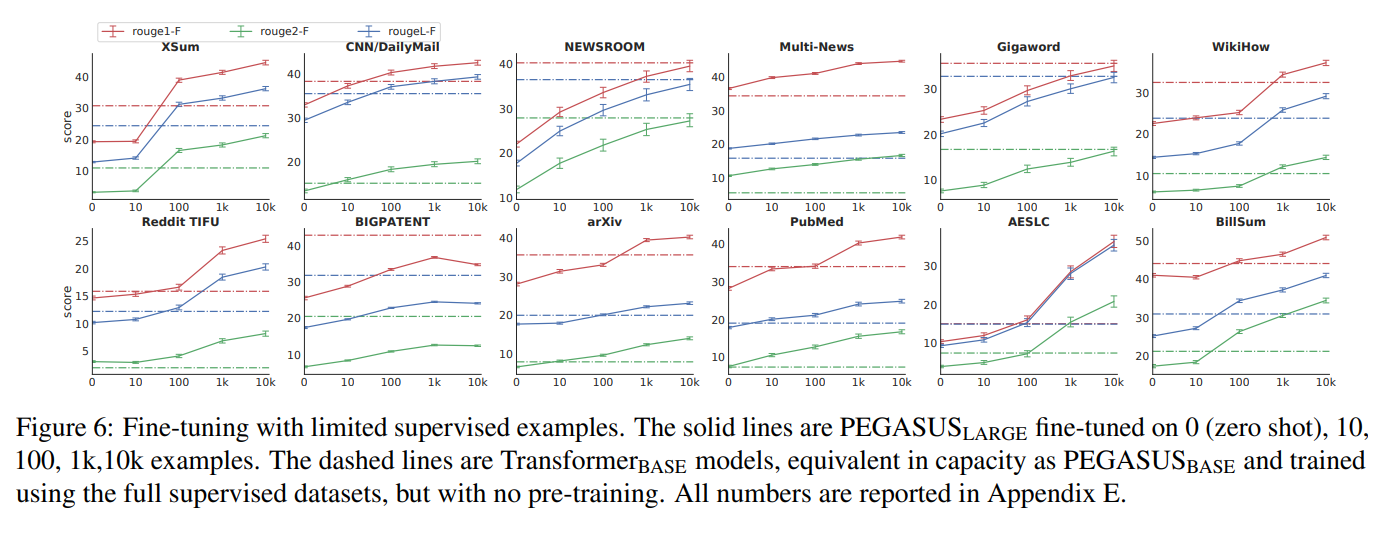
PAGASUS-large 모델을 2000 steps, 256 batch-size, 0.0005 learning-rate로 fine-tuning하였을 때, 단지 100개의 examples만으로도 기존 20k~200k개로 학습된 Transformer-base모델과 유사한 성능을 달성하였고, 1000개의 examples를 사용하였을때 12개 데이터 셋중 6개의 데이터 셋에서 SOTA를 달성할 만큼 기존 모델 대비 적은 비용으로 높은 성능을 달성하였다는 것이 큰 특징이다.
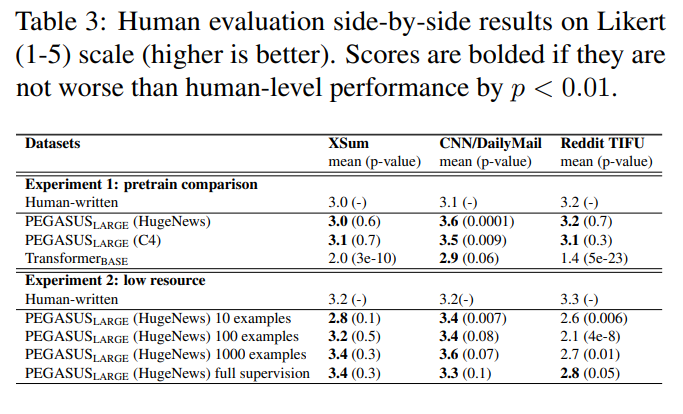
또한, 실제 사람이 만든 요약본과 PEGASUS-large모델이 만든 요약본은 비교한 결과를 보면, Reddit TIFU 데이터셋을 제외한 XSum, CNN/DailyMail 데이터셋에서는 PEGASUS-large모델이 만든 요약본이 사람이 만든 요약본보다 더 높은 성능을 나타냈다는 것이 특징이다.
Conclusion
정리해보자면 해당 논문의 큰 특징이라고 할 수 있는 점은,
첫째, Abstractive summmarization이라는 특정 task를 위해 GSG(Gap-Sentence Generation)라는 새로운 pre-training기법을 통해 적용한 점
둘째, GSG에서 principal sentence selection을 위해 다양한 방법을 적용한 점
셋째, 적은 리소스 비용(ex, 1000 examples)만으로도 대부분의 결과에서 SOTA를 달성한 점
인 것 같다. 그런데 여기서 의문이 들었던 점은 사람의 요약본과 성능 비교를 하는데 있어서 PEGASUS-large모델이 대부분 더 좋은 성능을 보였는데, 과연 human evaluation이 객관적으로 이루어졌는지 의문이 들었다. 각 task마다 3명의 평가자에 의해 1-5점으로 평가를 하였다고 하는데 과연 일반화 할 수 있을까?
여하튼, 최근 text summarization분야를 관심있게 보고 있었는데, summarization task에 최적화된 모델이 나왔다는 점에서 흥미가 갔던 논문이었다.
Reference
.jpeg)