Basic Object-Detection

Intro
Inflearn의 딥러닝 컴퓨터 비전 완벽 가이드를 수강하며 공부 목적으로 정리한 글입니다.
Computer Vision Techniques
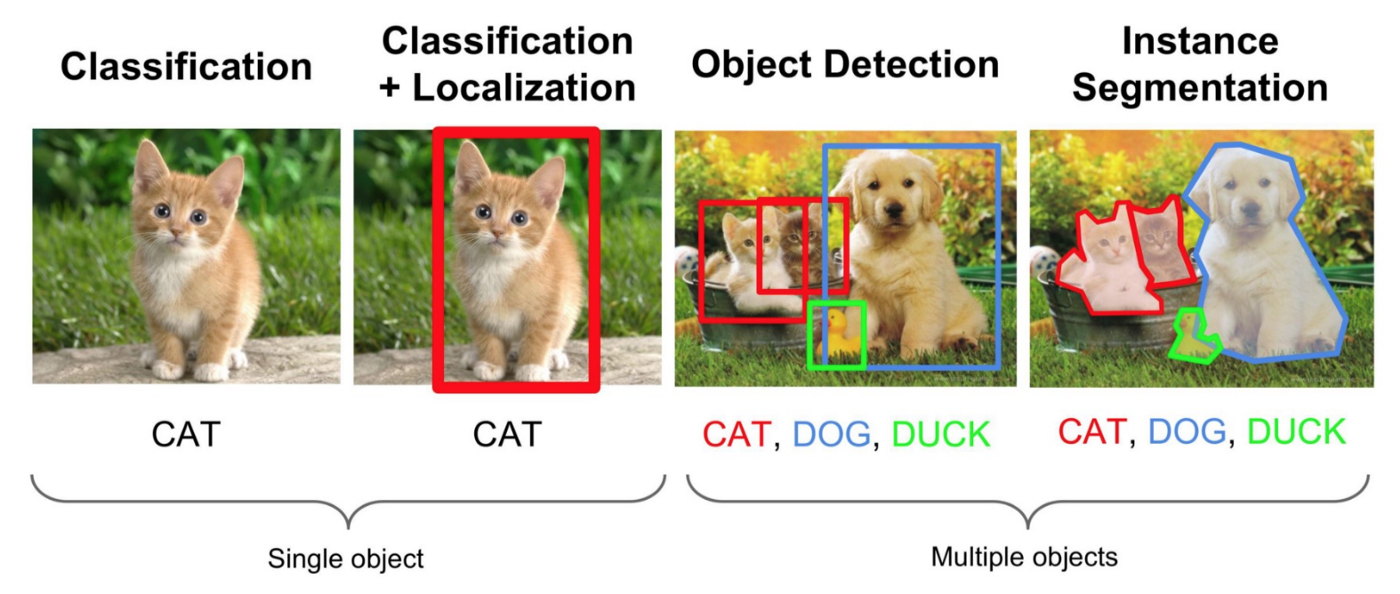
- Classification(분류) : 이미지에 있는 object가 무엇인지만 판별, 위치 고려 x
- Localization(발견) : object 판별 및 단 하나의 object 위치를 bounding box로 지정하여 찾음
- Detection(발견) : object 판별 및 여러 개의 object들에 대한 위치를 bounding box로 지정하여 찾음
- Segmentation(분할) : object 판별 및 Pixel 레벨의 detection을 통해 모든 픽셀의 레이블을 예측
Object Detection
History
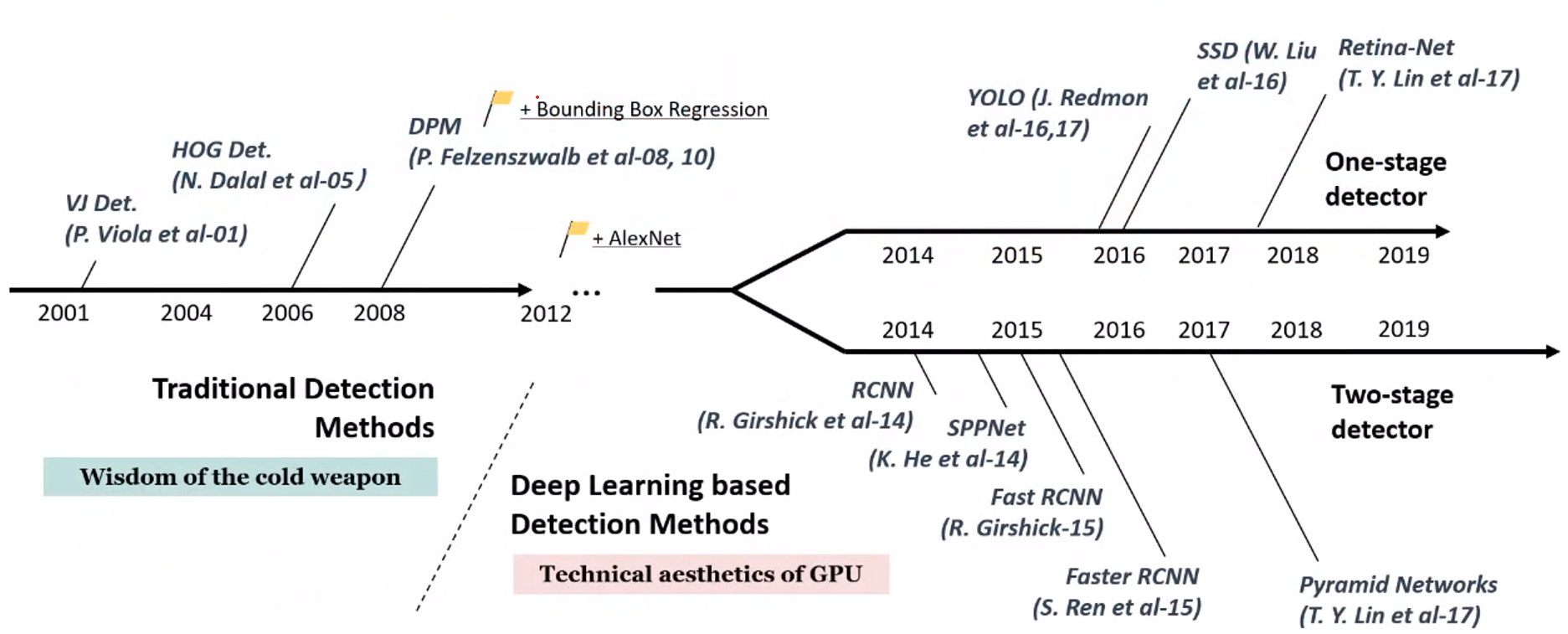
- 현재 YOLO 모델이 real-time 예측 측면에서 성능이 나쁘지 않아 실무에서 가장 많이 활용되고 있음
- real-time에는 한계가 있으나 가장 성능이 좋은 모델은 RetinaNet
Sliding Window 방식을 활용한 초기 object detection

- object detection의 초기 기법
- window를 왼쪽 상단에서부터 오른쪽 하단으로 이동시키면서 object를 detection하는 방식
- 오브젝트가 없는 역역도 무조건 슬라이딩하며 여러 형태의 window와 scale을 스캔해야 하므로 수행시간 및 성능이 효율적이지 않음
- Region Proposal 기법의 등장 이후 활용도가 떨어졌지만 object detection의 기술적 토대 제공
Obejct Detection의 주요 구성 요소 및 문제
주요 구성요소
- Region Proposal
- Detection을 위한 Network 구성(feature extraction, network prediction)
- detection을 위한 요소들(IoU, NMS, mAP, Anchor Box 등)
주요 문제
- 물체 판별(Classification) + 물체 위치 찾기(Regression)을 동시에 수행해야 함
- 한 이미지 내에 크기, 색, 생김새가 다양한 object가 섞여 있음
- 실시간 detection을 위해 시간 성능이 중요
- 명확하지 않은 이미지가 많음(노이즈 혹은 배경이 전부인 사진 등)
- 이미지 데이터 셋의 부족
Region Proposal(영역 추정)
- 목표 : Object가 있을 만한 후보 영역을 찾자!
- 대표적인 기법이 Selective Search
Selective Search
- Region Proposal의 대표적인 기법
- 컬러(color), 무늬(texture), 크기(size), 형태(shape) 등에 따라 유사한 region들을 계층적으로 그룹핑 하는 방법

Selective Search 수행 프로세스
- 초기 수 천개의 개별 Over segmentation된 모든 부분들을 bounding box로 만들어 region proposal 리스트에 추가
- 컬러(color), 무늬(texture), 크기(size), 형태(shape) 등에 따라 유사한 segment들을 그룹핑
- 위 과정을 반복하며 최종 그룹핑 된 segment들을 제안
Python을 통한 Selective Search 구현
pip install selectivesearch를 통해 라이브러리 설치
import selectivesearch
import cv2
img = cv2.imread('./image/test.jpg') # 이미지 로드
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb)
plt.show()
#selectivesearch.selective_search()는 이미지의 Region Proposal정보를 반환
_, regions = selectivesearch.selective_search(img_rgb,
scale=100, # bounding box scale
min_size=2000) # rect의 최소 사이즈
regions[:5][{'rect': (0, 0, 58, 257), 'size': 7918, 'labels': [0.0]},
{'rect': (16, 0, 270, 50), 'size': 5110, 'labels': [1.0]},
{'rect': (284, 0, 90, 420), 'size': 6986, 'labels': [2.0]},
{'rect': (59, 14, 262, 407), 'size': 3986, 'labels': [3.0]},
{'rect': (62, 17, 256, 401), 'size': 5282, 'labels': [4.0]}]반환된 regions 변수는 리스트 타입으로 세부 원소로 딕셔너리를 가지고 있음.
- rect 키값은 x,y 시작 좌표와 너비, 높이 값을 가지며 이 값이 Detected Object 후보를 나타내는 Bounding box임.
- size는 Bounding box의 크기
- labels는 해당 rect로 지정된 Bounding Box내에 있는 오브젝트들의 고유 ID
- 아래로 내려갈 수록 특성이 비슷한 것들이 합쳐지고, 너비와 높이 값이 큰 Bounding box이며 하나의 Bounding box에 여러개의 오브젝트가 있을 확률이 커짐.
# Bounding Box 시각화
green_rgb = (125, 255, 51)
img_rgb_copy = img_rgb.copy()
for rect in cand_rects:
left = rect[0]
top = rect[1]
# rect[2], rect[3]은 너비와 높이이므로 우하단 좌표를 구하기 위해 좌상단 좌표에 각각을 더함.
right = left + rect[2]
bottom = top + rect[3]
img_rgb_copy = cv2.rectangle(img_rgb_copy, (left, top), (right, bottom), color=green_rgb, thickness=2)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb_copy)
plt.show()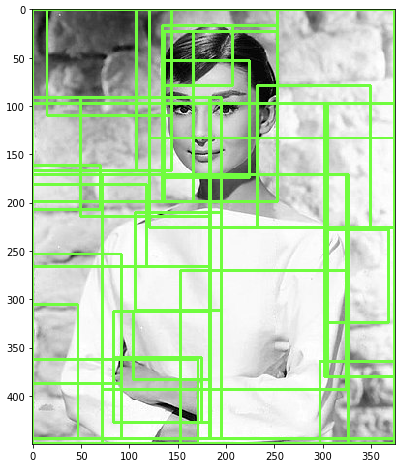
IoU(Intersection over Union)
모델이 예측한 bounding box와 실제 ground truth box가 얼마나 정확하게 겹치는지를 측정하는 지표
- 아래와 같은 지표로 계산 되며
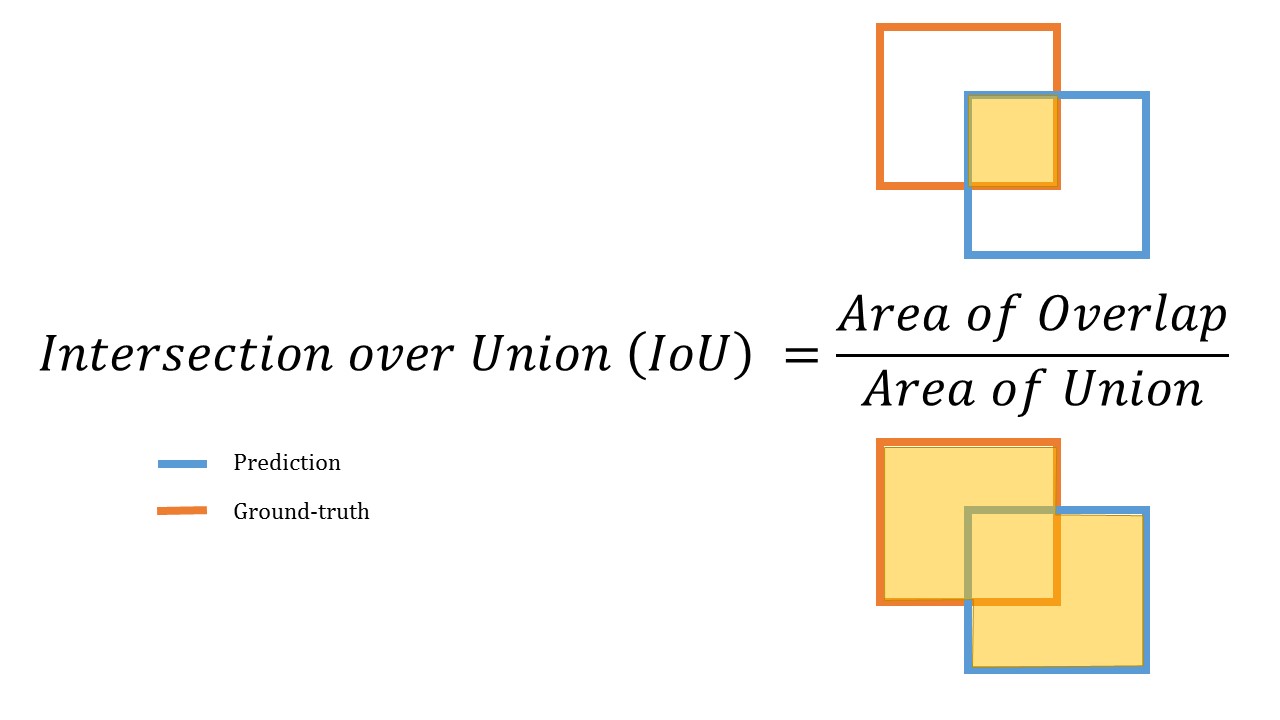
- 100%로 정확하게 겹쳐질 때의 값은 1이 됨
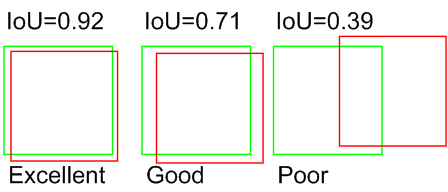
IoU 값에 따라 detection 예측 성공 결정
- object detection에서 개별 object에 대한 검출 예측이 성공하였는지에 대한 여부를 IoU를 통해 결정
- 일반적으로 PASCAL VOC Challenge에서 는 IoU가 0.5이상이면 예측 성공했다고 판단
Python을 통한 IoU 계산
def compute_iou(cand_box, gt_box):
# Calculate intersection areas
x1 = np.maximum(cand_box[0], gt_box[0])
y1 = np.maximum(cand_box[1], gt_box[1])
x2 = np.minimum(cand_box[2], gt_box[2])
y2 = np.minimum(cand_box[3], gt_box[3])
intersection = np.maximum(x2 - x1, 0) * np.maximum(y2 - y1, 0) # width * height (x2에서 x1을 뺀 값이 width, y2에서 y1을 뺀 값이 height 이므로)
cand_box_area = (cand_box[2] - cand_box[0]) * (cand_box[3] - cand_box[1]) # width * height
gt_box_area = (gt_box[2] - gt_box[0]) * (gt_box[3] - gt_box[1]) # width * height
union = cand_box_area + gt_box_area - intersection # 실제box와 예측box의 합에서 intersection을 뺌
iou = intersection / union
return iou- 실제 bounding box와 후보 bounding box가 있을 때, 둘 중에서 x1과 y1좌표는 max값, x2와 y2좌표는 min값을 선택하게 되면 그 좌표가 Intersection area가 되며
- 두 개의 box를 더한 후 intersection을 빼준 값이 Union area
- 마지막으로 intersection을 union으로 나누어 주면 IoU값을 얻을 수 있음
NMS(Non Max Suppression)
object detection 시 최대한 object를 놓치지 않기 위해 많은 bounding box를 찾게 되는데, 이렇게 detected 된 수많은 bounding box 중 비슷한 위치에 있는 box를 제거하고 가장 적합한 box를 선택하는 기법

NMS 수행 프로세스
- Detected 된 Bounding box별로 특정 Confidence score threshold 이하 bounding box는 먼저 제거 (ex. confidence score threshold < 0.5)
- 가장 높은 confidence score를 가진 box 순으로 내림차순 정렬하고 아래 로직을 모든 box에 순차적으로 적용
- 높은 confidence score를 가진 box와 겹치는 다른 box를 모두 조사하여 IoU가 특정 threshold 이상인 box를 모두 제거 (ex. IoU Threshold > 0.4)
- 남아있는 box만 선택
Confidence score threshold가 높을 수록, IoU Threshold가 낮을 수록 많은 box가 제거 됨
Object Detection 성능 평가
mAP(mean Average Precision)
-
실제 Object가 detected된 재현율(recall)의 변화에 따른 정밀도(precision)의 값을 평균한 성능 수치
정밀도와 재현율
-
정밀도는 모델이 positive라고 예측한 대상 중 예측 값이 실제 positive 값과 얼마나 일치하는지에 대한 비율(즉, 예측한 object가 실제 object들과 얼마나 일치하는지)
-
재현율은 실제 positive 값 중 모델이 얼마나 실제 값을 positive라고 예측했는지에 대한 비율(즉, 실제 object를 얼마나 빠드리지 않고 잘 예측했는지)
-
Precision Recall Trade-off : 정밀도와 재현율은 상호 보완적인 관계이므로 어느 한쪽이 높아지면 다른 쪽이 낮아지게 됨
-
Precision-Recall Curve : confidence threshold의 변화에 따른 정밀도와 재현율의 변화 곡선, 이 곡선의 아랫부분 면적을 AP(Averge Precision, 평균 정밀도)라고 함
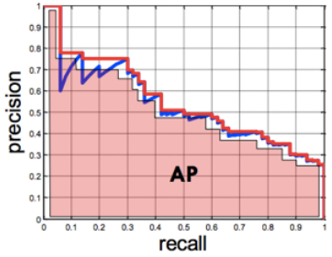
-
AP는 하나의 object에 대한 성능 수치이며, mAP는 여러 object들의 AP를 평균한 값을 의미
Image Resolution / FPS / Detection 성능 상관 관계
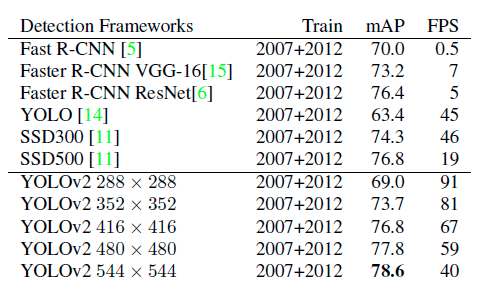
일반적으로 이미지 해상도(Image Resolution)가 높을 수록 Detection성능이 좋아지지만 이미지를 처리하는 시간(FPS)이 오래걸림
- High Resolution -> High Detection Score -> Low FPS
- Low Resolution -> Low Detection Score -> High FPS
Object Detection을 위한 주요 데이터 셋
- Pascal-VOC - XML format, 20개의 오브젝트 카테고리
- MS-COCO - json format, 80개의 오브젝트 카테고리
- Google Open Images - csv format, 600개의 오브젝트 카테고리
.jpeg)