Autoencoder와 LSTM Autoencoder

Intro
대표적인 자기 지도 학습인 Autoencoder와 Autoencoder에 LSTM cell을 적용해 시퀀스 학습이 가능한 LSTM Autoencoder에 대해 소개한다. 이후 다음 포스팅에는 LSTM Autoencoder를 통해 미래에 발생 할 고장이나 이상신호를 조기 예측하기 위한 Anomaly Detection 방안에 대해 소개할 것이다.
1. Autoencoder?
오토인코더는(autoencoder)는 라벨이 없는 훈련 데이터를 사용한 학습(즉, 지도 학습) 없이도 입력 데이터의 표현을 효율적으로 학습할 수 있는 인공신경망이다. 오토인코더는 아래 그림과 같이 input 레이어, hidden 레이어, output 레이어로 구성되어 있으며 일반적으로 Input 유닛보다 훨씬 낮은 차원의 hidden 유닛을 가지므로 주로 차원 축소(Dimensionality Reduction) 목적으로 사용된다. 또한 오토인코더는 강력한 feature extractor로 작동하기 때문에 비지도 사전훈련에 사용될 수 있고, 훈련 데이터와 매우 비슷한 새로운 데이터를 생성하는 생성 모델(generative model)로서 사용될 수 있다.
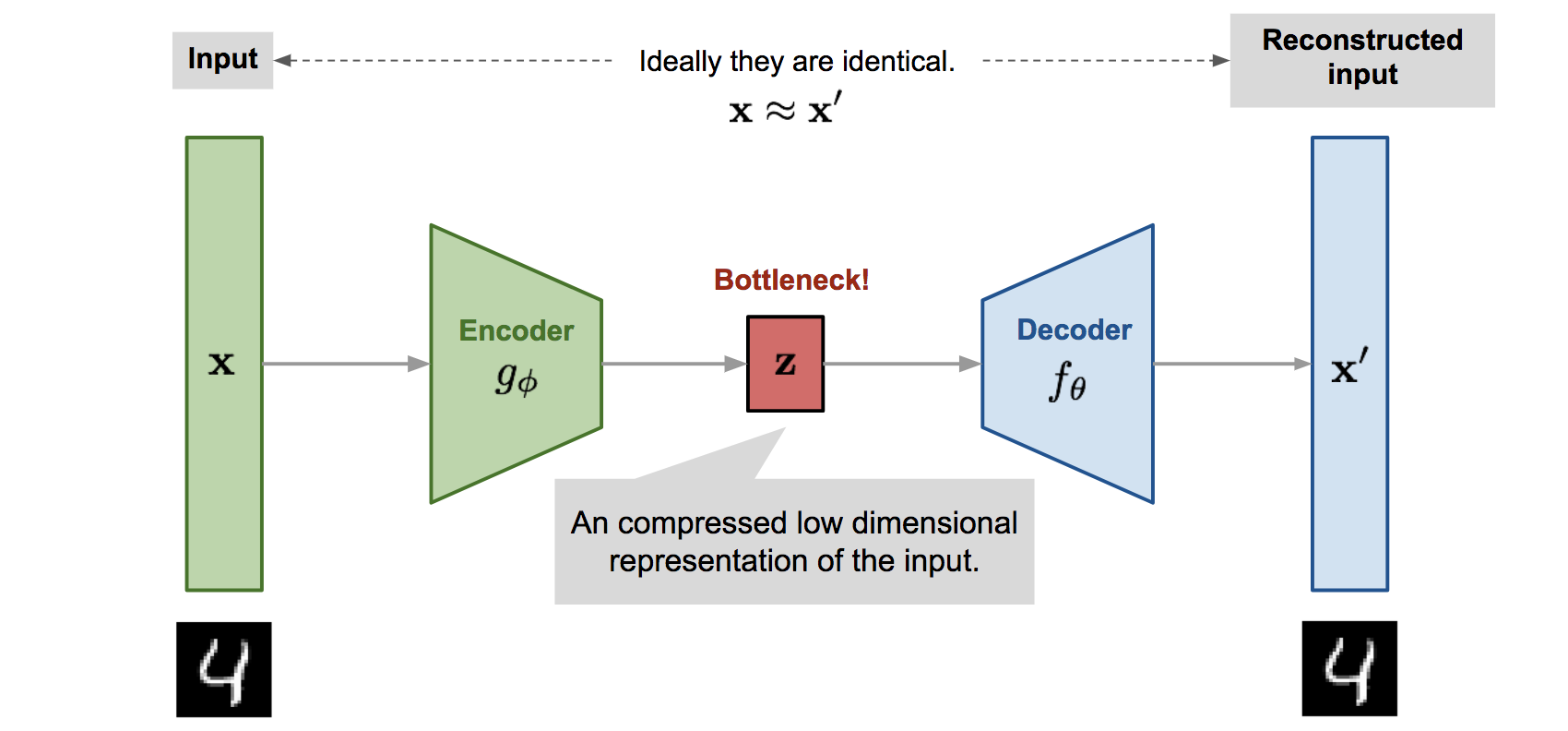
오토인코더가 학습하는 것은 단순히 입력을 출력으로 복사하는 것이다. 하지만 그 과정에서 여러 방법의 제약(내부 표현 크기 제한, 입력 잡음 추가 등)을 통해 오토인코더가 단순히 입력을 바로 출력으로 복사하지 못하도록 막고, 데이터를 효율적으로 재표현(representation)하는 방법을 학습하도록 제어한다. 오토인코더는 인코더(encoder)와 디코더(decoder)로 구분된다.
- 인코더(encoder) : 인지 네트워크(recognition network)라고도 하며, 입력을 내부 표현으로 변환
- 디코더(decoder) : 생성 네트워크(generative network)라고도 하며, 내부 표현을 출력으로 변환
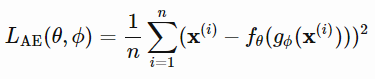
오토인코더가 입력을 재구성하기 때문에 출력을 재구성(reconstruction)이라고 부르며, 입력과 재구성된 출력과의 차이를 계산하여 재구성 손실(reconstruction loss)이라고 한다. 여기서 파라미터 (θ,φ)는 encoder에 입력되는 original input (x)과 디코더를 통해 출력 된 reconstruced input (f(g(x))이 같아지도록 학습하며 업데이트 된다.
1.1. Stacked Autoencoder
여러 개의 hidden 레이어를 가진 경우를 적층 오토인코더(stacked autoencoder)라고 한다. 아래 그림와 같이 레이어를 더 추가할 경우 오토인코더는 더 복작한 표현을 학습할 수 있게 되며 일반적으로 적층 오토인코더는 추가된 hideen 레이어를 기준으로 인코더와 디코더는 대칭 구조를 이룬다.
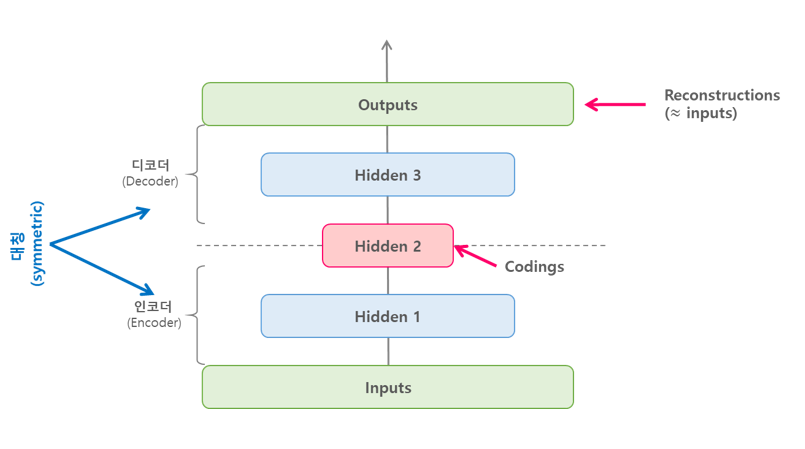
위와 같이 오토인코더가 완벽하게 대칭 구조를 이룰 때는 일반적으로 인코더와 디코더의 가중치를 묶게 되는데 이렇게 할 경우 모델의 가중치 수를 절반으로 줄여 훈련속도를 높이고 overfitting 위험을 줄일 수 있다고 한다.
1.2. Denoising Autoencoder
위에서 살펴보았던 Stacked Autoencoder의 경우 다수의 hidden 레이어와 노드가 추가 될 경우 overfitting 자신에 대한 표현을 세밀하게 학습하게 되는 overfitting 문제에 직면할 수 있다. 이를 해결하기 위한 한 가지 방법으로 제안된 것이 Denoising Autoencoder(Vincent et al. 2008)이다. 이 모델은 말 그대로 모델에 학습되기 전 Input 데이터에 잡음(noise)을 주어 모델이 데이터 표현을 학습하기 힘들게 만든다.
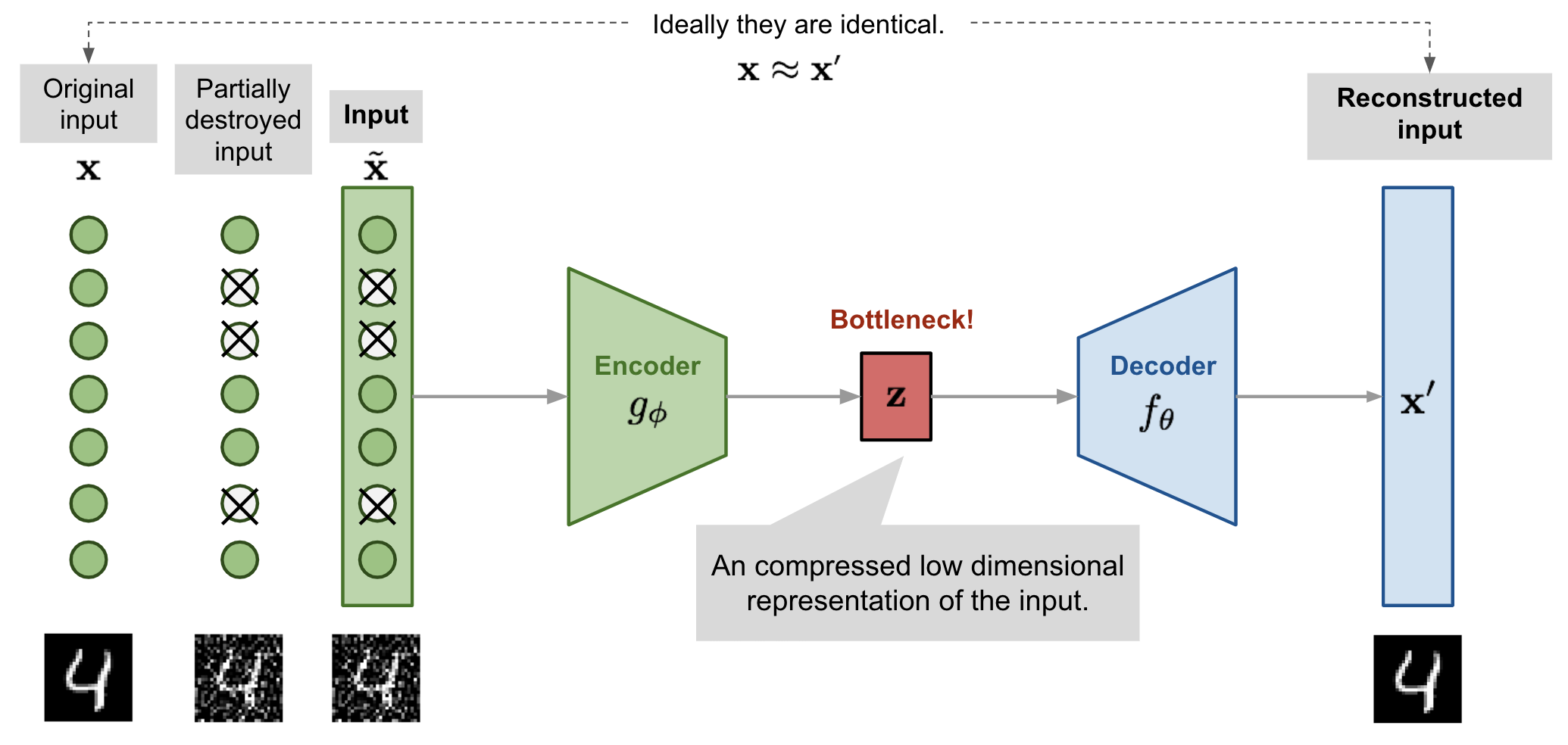
이렇게 하는 이유는 모델을 일반화하기 위한 목적이며, 노이즈 즉, 제약이 있는 상황에서도 데이터를 효울적으로 복원하기 위함이다. 이때 잡음을 주기 위한 방법은 여러가지가 있지만 해당 논문에서는 아래와 같이 데이터의 일부가 삭제된 input(x~) 를 넣어 이 x~가 출력 된 reconstruced input(x')과 유사해지도록 학습하는 것이다.
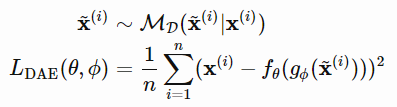
2. LSTM Autoencoer
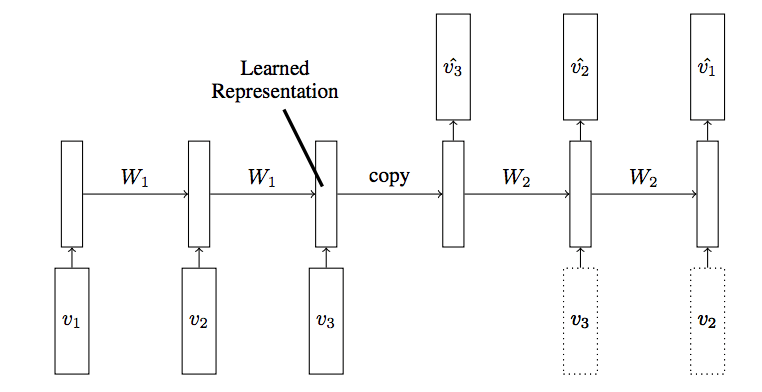
LSTM Autoencoder는 시퀀스(sequence) 데이터에 Encoder-Decoder LSTM 아키텍처를 적용하여 구현한 오토인코더이다. 아래 그림은 LSTM 오토인코더의 구조이며 입력 시퀀스가 순차적으로 들어오게 되고, 마지막 입력 시퀀스가 들어온 후 디코더는 입력 시퀀스를 재생성하거나 혹은 목표 시퀀스에 대한 예측을 출력한다.
2.1 Reconstruction LSTM Autoencoder
재구성(reconstruction)을 위한 LSTM Autoencoder 구조이다. 즉, input과 최대한 유사하게 output을 디코딩하며, LSTM 학습을 위해 데이터를 우선 (samples, timesteps, feature)와 같은 3d형태로 변환한다. input 레이어의 feature는 1차원으므로 output 레이어도 동일한 차원으로 구성하여 출력되도록 한다.
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras import Model ,models, layers, optimizers, utils# define input sequence
sequence = np.array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
# reshape input into [samples, timesteps, features]
n_in = len(sequence)
sequence = sequence.reshape((1, n_in, 1))
# define model
model = models.Sequential()
model.add(layers.LSTM(100, activation='relu', input_shape=(n_in, 1)))
model.add(layers.RepeatVector(n_in))
model.add(layers.LSTM(100, activation='relu', return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(1)))
model.compile(optimizer='adam', loss='mse')
# fit model
model.fit(sequence, sequence, epochs=300, verbose=0)
# predict
yhat = model.predict(sequence)
yhatarray([[[0.10559099],
[0.20217314],
[0.30041453],
[0.39952287],
[0.49908453],
[0.5987617 ],
[0.69832975],
[0.7991052 ],
[0.9024458 ]]], dtype=float32)2.2 Prediction LSTM Autoencoder
시계열적 예측을 위한 LSTM 구조이며 input 시퀀스는 현재 시점(t) output 시점은 (t+1)로 두어 한 시점 앞을 학습하도록 데이터를 구성한다. 여기서 autoencoder는 학습 시 encoder에는 t 시점이 입력되지만 decoding 후에는 (t+1)시점과 reconstruction error를 계산하며 결국 t 시점이 t+1 시점을 학습하게 된다.
결과적으로 예측 결과는 1이 입력되면 2와 가까운 수를, 2가 입력되면 3과 가까운 수를 예측하게 된다.
# define input sequence
seq_in = np.array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
# reshape input into [samples, timesteps, features]
n_in = len(seq_in)
seq_in = seq_in.reshape((1, n_in, 1))
# prepare output sequence
seq_out = seq_in[:, 1:, :]
n_out = n_in - 1
# define model
model = models.Sequential()
model.add(layers.LSTM(100, activation='relu', input_shape=(n_in, 1)))
model.add(layers.RepeatVector(n_out))
model.add(layers.LSTM(100, activation='relu', return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(1)))
model.compile(optimizer='adam', loss='mse')
# fit model
model.fit(seq_in, seq_out, epochs=300, verbose=0)
# predict
yhat = model.predict(seq_in)
yhatarray([[[0.16683361],
[0.2898971 ],
[0.403169 ],
[0.5089176 ],
[0.6094323 ],
[0.7060289 ],
[0.7997408 ],
[0.89148134]]], dtype=float32)2.3 Composite LSTM Autoencoder
Reconstruction과 Prediction 모델을 통합한 모델이다. 모델의 통합을 위해 예제에서는 keras functional api를 활용하였으며, 결과적으로 출력 시 reconstruction결과와 prediction결과가 함께 출력된다.
# define input sequence
seq_in = np.array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
# reshape input into [samples, timesteps, features]
n_in = len(seq_in)
seq_in = seq_in.reshape((1, n_in, 1))
# prepare output sequence
seq_out = seq_in[:, 1:, :]
n_out = n_in - 1
# define encoder
visible = layers.Input(shape=(n_in, 1))
encoder = layers.LSTM(100, activation='relu')(visible)
# define reconstruct decoder
decoder1 = layers.RepeatVector(n_in)(encoder)
decoder1 = layers.LSTM(100, activation='relu', return_sequences=True)(decoder1)
decoder1 = layers.TimeDistributed(layers.Dense(1))(decoder1)
# define predict decoder
decoder2 = layers.RepeatVector(n_out)(encoder)
decoder2 = layers.LSTM(100, activation='relu', return_sequences=True)(decoder2)
decoder2 = layers.TimeDistributed(layers.Dense(1))(decoder2)
# concat model
model = Model(inputs=visible, outputs=[decoder1, decoder2])
model.compile(optimizer='adam', loss='mse')
# utils.plot_model(model, show_shapes=True, to_file='composite_lstm_autoencoder.png')
# fit model
model.fit(seq_in, [seq_in, seq_out], epochs=300, verbose=0)
# predict
yhat = model.predict(seq_in)
yhat[array([[[0.10127164],
[0.19949059],
[0.29943317],
[0.39987874],
[0.50023794],
[0.60028654],
[0.7000689 ],
[0.79983366],
[0.89999163]]], dtype=float32), array([[[0.19868489],
[0.30206183],
[0.3981459 ],
[0.4989811 ],
[0.600592 ],
[0.7013527 ],
[0.80077535],
[0.8988221 ]]], dtype=float32)]References
.jpeg)