📝 세번째 시도
Dataset
데이터 불균형 해소
- Normal 200개 (train 160, test 40)
- Abnormal 200개 (train 160, test 40)
- Arson 50개 (train 40, test 10)
- Assault 50개 (train 40, test 10)
- Fighting 50개 (train 40, test 10)
- Shooting 50개 (train 40, test 10)
- 추출되어 있는 I3D feature data(npy) 사용 - train, test data
- test data의 anomaly annotation txt file 사용
- test data annotation 없는 경우 직접 생성
- list 파일: train, test numpy data의 경로 표시
- test data ground truth(gt.npy) 생성
Hyperparameter
- dropout: 0.2, 0.5, 0.7
- batch size: 16
- learning rate: 0.001, 0.01
- epoch: 30, 100
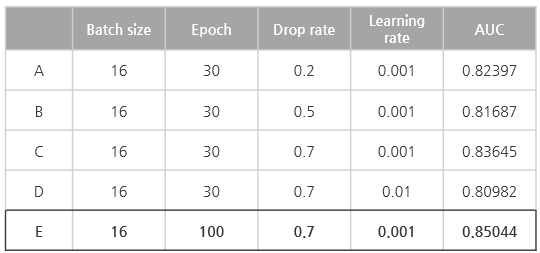
모델 성능 비교
CASE 1: dropout rate
batch size: 16, learning rate 0.001, epoch: 30 고정
① dropout 0.2 → recall : 0.87203, ROC AUC : 0.82397
② dropout 0.5 → recall : 0.77679, ROC AUC : 0.81687
③ dropout 0.7 → recall : 0.83758, ROC AUC : 0.83645
CASE 2: learning rate
batch size: 16, epoch: 30, dropout 0.7 고정
① dropout 0.001 → recall : 0.83758, ROC AUC : 0.83645
② dropout 0.01 → recall : 0.76915, ROC AUC : 0.80982
CASE 3: epoch
batch size: 16, learning rate 0.001, dropout 0.7고정
① epoch 30 → recall : 0.83758, ROC AUC : 0.83645
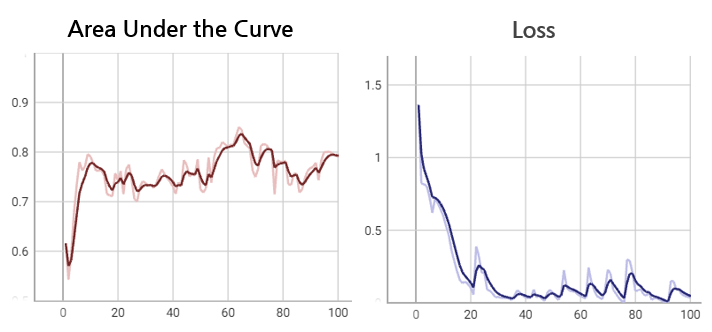
③ epoch 100 → recall : 0.80138, ROC AUC : 0.85044
Review
- CASE E
추후 계획
- 이미 학습된 모델로 무기 데이터를 학습할 수 있을지 찾아보기
- 새로운 영상으로 모델 테스트
- 이상행동이 나타나면 알려주는 시스템
