📝 첫번째 시도
Dataset
- UCF dataset의 클래스도 많고, 용량도 커서 전체 데이터를 사용하지 못했다.
- Normal events 350개(train 200, test 150)
- Robbery 150개(train 145, test 5)
Hyperparameter
- dropout_rate: 0.7
- lr: [0.001]*15000
- batch_size: 16
- workers: 0
- num_classes: 2
- max_epoch: 100
모델 성능
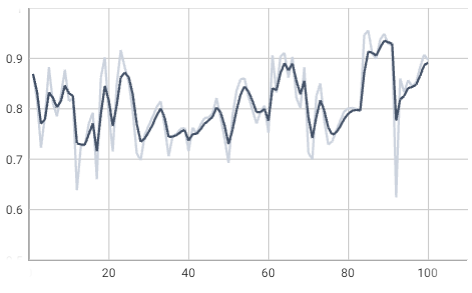
ROC AUC
- epoch: 85, 95.5%
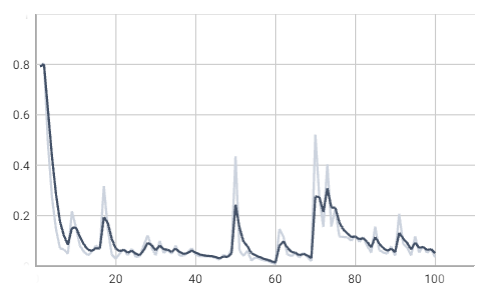
loss
Review
- github에서 다른 사람이 진행했던 결과를 보면 성능이 90% 이상 나오지 않았던게 기억이 났다. test data에 normal events가 너무 많지 않았나 싶다.
📝 두번째 시도
Dataset
- Normal 300개 (train 250, test 50)
- Abnormal 300개 (train 264, test 36)
- Assault 50개 (train 47, test 3)
- Fighting 50개 (train 45, test 5)
- Robbery 150개 (train 145, test 5)
- Shooting 50개 (train 27, test 23)
- 추출되어 있는 I3D feature data(npy) 사용 - train, test data
we oversample each video frame with the “10-crop” augment
“10-crop” means cropping images into the center, four corners, and their mirrored counterparts.- reference: https://github.com/carolchenyx/MGFN.
- list 파일: train, test numpy data의 경로 표시
- test data의 anomaly annotation txt file 사용
- test data ground truth(gt.npy) 생성
ground truth: 데이터의 실제 값
Hyperparameter
- dropout: 0.7, 0.5, 0.3
- batch size: 16, 32
- epoch: 50, 100
모델 성능 비교
CASE 1: dropout
- batch size: 16
- epoch: 30
- dropout
① 0.3: ROC-AUC 0.78210 (epoch 8)
② 0.5: ROC-AUC 0.80105 (epoch 3)
③ 0.7: ROC-AUC 0.81714 (epoch 11) 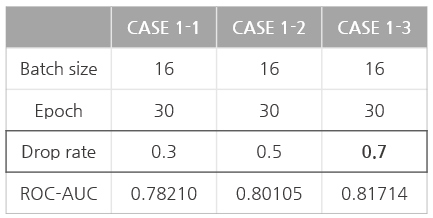
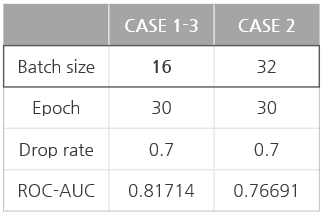
CASE 2: batch size
- batch size: 32
- epoch: 30
- dropout: 0.7
- best: ROC-AUC 0.76691 (epoch 10)
CASE 3: epoch
- batch size: 16
- dropout: 0.7
- epoch
① 50: ROC-AUC 0.79154 (epoch 3)
② 100: ROC-AUC 0.78195 (epoch 19) 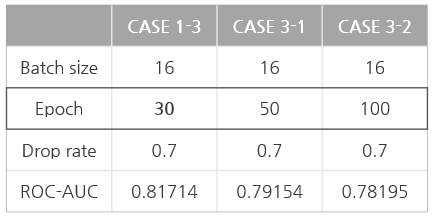
참고
- AUC(area under the curve): ROC curve 아래의 면적으로 1에 가까울수록 좋다.
- ROC(receiver operating characteristic): FPR이 변할 때 TPR의 변화를 그린 그림으로 모든 임계값에서 분류 모델의 성능을 보여준다.
- RECALL(TPR: True positive ratio, sensitivity): 실제 이상행동 데이터들 중에서 이상행동이라고 예측한 경우
- FALL-OUT(FPR: False positive ratio): 실제 이상행동이 아닌데 이상행동이라고 잘못 예측한 경우
Review
- 학습이 진행되면서 성능이 눈에 띄게 좋아지지는 않았다.
- epoch 100보다 epoch 30의 성능이 더 좋았다.
- github에서 이미 학습을 진행했던 다른 사람들은 epoch 500 이상이 되어야 성능이 좋아진다고 한다..
추후 계획
- 코드 추가하기
annotation file 만드는 코드 작성 → 완료
I3D feature extraction 코드 → 추출된 데이터랑 제공된 데이터랑 다르다. - 데이터 불균형 어느정도 줄인 다음에 모델 다시 학습
