AI TECH lv1 Pstage
부스트캠프 ai tech에서 7주간의 level1 과정은 pstage로 마무리 되었다. 대회 형식의 프로젝트를 경험하면서 문제를 인식하고 그것을 ai를 통해 해결해보는 하나의 전체적인 경험을 한다.

사람의 이미지가 input으로 입력되면 마스크 착용 여부와 성별, 연령대에 따라 분류하는 모델을 설계해야 했다.
총 4500명, 각 사람에 대해 7장의 이미지가 주어졌다. (31500장)
이 중 60%는 training에, 40%는 평가에 사용되었는데 20%는 public test set, 20%는 private test set으로 사용되었다.
대회 종료 전까지 실시간 리더보드 점수는 public test set 기준으로, 대회 종료 시점엔 private set으로 평가되었다.
프로젝트를 시작하며
데이터에 더해 베이스라인 코드가 주어졌다. 코드를 공개할 순 없으나 그 구성을 간략히 설명하자면 augmentation을 포함한 dataset, cross-entropy 등이 포함된 loss, 아주 간단한 cnn 모델만 준비된 model, train, inference 등으로 구성되었다.
프로젝트를 시작하며 전체적인 그림을 그리기 위해 두가지를 시작했다.
1. 문제 정의와 데이터 파악
2. 베이스라인 코드 분석
문제 정의 및 데이터 파악
level1 Ustage를 통해 데이터의 중요성을 알고 있었다. 데이터가 어떤 식으로 준비되어 있는지, 발생가능한 문제가 있는지, 개선할 방안은 무엇이 있는지 파악해야 했다.
1명당 7장의 사진이 주어졌는데 5장은 마스크를 올바르게 착용한 사진, 1장은 잘못 착용한 사진, 1장은 아예 착용하지 않은 사진이었다.
데이터를 쭉 훑어보면서 mislabeling된 데이터를 수정해나갔다. 폴더명, 파일명으로 imageID, gender, age, race, mask 착용 상태에 대한 정보가 주어졌는데 남자 사진인데 여자라고 표기되어 있거나, 마스크 착용 상태에 대한 라벨이 잘못된 데이터들을 고쳤다. 이 과정에서는 토론 게시판에서 공유된 다른 캠퍼분들의 방식을 참고하면서 도움을 받았다.
mislabel 외에 데이터 분포에 문제가 있었다.
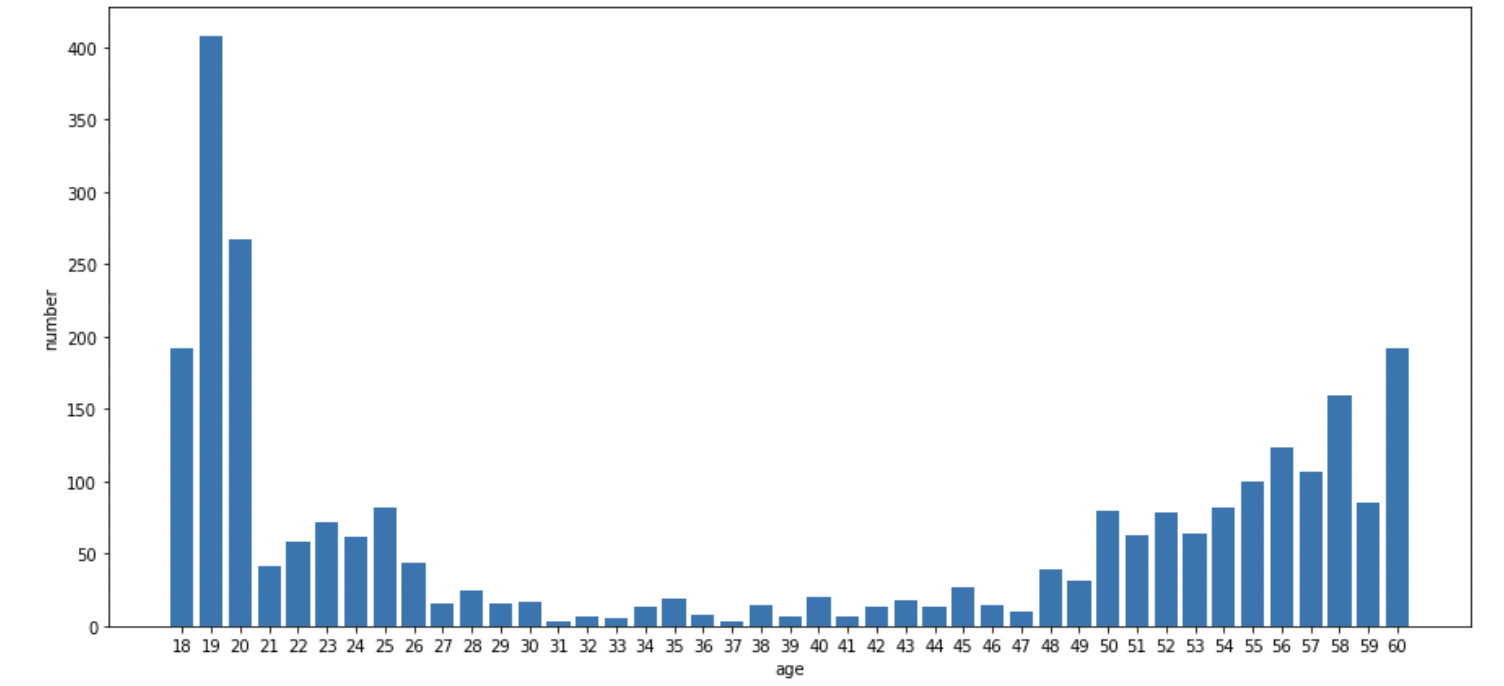
연령대를 '30세 미만', '30세 이상 60세 미만', '60세 이상'의 세가지 카테고리로 구분해야 했다. 하지만 60세 이상의 데이터가 현저히 부족했다. 이는 연령대 예측에 문제가 될 수 있었다. (그리고 실제로 문제가 되었다)
또 연령대 파악이 생각보다 어렵다는 문제가 있었다. 사진과 라벨을 보면서 사람의 눈으로도 연령대를 파악하기 어렵다는 생각을 했다. 목소리, 말투, 행동 등의 정보 없이 얼굴 중심의 사진 하나만으로는 연령대를 파악하기 어려웠다.
베이스라인 코드 분석
베이스라인 코드를 보며 왜 이런 식으로 코드를 짰을지 생각하려 했다. 모듈화가 잘 되어있는 코드였는데 보면서 코드를 어떤 식으로 짜야하는지 감을 잡을 수 있었다. 이 뼈대에서 augmentation 기법을 추가하거나 loss function을 수정하고, 모델을 추가하는 등 살을 붙여나갔다.
이미지 전처리
사진을 쭉 훑어보다 보니 얼굴 중심으로 사진은 잘 찍혀있었으나 학습에 필요치 않은 배경 등도 같이 찍혀있다는 생각을 했다.
마스크 착용상태, 성별, 연령대를 분류하는 데에 배경 정보는 필요없으니 CenterCrop을 통해 얼굴 부분만 잘라냈다.
실제로 이 과정만으로도 f1 score 0.7 정도가 달성되었다.
후에 연령대 파악이 어렵다는 문제를 인식하고 주어진 데이터에서 그나마 얻을 수 있는 정보를 최대한 활용하기 위해 얼굴뿐만 아니라 상의의 복장 정보까지 학습에 이용할 수 있도록 했다. Lambda를 통해 원하는 부분을 crop했다.
이를 통해 약 0.01~0.02 정도의 f1 score 상승을 얻을 수 있었다.
(대회 종료 후 상위권 팀이 사용한 idea를 공유했는데 배경을 검게 칠하는 방식의 전처리를 했다고 했다. 그 방법이 더 좋은 방법이라고 생각했다.)
좀 더 좋은 일반화 성능을 위해 RandomGrayscale을 추가했다. 0.1의 기본값을 사용했는데 0.01~0.02의 f1 score 상승이 있었다.
후술하겠지만 최종적으로 0.73 정도의 f1 score를 얻을 수 있었다.
모델
처음에 사용해본 모델은 ViT였다. 하지만 f1 score는 0.6 정도에 머물렀다. 당시 리더보드에는 0.7 정도의 f1 score를 얻은 팀들이 많았으므로 ViT는 적절한 모델이 아니라고 생각했다. ViT에 대한 논문도 리뷰했었는데 아무래도 거대한 데이터셋에 대해서는 좋은 성능을 얻을 수 있지만 18900개의 데이터로는 그정도 성능을 기대할 수 없다고 생각했다. CNN 기반 모델이 가지는 inductive bias가 없기 때문에 적은 수의 데이터에 대해서 좋은 성능을 낼 수 없다고 생각했다.
다음으로 시도해본 모델은 ResNet과 EfficientNet이었다. 두 모델 다 적은 수의 데이터로도 좋은 성능을 낸다고 알려져 있었기 때문이다. 다른 팀원분이 ResNet으로 실험을 진행하셔서 EfficientNet을 선택했다.
결과는 꽤나 좋았다. 0.7 정도의 f1 score를 냈다. epochs 10번 정도로 해당 점수에 도달했는데 EfficientNet은 이름대로 빠른 학습 속도를 보여줬다.
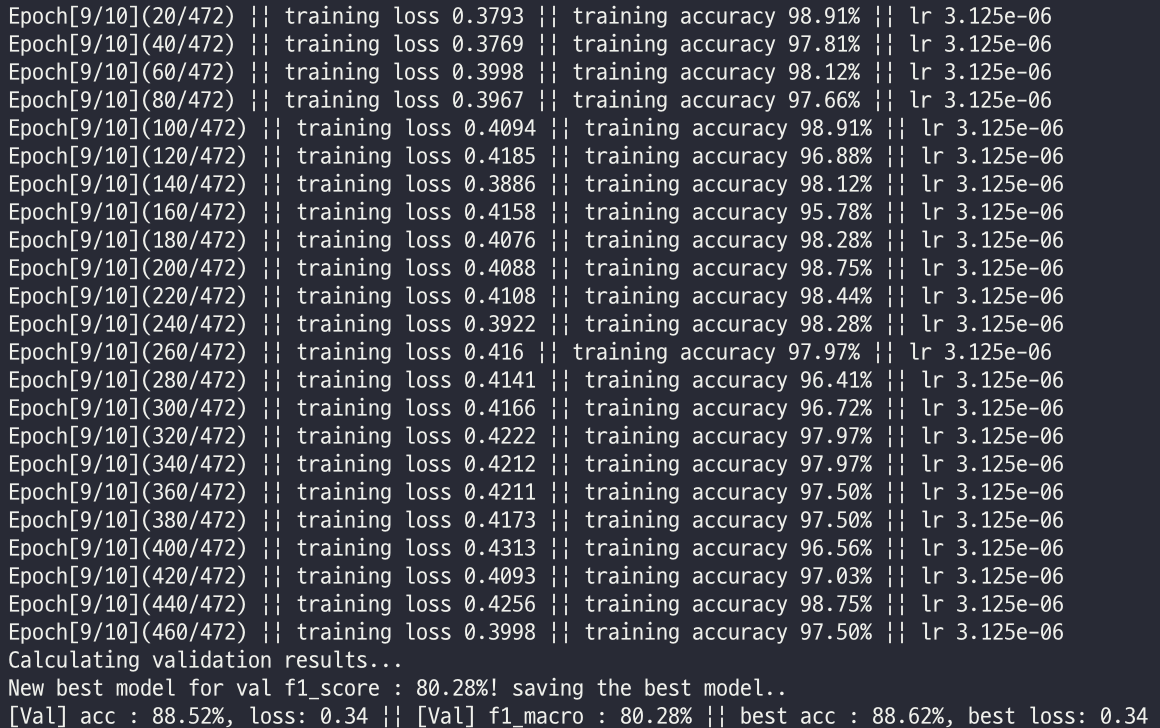
(valid set에 대해 0.8 정도의 f1 score를 가졌고 제출했을 때 리더보드에 0.7 정도가 기록되었다.)
ResNet을 사용한 팀원분들도 0.7 정도의 f1 score를 얻었기 때문에 최종적으로 EfficientNet과 ResNet을 사용하기로 결정했다. 나는 앞서 말한 이미지 전처리 과정 등을 적용하여 최종적으로 0.73의 f1 score를 얻었다.
결과는 팀원이 각각 제출한 결과 중 가장 좋은 결과 2개를 선택했는데 우리 팀은 최종적으로 private set에 대해 0.75, public set에 대해 0.736의 f1 score를 얻었다. ResNet을 기반으로 한 모델이었다.
이외에도 CoAtNet, Swin 등의 모델도 구현은 해놓았는데 사용하지는 않았다. Swin의 경우 꽤 좋은 성능을 냈었는데 최종 모델로 선택하지 않은 점은 아쉬움으로 남았다. 상위권 팀의 발표를 보니 해당 팀은 Swin, ResNet 등을 사용해 앙상블을 했기 때문이다.
프로젝트를 마치며
프로젝트의 의의 그대로 전체적인 ai 개발 과정을 경험해볼 수 있었다. 대회 형식으로 진행되어 지루하지 않게 배워나갈 수 있었다. 프로젝트에 임하며 스스로 했던 다짐이 있었는데 '어려워보인다고 지레 겁먹지 말고 일단 시도해보자'였다. 처음엔 베이스라인 코드를 파악하기도 어려웠는데 1주 정도가 지나자 베이스라인 코드를 개선해 미리 짜놓은 스케쥴대로 실험을 순차진행할 수 있는 코드 등도 만들 수 있었다. '일단 해보는' 것들이 하나하나 쌓이면서 짧은 시간 안에 꽤 성장할 수 있었다고 생각한다. 더불어 에러를 마주하거나 궁금한 점이 생기면 끝까지 물고 늘어져 어떻게든 해결하는 경험을 하며 더욱 성장했다고 생각한다.
아쉬운 점도 많았다. 우선 처음에는 굵직한 부분을 바꿔가며 실험을 해봤어야 했는데 모델을 너무 빠르게 선정하고 hyper parameter 등의 세세한 부분으로 넘어갔다. 기본적인 이미지 전처리만 설정하고 다양한 모델을 실험해보며 성능 변화를 기록했으면 보다 좋은 모델을 선택할 수 있었다고 생각한다.
비슷한 맥락에서 train/val set의 분류를 베이스라인 코드대로 따라간 점도 아쉽다. 상위권 팀의 리뷰를 보니 train/val 비율을 바꿔보거나 다른 방식을 도입하는 등 다양한 실험을 했는데 나는 그러지 못했다. 앞에서 언급했듯 데이터의 불균등 분포가 심했는데 이를 해결하기 위한 방법을 좀 더 고민했어야 했다. 대회가 끝나고 나니 불균등 분포를 고려해 train/val set을 분류할 방법이 떠올라 더 아쉬웠다.
베이스라인 코드를 더 분석해서 다음에는 내가 스스로 코드의 A-Z를 짤 수 있도록 해야겠다.
2주의 대회를 마지막으로 7주간의 lv1 과정이 마무리되었다. 육체적, 정신적으로 힘들기도 했지만 값진 시간이었다고 생각한다. 이번 주말은 잘 쉬고 lv2 과정을 시작하기로 했다. 잘했던 점은 유지하고 아쉬운 점은 유지하며 더 성장해보려 한다.
