
해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
1. 모집단과 표본
- 모집단 : 관측치의 전체 집합
- 표본 : 모집단을 추정하기 위해 일부를 추출한 집합

표본추출(Sampling)
-
모집단으로 부터 표본을 추출하는 것
-
추출 방법
-
복원추출
- 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣고 추출하는 방법, 중복가능
-
비복원추출
- 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣지 않는 방법, 중복불가능
-
랜덤샘플링
- 각 개체를 모두 동일한 확률로 추출하는 방법(주의. 비편향되어야 함)
-
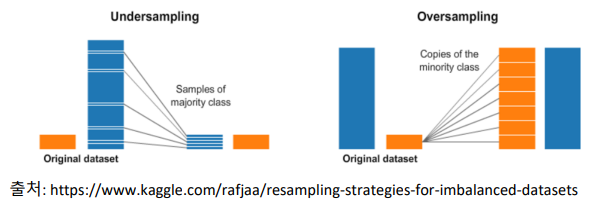
샘플링 기법
- Over Sampling
- 타겟 데이터가 적은 경우 많은 class의 비율만큼 증가시킴(일정 비율로 복원추출)
- 과적합 발생가능
- Under Sampling
- 타겟 데이터가 많은 경우 적은 class의 비율만큼 감소시킴
- 편향가능, 모형의 성능 감소가능
2. 표본분포
- 통계량
- 표본에 기초하여 계산되는 수치 함수
- 표본분포
- 통계량들이 이루는 분포
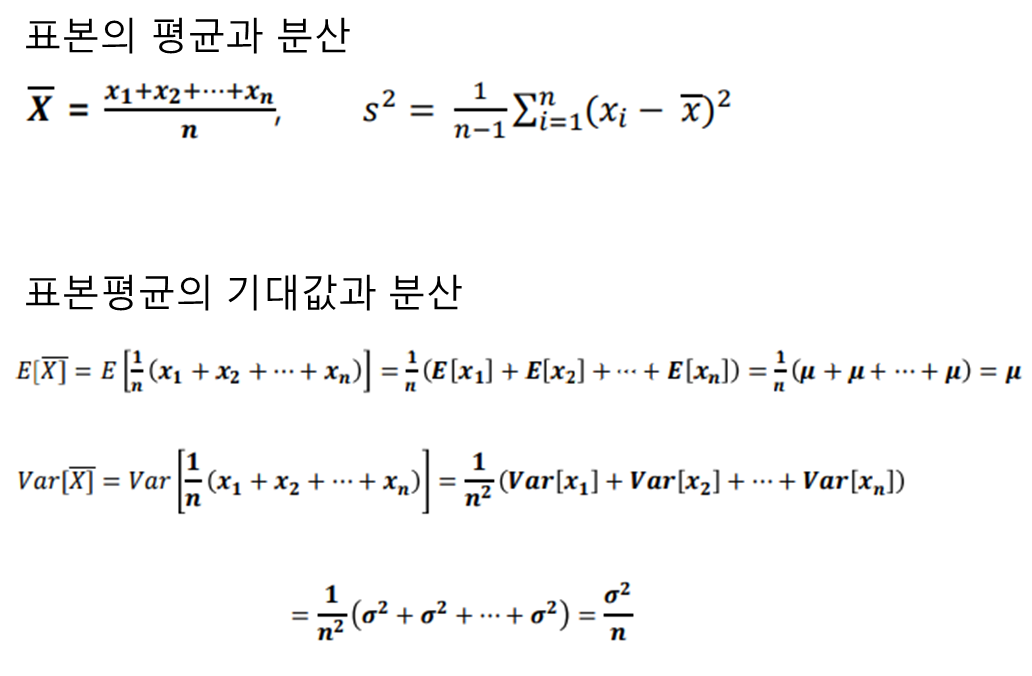
중심극한 정리
- 평균이 이고 인 임의의 모집단에서 랜덤 표본 n개를 추출했을 때, n>=30이면 표본평균은 근사적으로 정규분포 을 따른다.

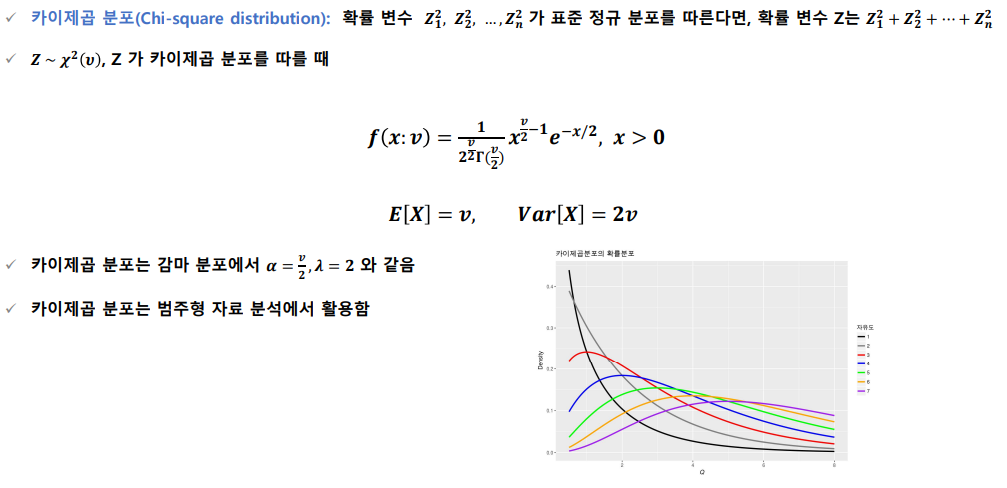
카이제곱분포
자유도
-
표본수-제약조건의 수 또는 표본수-추정해야 하는 모수의 수를 의미하며 일반적으로 n-1을 사용함
-
ex. 표본의 크기가 5이고, 표본 평균이 3로 정해졌다면, 숫자 4개는 자유롭게 정할 수 있으나 마지막 하나의 숫자는 나머지 네 개의 숫자에 의해 결정. 1, 2, 3, 4를 골랐다면 마지막 숫자는 자동으로 5가 되야 평균이 5로 정해져 있음
-
카이제곱 분포는 자유도가 커지면서 표준정규 분포에 근사하며, n ≥ 30이면, 확률을 근사적으로 정규분포로 구할 수 있음
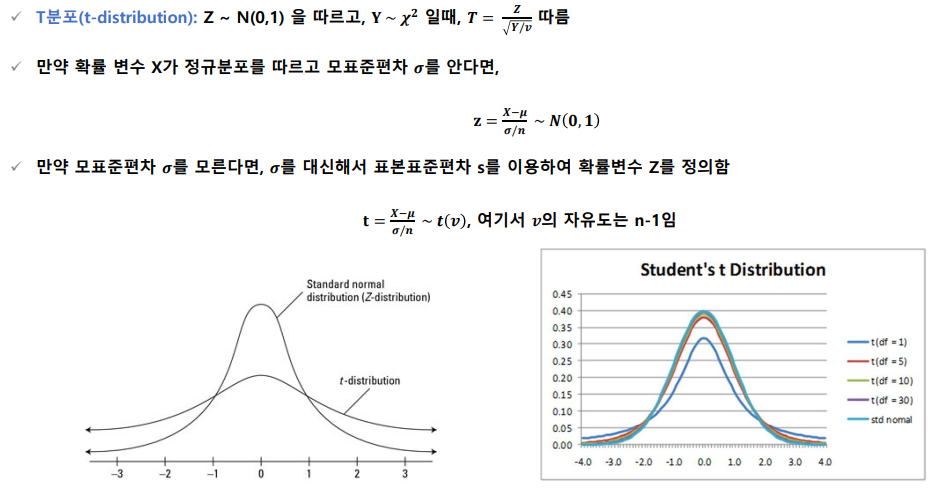
t분포

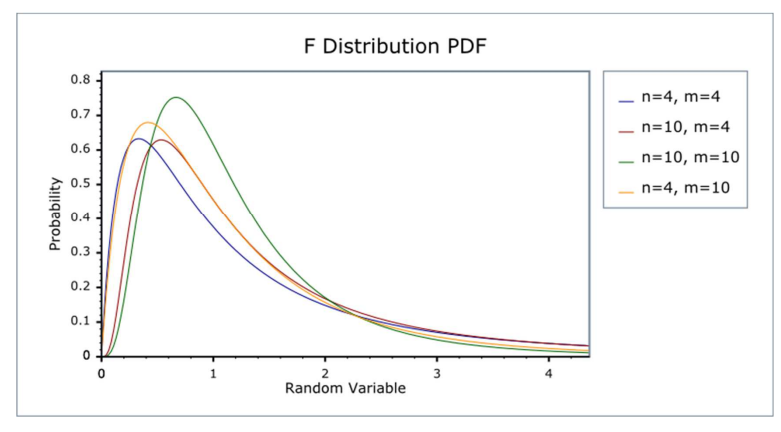
F분포

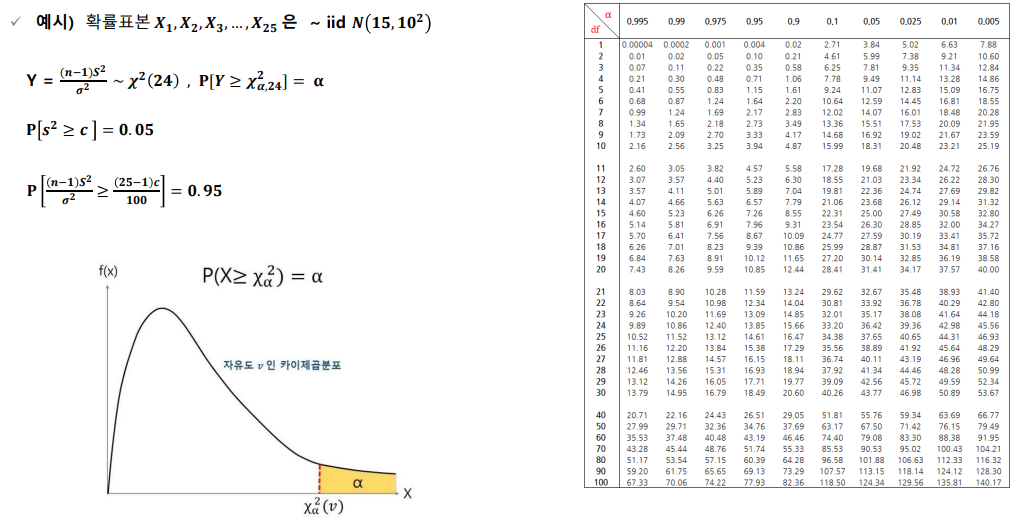
문제)
모집단 ~ , ~ , 각각의 모집단으로부터 표본을 추출했을 때 이라고 하자.
에서 C를 구하시오
풀이)
~
= = 0.05
3. 추정
3-1. 추정
-
추정(estimation)
- 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것
-
추정량(estimator)
- 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량 이라고 함
모수 추정방법
-
점추정(point estimation) : 모수를 하나의 특정값으로 추정하는 방법
-
일치성 : 표본의 크기가 모집단의 크기에 근접해야 함
-
불편성 : 추정량이 모수와 같아야 함
-
유효성 : 추정량의 분산이 최소값이어야 함
-
평균오차 제곱 : 평균오차제곱이 최소값이어야 함
-
-
구간 추정(interval estimation)
- 모수가 포함될 수 있는 구간을 추정하는 방법
-
신뢰구간
- 추정값이 존재하는 구간에 모수가 포함될 확률
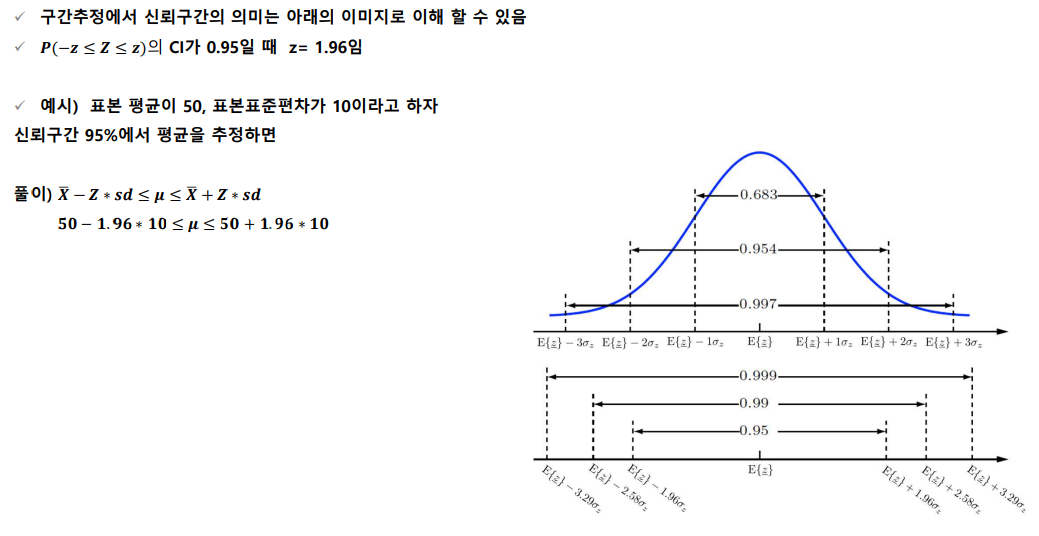
모집단의 분산을 아는 경우

모집단의 분산을 모르는 경우

표본의 크기 결정

3-2. 모비율 추정
모비율의 점추정

모비율의 구간추정


모평균 차이의 추정


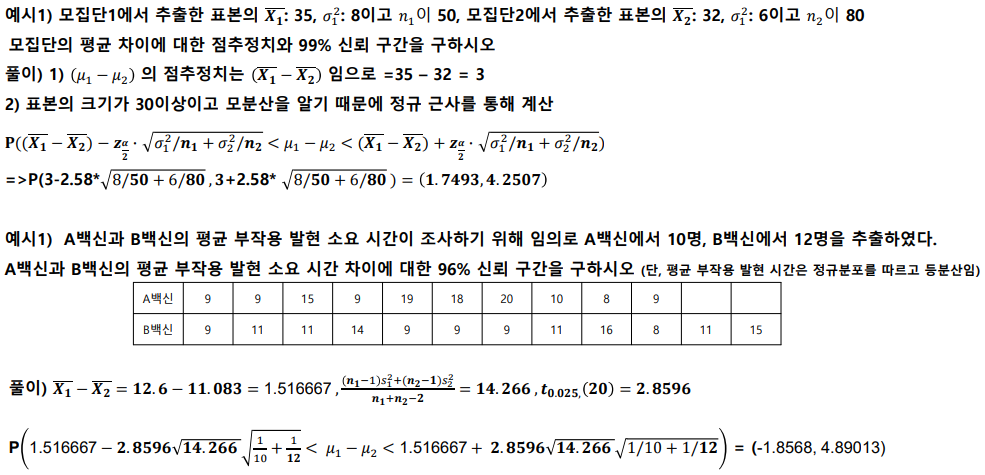
모비율의 추정


4. 가설검정
4-1. 가설검정과 유의수준 정의
- 가설 검정 = 가설(Hypothesis) + 검정(Testing)
가설
-
주어진 사실 또는 조사하려고 하는 사실에 대한 주장 또는 추측
-
통계학에서는 모수를 추정할 때 모수가 어떠하다고 증명하고 싶은 추측이나 주장을 의미함
-
귀무 가설(Null hypothesis:
- 기존의 사실(아무것도 없다, 의미가 없다)
- 대립가설과 반대되는 가설로 연구하고자 하는 가설의 반대이며, 연구목적이 아님
- ex) : 코로나 백신이 효과가 없다,
-
대립 가설(Alternative hypothesis:
- 데이터를 기반으로 주장하고 싶은 가설 또는 연구 목적인 가설, 귀무가설의 반대
- ex) : 코로나 백신이 효과가 있다, or
오류
- 제1종 오류
- 귀무가설이 참이지만, 귀무가설을 기각하는 오류
- 제2종 오류
- 귀무가설을 기각해야 하지만, 귀무가설을 채택하는 오류
검정통계량, P-value, 기각역
-
검정통계량
-
귀무가설이 참이라는 가정하에 얻은 통계량
-
검정결과 대립가설을 선택하게 되면 귀무가설을 기각(reject)함
-
검정결과 귀무가설을 선택하게 되면 귀무가설을 기각하지 못한다고 표현함
-
-
P-value: 귀무가설이 참일 확률
-
0~1사이의 표준화된 지표(확률값)
-
귀무가설이 참이라는 가정하에 통계량이 귀무가설을 얼마나 지지 하는지를 나타내는 확률
-
대게 0.05 or 0.1의 유의수준(\alpha)보다 낮으면 귀무가설을 기각한다
-
-
기각역(reject region)
- 귀무가설을 기각시키는 검정통계량의 관측값의 영역
가설검정의 절차
- 가설수립: : 코로나 백신이 효과가 없다, : 코로나 백신이 효과가 있다
- 유의 수준 결정: 유의수준 정의
- 기각역 설정
- 검정통계량 계산
- 의사 결정
양측검정과 단측검정
- 양측검정
- 대립가설의 내용이 같지 않다 또는 차이가 있다 등의 양쪽 방향의 주장
- ex) A직무와 B직무의 평균 연봉은 차이가 있다
- 단측검정
- 한쪽만 검증하는 방식으로 대립가설의 내용이 크다 또는 작다 처럼 한쪽 방향의 부장
- ex) A직무가 B직무보다 평균 연봉이 크다
4-2. 단일 표본에 대한 가설검정
모평균 가설검정 – 모분산을 아는 경우
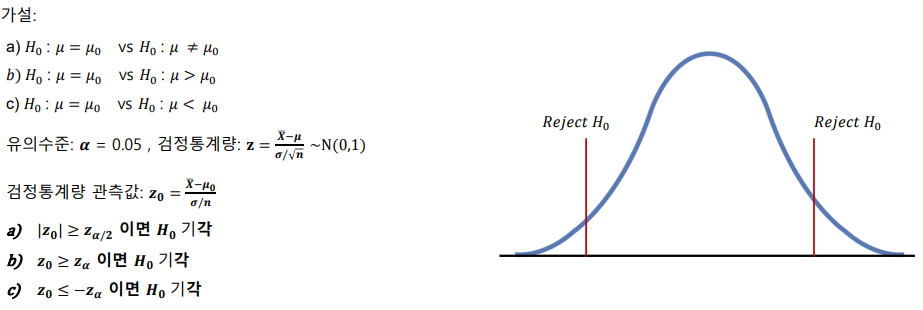

모평균 가설검정 – 모분산을 모르는 경우(소표본)
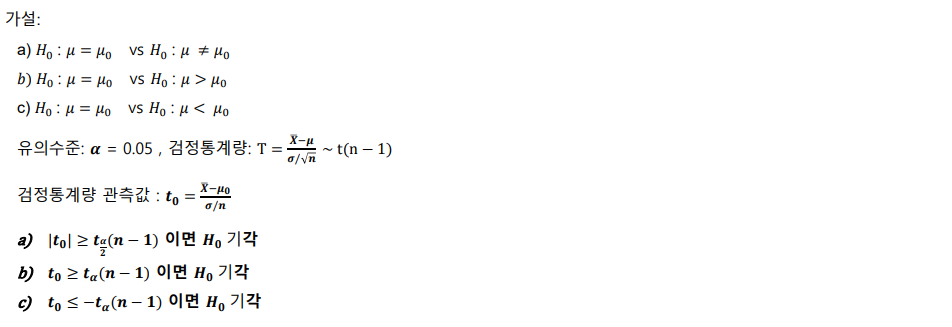
모비율 가설검정

대표본과 소표본
- 대표본 : ~
- 소표본 : ~ 을 알면, 모르면
4-3. 두 개의 표본에 대한 가설 검정
대표본 – 모분산을 아는 경우


소표본 – 모분산을 모르는 경우


대응 비교

