[데이터베이스] 2014년 이화여대 용환승 교수님
1.[데이터베이스] 2014년 이화여대 용환승 교수님 - 4. 데이터베이스 설계와 ER 모델

약한 엔티티 타입은 강한 엔티티 타입에 따라 다니는 엔티티다. 예를 들어 은행 시슽메에서 상환 엔티티는 대출 엔티티가 없으면 의미가 없다.애트리뷰트는 독립적인 의미를 가지지 않는다.주소라는 애트리뷰트는 여러개의 애트리뷰트로 이루어져 있다. 대부분의 애티리뷰트이다.엑셀에
2.[데이터베이스] 2014년 이화여대 용환승 교수님 - 5. 데이터베이스 설계와 ER 모델

단순히 엔티티를 만들면 된다.약한 엔티티는 키가 없으므로, 강한 엔티티의 기본키를 외래키로 포함한다. 관계는 릴레이션으로 안만들고 하나의 기본키를 다른 엔티티의 외래키로 포함하는 것이다.아래에는 일대일 관계를 만드는 4가지 방법이 나온다. 이렇게 표현하면 문제는 이 외
3.[데이터베이스] 2014년 이화여대 용환승 교수님 - 6. 물리적 데이터베이스 설계
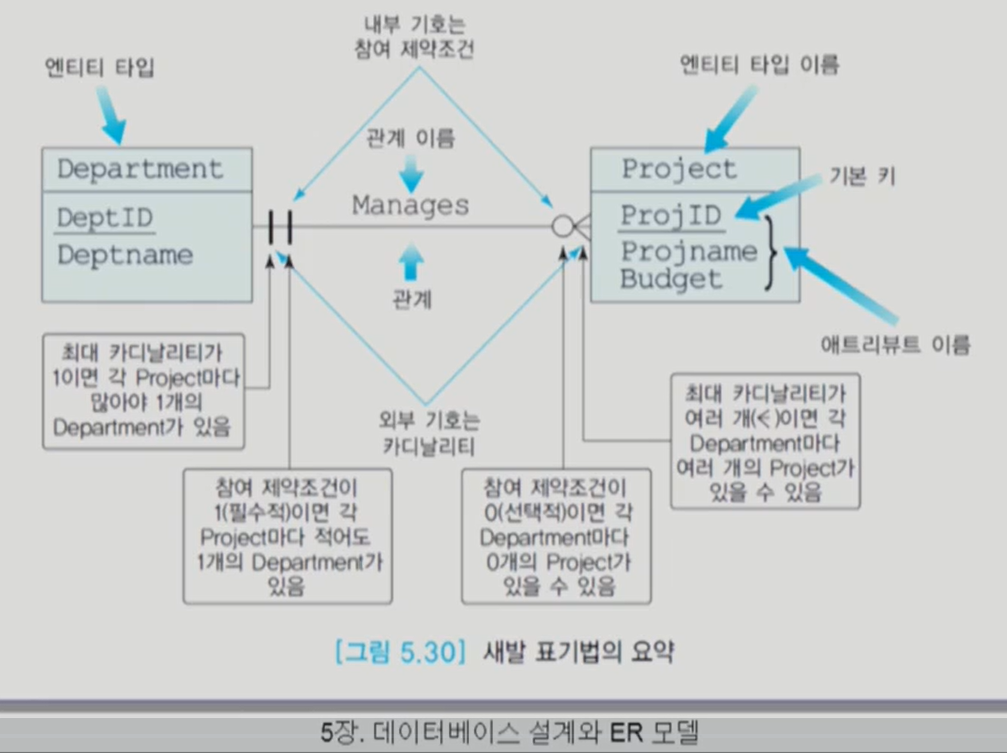
department가 프로젝트를 최소 0개를 가질 수 있고project는 departmnet를 최소 1에서 최대 2까지 가질 수 있다. 즉 반드시 관계를 가져야 한다. 결국에는 보조기억장치에 데이터를 어떻게 저장할 것인가의 문제다.seek time을 줄이는 것이 핵심이
4.[데이터베이스] 2014년 이화여대 용환승 교수님 - 7-1. 물리적 데이터베이스 설계

위의 방법 같은 경우에는 중간에 삭제가 되면 다시 shift를 시켜야하는 단점이 있다. 밑에는 맨 뒤에 것으로 빈공간을 채우는 방법이다.한 파일이 여러개의 블록에 걸쳐서 있는데, 디스크에서 블록단위로 가져온다.그냥 들어온 순서대로 저장한 것이다. 원하는 레코드를 찾기
5.[데이터베이스] 2014년 이화여대 용환승 교수님 - 7-2. 물리적 데이터베이스 설계

주로 마스터 인덱스는 메모리에 상주시킨다.B+트리에서 B는 balanced를 뜻한다.primary key또는 unique한 애트리뷰트에 대해 자동으로 인덱스를 생성한다.데이터베이스에서 중복을 최대한 없애야 한다. 완전히 없앨 수는 없다. FK만해도 중복이다.
6.[데이터베이스] 2014년 이화여대 용환승 교수님 - 8. 릴레이션 정규화

정규화 개요 > 부서정보와 사원정보가 다 섞여있다. > 김창섭의 정보가 중복되어 있다. > 저장공간이 낭비되는 것도 문제지만, 데이터베이스 불일치 상태가 더 크다.
7.[데이터베이스] 2014년 이화여대 용환승 교수님 - 9. 릴레이션 정규화 뷰와 시스템 카탈로그
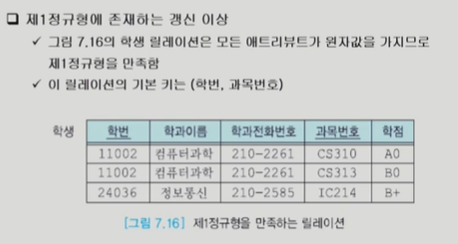
부분 함수 종속을 없애야 한다.이행적 종속성을 없애야 한다.학번과 과목이 강사를 결정하는데 강사가 과목을 결정한다.테이블이 너무 많아지면 join 연산의 비용이 커진다.검색 질의의 비율이 훨씬 높으면 join을 줄이는 것이 더 좋을 수도 있다.derived relati
8.[데이터베이스] 2014년 이화여대 용환승 교수님 - 10. 뷰와 시스템 카탈로그

이 경우 어느쪽 릴레이션을 봐도 기본키가 없기 때문에 안된다.현재 허용하지 않고 있다.사용자가 해당 질의에 대한 권한이 있는지도 확인한다. 또한 더 나은 인덱스 선택에도 정보를 제공한다. 메타 데이터 역시 릴레이션으로 정의되어 있다. 메타 데이터에 대한 정보는 시스템
9.[데이터베이스] 2014년 이화여대 용환승 교수님 - 11. 트랜잭션

전체가 성공하거나 전체가 성공안하든가 해야 한다.기본적으로 각각의 SQL문이 하나의 트랜잭션으로 취급되고, 이 뜻은 원자성을 지켜야한다는 것이다. 데이터를 공유하기 때문에 어렵다.완료되지 않은 트랜잭션이 갱신한 데이터가 dirty data다. dirty 데이터
10.[데이터베이스] 2014년 이화여대 용환승 교수님 - 12. 트랜잭션

커밋하지 않은 데이터가 update한 것을 dirty라고 한다. 일반적으로는 commit을 하고 unlock을 많이 한다.이건 2-phase locking이 아니다. 한꺼번에 해제하는 방식을 일반적으로 많이 쓴다.데드락을 해결하는 방법?1\. 장유유서2\. 리소스를 많