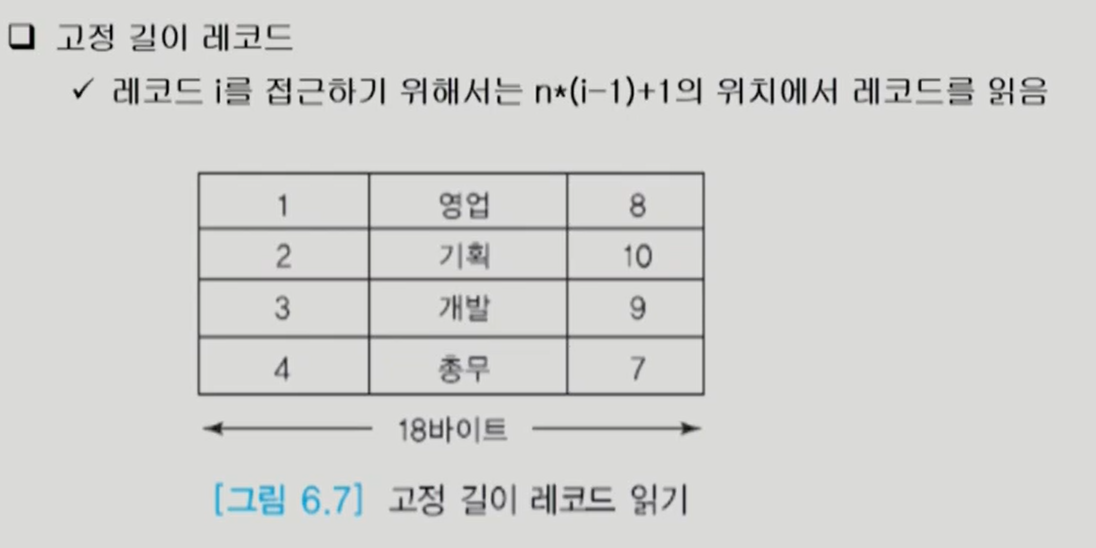
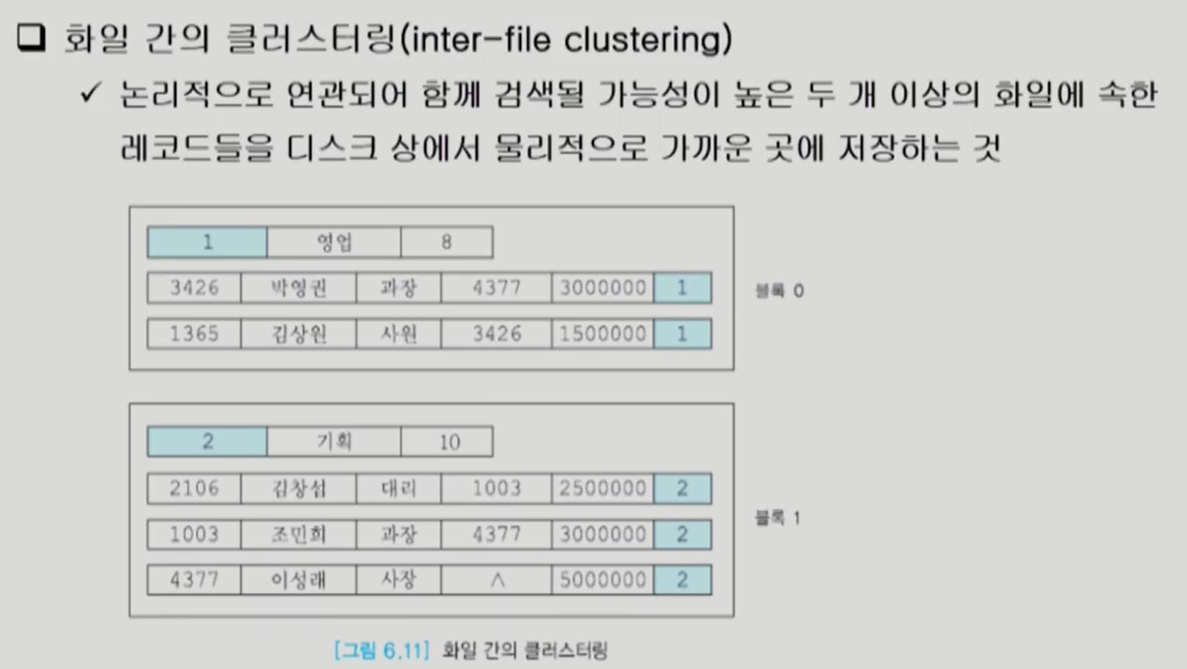
디스크 상에서 파일의 레코드 배치

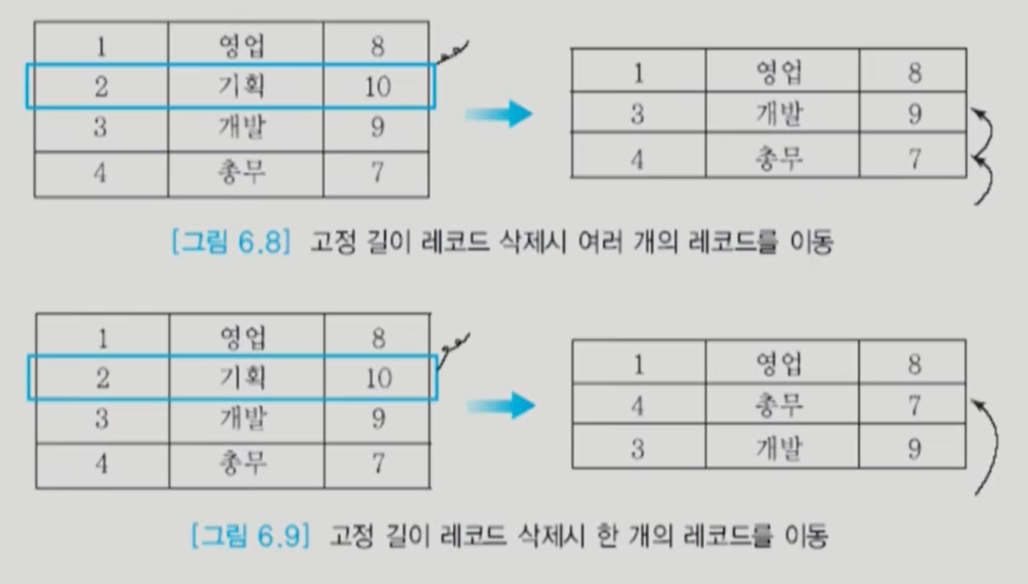
위의 방법 같은 경우에는 중간에 삭제가 되면 다시 shift를 시켜야하는 단점이 있다.
밑에는 맨 뒤에 것으로 빈공간을 채우는 방법이다.

한 파일이 여러개의 블록에 걸쳐서 있는데, 디스크에서 블록단위로 가져온다.
파일 조직

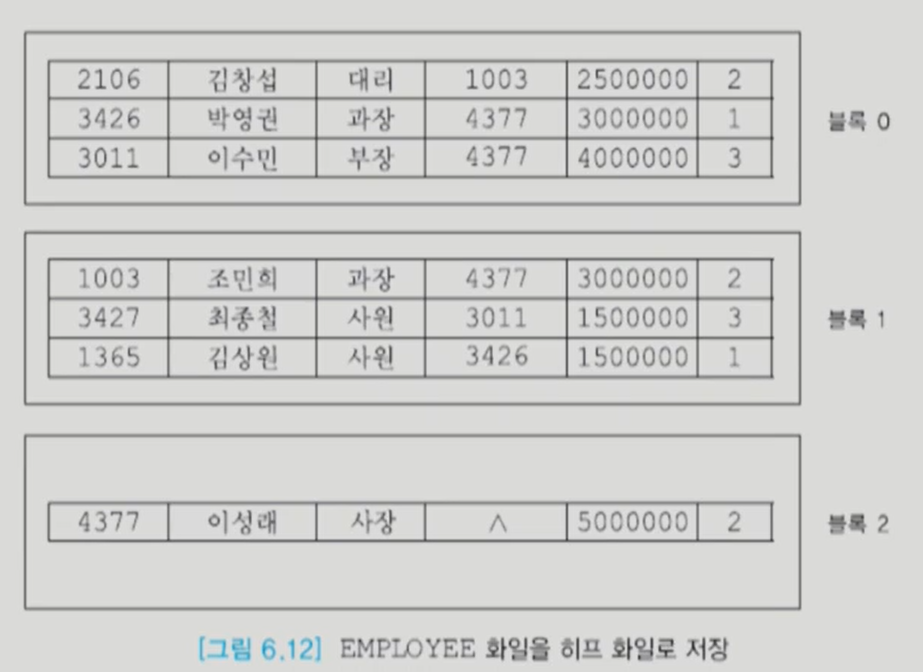
힙 파일

그냥 들어온 순서대로 저장한 것이다. 원하는 레코드를 찾기 위해 모든 레코드들을 순차적으로 스캔해야 한다. 삭제한 공간을 재사용하지 않기 때문에 주기적으로 전체 레코드를 재구쉉해야 한다.



순차 파일 (Sequential File)

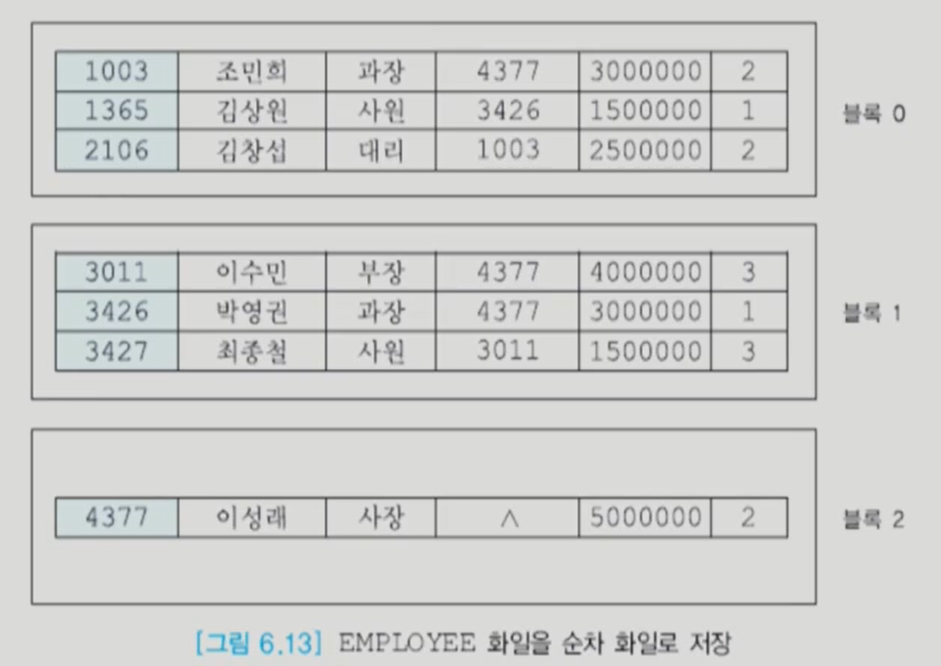

만약 pk를 기준으로 탐색한다면 logN의 성능을 보이고 이외의 경우에는 N이다.
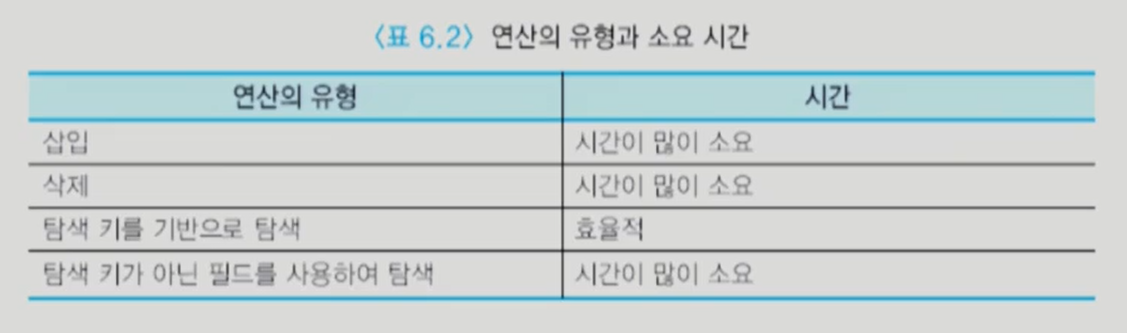

단일 단계 인덱스
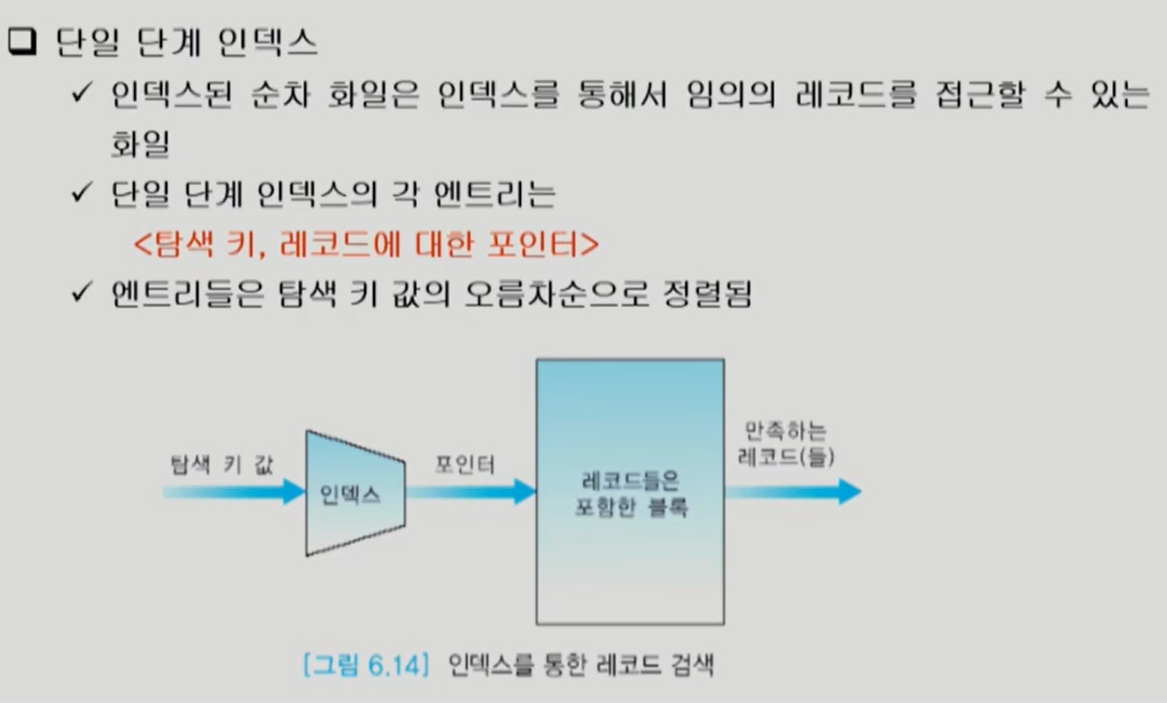

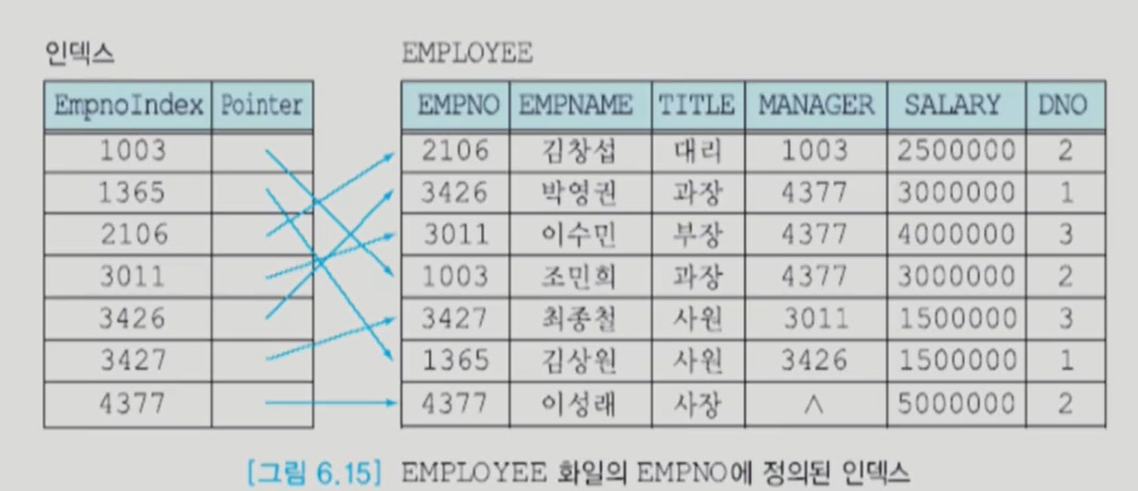

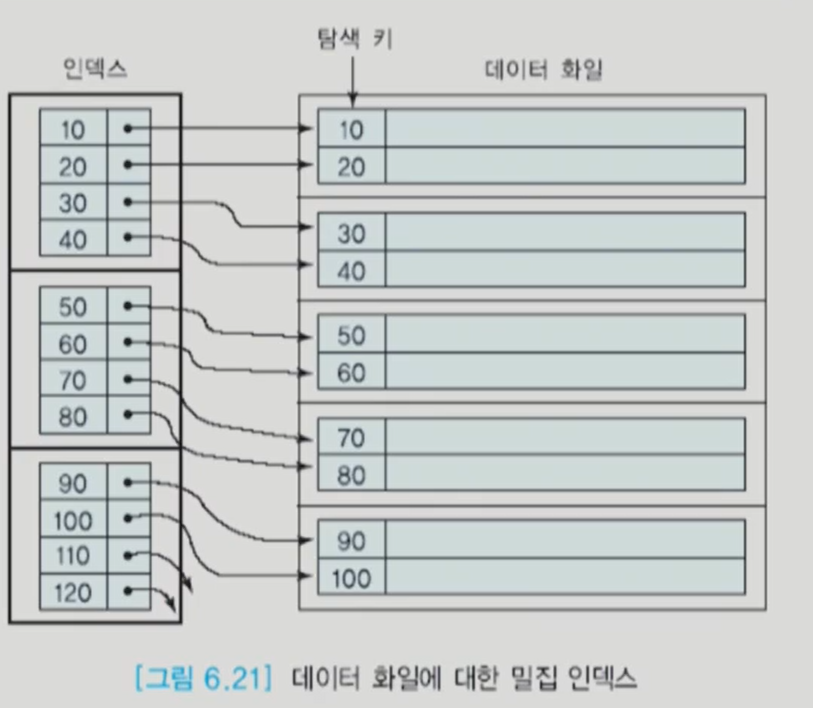
기본 인덱스 (primary index)

여기서 희소는 sparse를 번역한 것이다. sparse index <-> dense index
sparse index는 데이터 파일 자체가 정렬되어있다.
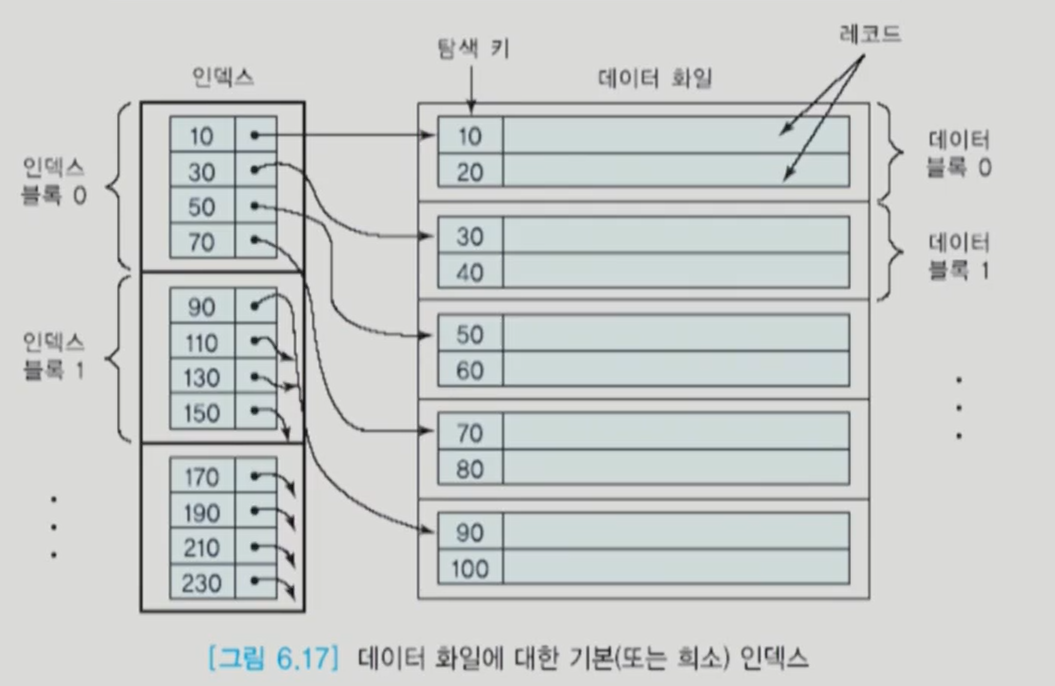

클러스터링 인덱스

키는 물론이고 데이터 파일도 정렬된 경우이다.
range query를 처리하는데 좋다.
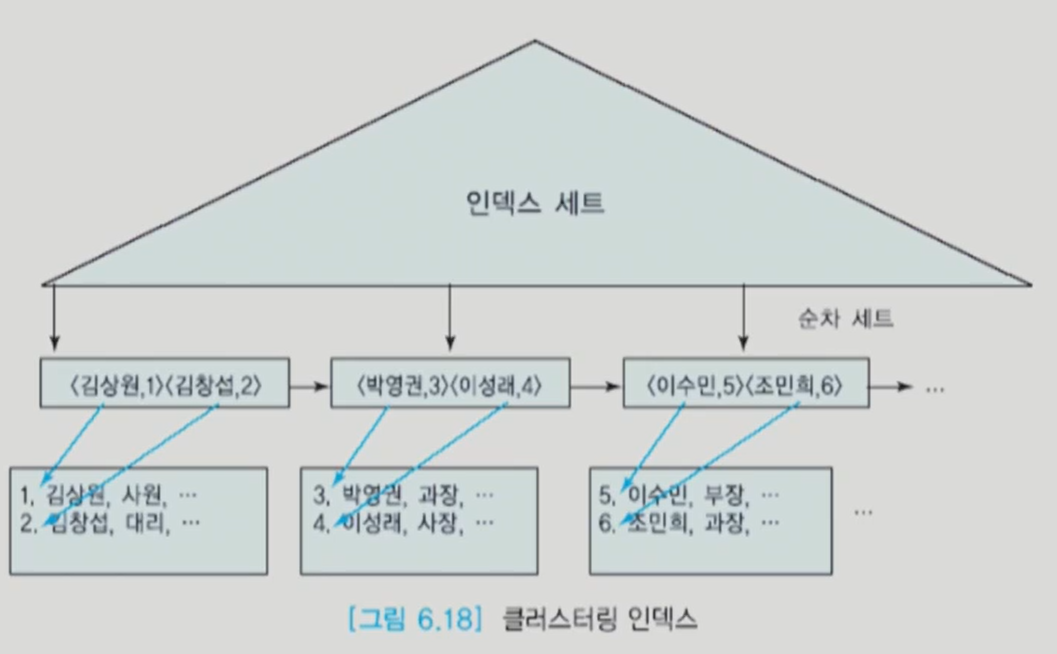
이름이 키 일때, 이름과 데이터 모두 정렬되어 있다.
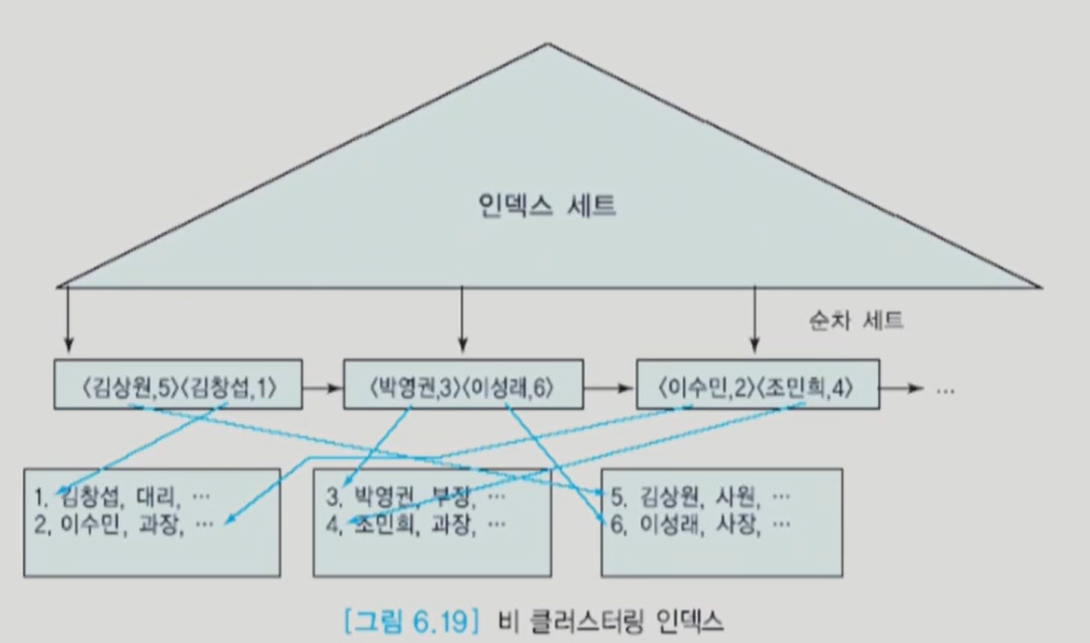
이런 경우 range query에서 불리하다 하나하나 찾아봐야하기 때문이다.

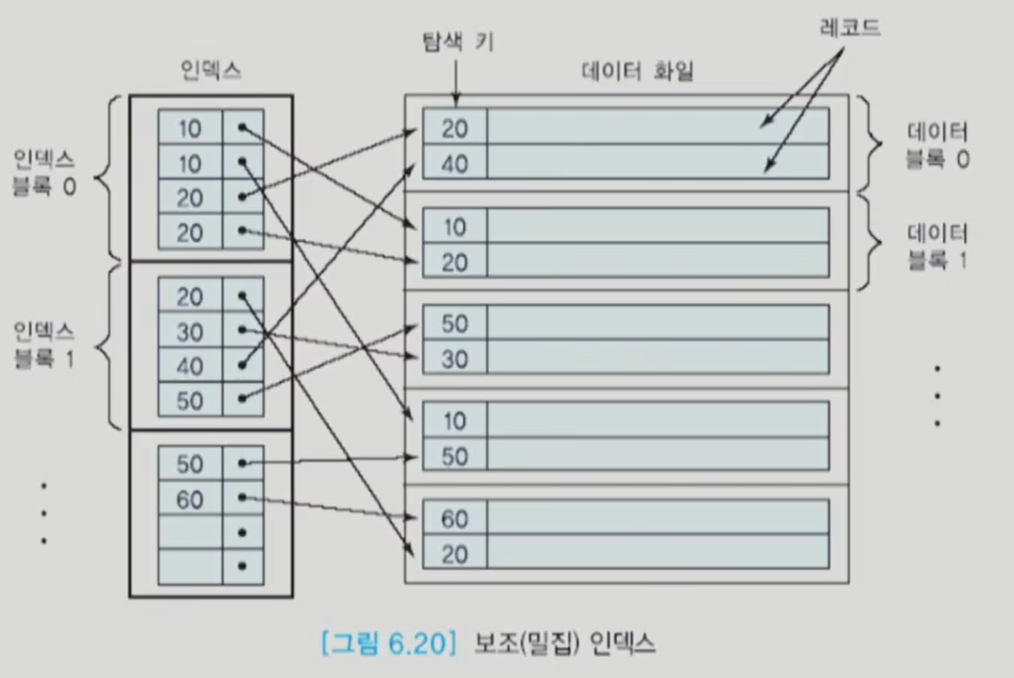
보조 인덱스 (seconday index)

여기에는 탐색키 값에 따라 만들어진 것이 아닐 수 있기 때문에, 반드시 dense index여야 한다.