대규모 서비스를 지탱하는 기술
1.[대규모 서비스를 지탱하는 기술] 1장. 대규모 서비스와 소규모 서비스

최근 트렌드는 스케일아웃이다. 스케일아웃은 서버를 횡으로 전개, 즉 서버의 역할을 분담하거나 대수를 늘림으로써 시스템의 전체적인 처리능력을 높여서 부하를 분산하는 방법이다. 반면 스케일업은 하드웨어 성능을 높여 처리능력을 끌어올리는 방법이다.저가의 하드웨어를 횡으로 나
2.[대규모 서비스를 지탱하는 기술] 2장. 계속 성장하는 서비스와 대규모화의 벽
서비스가 아직 소규모인 단계에서는 심플한 방법이 더 나은 경우가 많으므로 너무 이른 최적화가 좋은 방침이라고는 할 수 없다. 어느정도의 수용능력 관리나 서비스 설계시에 필요 이상으로 데이터를 증가시키지 않도록 하는 설계를 포함시키는게 좋을 것이다.
3.[대규모 서비스를 지탱하는 기술] 4장. 하테나 북마크의 데이터 규모
하테나는 테이블 하나의 크기가 기가바이트가 나오고있다. row 수로 따지자면 천만 단위이다.
4.[대규모 서비스를 지탱하는 기술] 5장. 대규모 데이터 처리의 어려운 점
대규모 데이터를 다룰 때 어려운 점은 '메모리 내에서 계산할 수 없다'는 점이다.메모리 내에서 계산할 수 없게 되면 디스크에서 데이터 검색을 해야한다.하지만 디스크는 느리므로 시간이 훨씬 더 걸린다.디스크는 메모리보다 10^5 ~ 10^6배 느리다. 10만배~100만배
5.[대규모 서비스를 지탱하는 기술] 6장.규모조정의 요소
웹 서비스에서는 스케일업 전략보다는 스케일아웃 전략이 주류이다. 이유는 다양하지만, 비용이 저렴하다는 점과 시스템 구성에 유연성이 있다는 점이 포인트다.CPU 부하는 확장성을 확보하기는 쉽다. 하지만 I/O부하는 확장하기 어렵다.CPU 부하는 분산이 쉬운 이유는 데이터
6.[대규모 서비스를 지탱하는 기술] 7장.대규모 데이터를 다루기 위한 기초지식
어떻게 하면 메모리에서 처리를 마칠 수 있을까?데이터량 증가에 강한 알고리즘, 데이터 구조데이터압축, 정보 검색 기술
7.[대규모 서비스를 지탱하는 기술] 8장. OS의 캐시 구조
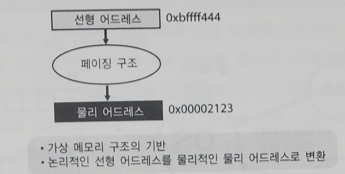
디스크와 메모리의 속도차가 10^5~10^6배가 나는데, OS에는 디스크 내의 데이터에 빠르게 접근할 수 있는 구조가 갖춰져 있다. 그 원리가 바로 캐시다.Linux의 경우에는 페이지 캐시(page cache)나 파일 캐시(file cache), 버퍼 캐시(buffer
8.[대규모 서비스를 지탱하는 기술] 9장. I/O 부하를 줄이는 방법
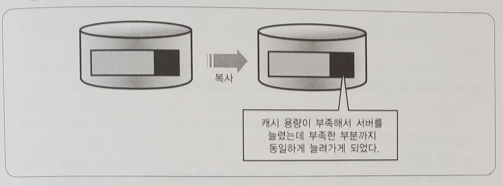
메모리를 늘려서 전부 캐싱할 수 있다면 좋겠지만, 당연히 데이터를 전부 캐싱할 수 없는 규모가 될 수 있다. 이때 복수 서버로 확장시키는 방안을 생각해볼 필요가 있다.단순히 데이터를 복사해서 대수를 늘리게되면 애초에 캐시 용량이 부족해서 늘렸는데 그 부족한 부분도 그대
9.[대규모 서비스를 지탱하는 기술] 10장. 국소성을 살리는 분산
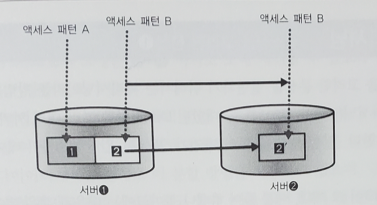
캐시 용량을 늘리기 위해 어떻게 하면 여러 대의 서버로 확장시킬 수 있는지에 대해 알아보자. 국소성은 locality라고도 한다.서버1과 2 양측에 별다른 액세스 패턴을 고려하지 않고 분배한 경우, 데이터 영역 2로의 엑세스는 계속되므로 서버1이 데이터 영역2도 캐싱해
10.[대규모 서비스를 지탱하는 기술] 11장. 인덱스를 올바르게 운용하기
ㄴ
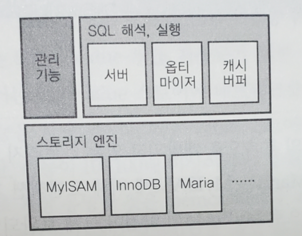
11.[대규모 서비스를 지탱하는 기술] 12장. MySQL의 분산
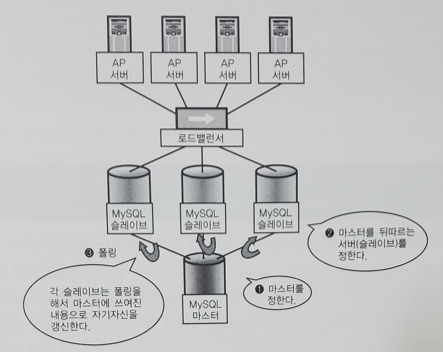
MySQL에는 기본 기능으로 레플리케이션 기능이 있다. 레플리케이션이란 마스터(master)를 정하고 마스터를 뒤따르는 서버(슬레이브)를 정해두면, 마스터에 쓴 내용을 슬레이브가 폴링(Polling)해서 동일한 내용으로 자신을 갱신하는 기능이다. 슬레이브는 마스터의 레
12.[대규모 서비스를 지탱하는 기술] 13장. MySQL의 스케일아웃과 파티셔닝
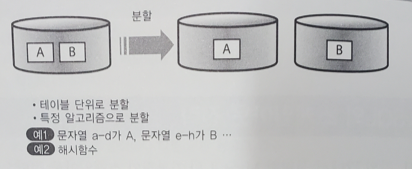
ㄴ
13.[대규모 서비스를 지탱하는 기술] 14장. 용도특화형 인덱싱
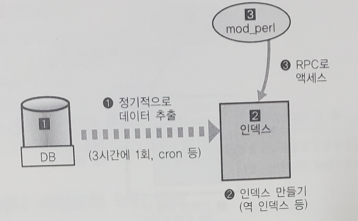
배치 처리로 RDBMS에서 데이터를 추출해서 별도의 인덱스 서버와 같은 것을 만들고, 이 인덱스 서버에 웹 애플리케이션에서 RPC(Remote Prodecude Call) 등으로 액세스하는 방법을 사용한다. 위 그림을 보자. DB(1)에서 정기적으로 3시간에 1번처럼
14.[대규모 서비스를 지탱하는 기술] 16장. 정수 데이터를 컴팩트하게 가져가기
과제: 정수열이 기록된 CSV를 바이너리로 해서 컴팩트하게 가져가기출제 의도큰 정수열을 컴팩트하게 만드는 방법을 안다.컴팩트하게 만들면..디스크 IO를 줄일 수 있다.데이터 공간 효율적으로 사용데이터형의 크기 등에 의식을 갖는다. VB Code의 속도감을 파악한다.
15.[대규모 서비스를 지탱하는 기술] 17장. VB Code와 속도 감각

VB Code(Variable Byte Code)가 사용된다.VB Code는 구현 면에서는 간단하고속도가 빨라 손 쉽게 사용할 수 있다. VB Code는 압축 알고리즘이라기 보다는 정수의 부호화 방법중 하나이다
16.[대규모 서비스를 지탱하는 기술] 24장. 전문 검색기술의 응용범위
하테나 다이어리를 대상으로 한 검색엔진이란, 하테나 다이어리의 전문을 검색 대상으로 해서 하테나 키워드로 이를 검색 가능하게 하는 시스템이다. 누군가 블로그에 새로운 글을 작성했을 때 해당 글에 포함되어 있는 키워드를 전부 추출한다. 그러면 '이 블로그는 OO와 xx라
17.[대규모 서비스를 지탱하는 기술] 24장. 검색 시스템의 아키텍처
크롤링저장인덱싱검색스코어링결과표시검색 대상 문서를 처음부터 전부 읽어가는 가장 단순한 아키텍처다. 검색 대상인 텍스트의 길이를 m, 검색하려는 검색어의 길이를 n이라고 했을 때 O(mn)만큼 걸린다. 이는 검색 처리로서 상당히 느리다. KMP(Knuth-Morris-P
18.[대규모 서비스를 지탱하는 기술] 26장. 검색엔진의 내부구조
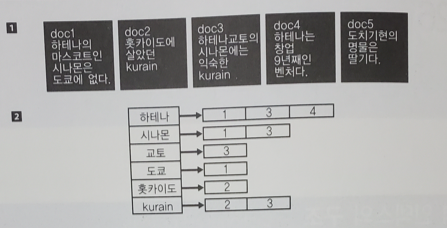
역 인덱스의 내부구조는 크게 Dictionary와 Postings라는 두 파트로 나뉜다. 위쪽에 있는 1이 검색하고자하는 대상 문서라고 하자. 각 문서에는 번호가 달려있다. 각각의 문서는 문장을 담고 있다.문서를 인덱스화한 것이 아래쪽에 있는 2다. 인덱스에서 좌측 사
19.[대규모 서비스를 지탱하는 기술] 29장. 엔터프라이즈 vs. 웹 서비스
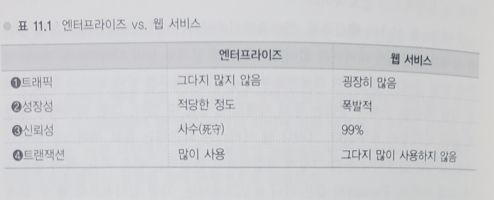
ㅇ
20.[대규모 서비스를 지탱하는 기술] 31장. 계층과 확장성
4 core CPU, 8GB 메모리 정도의 서버를 사용하면 피크 시 성능이 수천 요청/분 정도가 나온다. 이 정도면 월 100만 PV(Page View)를 처리할 수 있다.4 core CPU 2개에 32GB 메모리 서버를 준비할 수 있다면 보다 파워가 늘어나서 수천~1
21.[대규모 서비스를 지탱하는 기술] 32장. 부하 파악, 튜닝
q부하를 볼 때는 먼저 Load Average부터 본다. Linux 커널 내에는 프로세스가 다수 동작하고 있다. Load Average란 이러한 프로세스가 언제든지 동작할 수 있는 상태지만, 아직 실제 CPU가 할당되지 않아서 대기 상태에 있는 프로세스 수의 평균치다.
22.[대규모 서비스를 지탱하는 기술] 33장. 다중성 확보
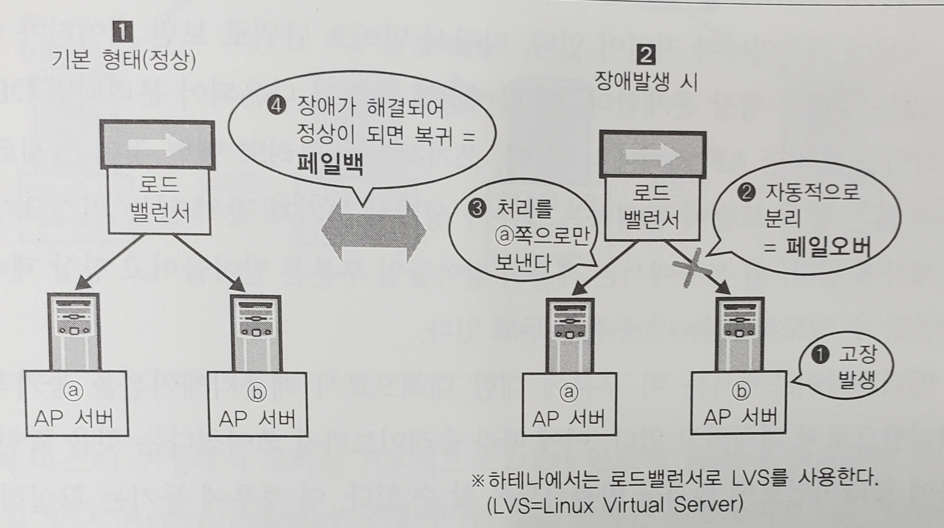
다중화에 대한 실제적인 얘기를 하자면 AP 서버에서는 확장성을 생각하는 방식과 마찬가지로 서버 여러 대를 늘어놓는게 기본이 된다. 서버를 늘어놓을 때 중요한 것은 1대나 2대 정도 정지하더라도 충분히 처리할 수 있도록 처리능력을 확보해두는 것이다.서버는 다양한 요인으로
23.[대규모 서비스를 지탱하는 기술] 34장. 시스템 안정화
시스템 안정화와 상반관계안정성 <-> 자원효율안정성 <-> 속도한계에 이를 때까지 메모리를 튜닝메모리 소비가 늘어난다 -> 성능 저하 -> 장애한계에 이를 때까지 CPU 사용서버 1대가 다운 -> 전체 처리능력 초과 -> 장애기능 추가, 2. 메모리 누수새로
24.[대규모 서비스를 지탱하는 기술] 35장. 시스템 안정화 대책
우선 SQLd 부하에 대해 아랑보자. DB에 이상한 SQL을 날리면 바로 멈추면서 다운되어버린다. 부하가 높아질 듯한 SQL을 발행하지 않도록 하는 것이 시스템을 안정화시키기 위해서 중요하다.부하가 높아질만한 SQL을 발행할 경우에는 격리시킨 DB를 준비해서 거기로 S
25.[대규모 서비스를 지탱하는 기술] 38장. 네트워크 분기점
1Gbps의 한계는 정확히는 30만pps (packet per second) 의 한계다. 이에 대한 대책으로는 PC라우터를 여러 대 병렬화하든가 박스형 라우터, 예를 들면 고가의 Cisco 라우터를 구입하는 방법이 있다.500호스트의 한계는 구체적으로는 스위치의 ARP
26.[대규모 서비스를 지탱하는 기술] Appendix - 작업큐(Job-Queue) 시스템
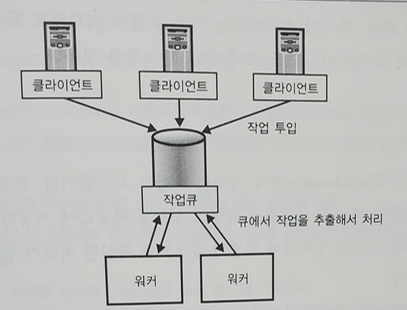
웹 서비스에서는 기본적으로 요청이 동기적으로 실행된다. 즉, 요청에 기인하는 모든 처리가 끝난 다음에 응답이 반환된다. 따라서 계속 성장해가는 웹 서비스에서는 데이터가 서서히 축적되면서 데이터를 추가하고 갱신하는 처리가 점점 무거워진다. 이런 경우에 작업큐 시스템을 사
27.[대규모 서비스를 지탱하는 기술] Appendix - 스토리지 선택
데이터는 업로드된 사진 데이터나 블로그 본문과 같이 본질적으로 없어질 수 없는 원본 데이터부터, 원본 데이터를 가공함으로써 생성된 액세스 랭킹이나 검색용 인덱스 데이터 등 재생성 가능한 가공 데이터, 캐시와 같이 사라져도 성능상의 문제 이외에는 다른 문제가 없는 데이터
28.[대규모 서비스를 지탱하는 기술] Appendix - 캐시 시스템
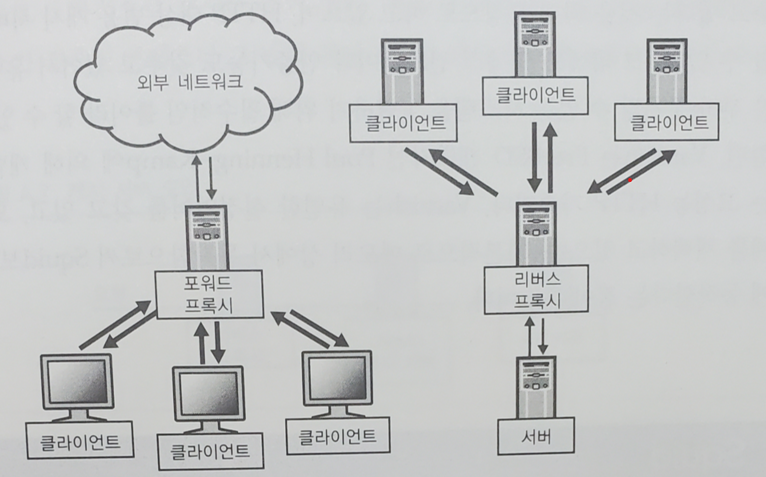
웹 애플리케이션의 부하가 서서히 증가해서 시스템 용량이 부족해졌을 때에는 AP 서버나 DB 서버를 증설함으로써 대응을 할 수도 있지만, HTTP 레벨의 캐싱을 수행하는 HTTP 가속기를 사용함으로써 낮은 비용으로 효과가 높은 대책을 세울 수도 있다.HTTP 액세스를 고