국소성을 고려한 분산
캐시 용량을 늘리기 위해 어떻게 하면 여러 대의 서버로 확장시킬 수 있는지에 대해 알아보자. 국소성은 locality라고도 한다.
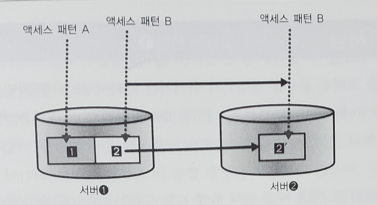
서버1과 2 양측에 별다른 액세스 패턴을 고려하지 않고 분배한 경우, 데이터 영역 2로의 엑세스는 계속되므로 서버1이 데이터 영역2도 캐싱해야 할 필요가 있다. 그러나 그림처럼 액세스 패턴을 고려해서 분배한 경우는 데이터 영역 2 부분은 더 이상 액세스되지 않으므로 그만큼 캐시영역을 다른 곳으로 돌릴 수 있다. 결국 시스템 전체로서는 메모리에 올라간 데이터량이 늘어나게된다.
파티셔닝
국소성을 고려한 분산을 실현하기 위해서는 파티셔닝이라는 방법을 자주 상요한다. 파티셔닝(partitioning)은 한 대였던 DB서버를 여러 대의 서버로 분할하는 방법을 말한다. 분할 방법은 여러 가지가 있지만, 간단한 것은 '테이블 단위 분할'이다.
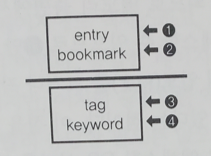
12는 같이 엑세스하는 경우가 많으므로 같은 서버에 위치시키고 있다. 34 테이블은 각각 꽤 커서 10GB 정도 된다. 12와 같은 서버에 두게되면 전부 캐싱할 수 없다. 그래서 이렇게 나누었다.
다른 분할 방법은 '테이블 데이터 분할'이다. 특정 테이블 하나를 여러 개의 작은 테이블로 분할하는 것이다.
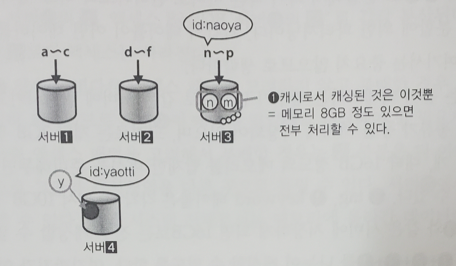
id를 기준으로 테이블을 나눴다. 이 분할의 문제점은 분할의 입도를 크거나 작게 조절할 때 데이터를 한번 병합해야 한다는 번거로움이 있다는 것이다. 그것을 제외하면 애플리케이션에서 할 일은 ID의 첫 문자를 보고 엑세스할 db 서버를 분배하는 처리를 살짝 넣기만 하면 된다.
요청 패턴을 '섬'으로 분할
'용도별로 시스템을 섬으로 나누는 방법'도 있따. 예를 들어 통상의 사용자면 섬1, 일부 API 요청이면 섬3, Google bot이면 섬2와 같은 식으로 나누는 것이다.
검색 봇은 그 특성상 아주 오래된 웹 페이지에도 엑세스하러 온다. 그렇게 되면 캐시가 적용하기 어렵다.
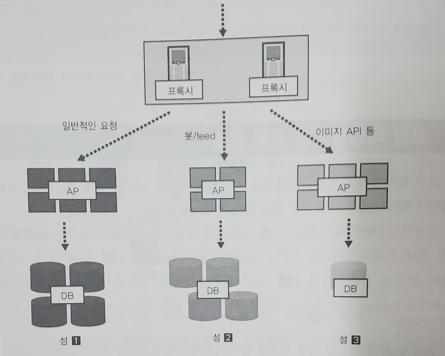
이렇게 해서 캐싱하기 쉬운 요청, 캐싱하기 어려운 요청을 처리하는 섬을 나누게 되면, 전자는 국소성으로 인해 안정되고 높은 캐시 적중률을 낼 수 있게 된다.
페이지 캐시를 고려한 운용의 기본 규칙
-
OS 기동 직후에 서버를 투입하지 않는다는 것. 캐시가 쌓여있지 않아서이다. 그래서 OS를 시작해서 기동후 자주 사용하는 DB 파일을 한번 cat해주면 모두 메모리에 올라간다. 그 후 로드밸런서에 편입시킨다.
-
성능평가는 캐시가 최적화되었을 떄 실행한다.
