KNN(K-Nearest Neighbor) 알고리즘
KNN(K-Nearest Neighbor) 알고리즘은 새로운 데이터로부터 거리가 가까운 'k'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘이다.
*KNN 알고리즘은 일반적으로 분류에 사용되지만 회기로써도 사용될 수 있다.
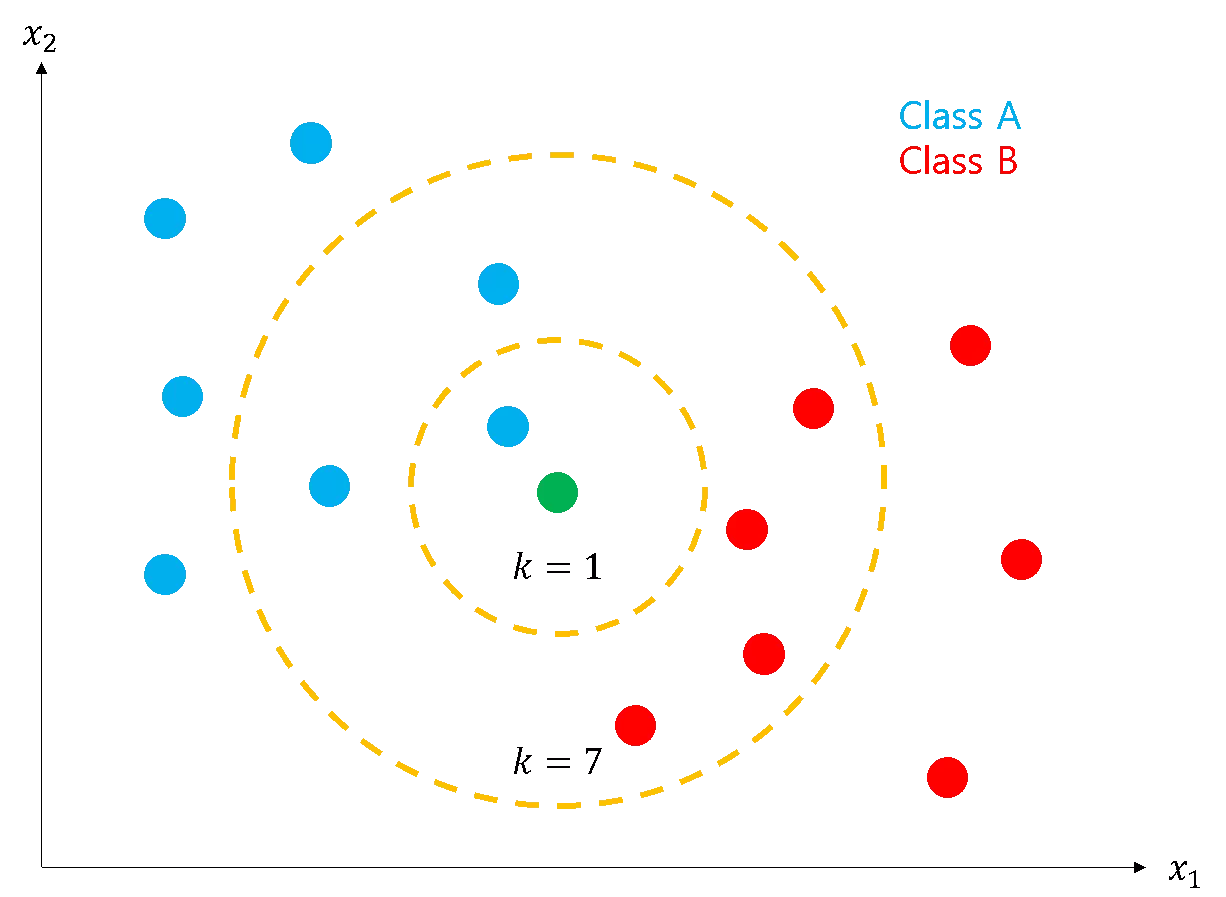
예를 들어 k=1인 경우 새로운 데이터는 A로 분류되고, k=7인 경우 B로 분류된다. 일종의 다수결이다.
그러나 KNN 알고리즘에는 몇가지 생각해볼 문제가 있다.
1. 정규화(Normalization)
우리는 데이터가 가진 feature가 모두 동일한 스케일(중요도)로 반영되도록 하기 위해 정규화(Normalization) 과정을 거쳐야한다. 정규화하는 방법은 대표적으로 2가지가 있다
- 최소값을 0, 최대값을 1로 고정한 뒤, 모든 값들을 0과 1사이 값으로 변환하는 방법
- 평균과 표준편차를 활용하여 평균으로부터 얼마나 떨어져있는지 z-점수로 변환하는 방법
2. K 개수 선택
우리는 'k'를 몇으로 정할지 고려해야한다. k가 너무 작을 때는 Overfitting 이 일어나고, k가 너무 클 때는 Underfitting 이 일어난다. 따라서 적절한 k의 값을 정해야 한다.
KNN의 회기 수행
KNN은 일반적으로 분류를 수행하지만 회기를 수행할수도 있다. 이 경우도 역시 시작은 가장 가까운 k개의 이웃을 찾을 것이다. 그러나 분류에서는 이웃의 레이블 개수를 확인해 다수결로 정했지만, 회귀에서는 이웃들의 평균을 계산한다는 점에서 차이가 있다. 그래서 만약 가장 새로운 영화와 거리가 가까운 3개의 영화가 5.0, 6.8, 9.2의 등급을 가졌다면 이 영화의 등급이 7.0이라고 예측할 수 있다.
여기서 좀 더 나아가 거리가 가까운 영화의 값에 가중치를 줄 수 있다. 거리가 가까울수록 데이터가 더 유사할 것이라고 보고 가중치를 부여하는 것이다.

better than yesterday