K-means 알고리즘
K-means 알고리즘은 k 값이 주어졌을때, 주어진 데이터들을 k 개의 클러스터로 묶는 알고리즘으로 비지도학습의 대표적인 클러스터링 기법 중 하나이다.
알고리즘의 매커니즘은 다음과 같다

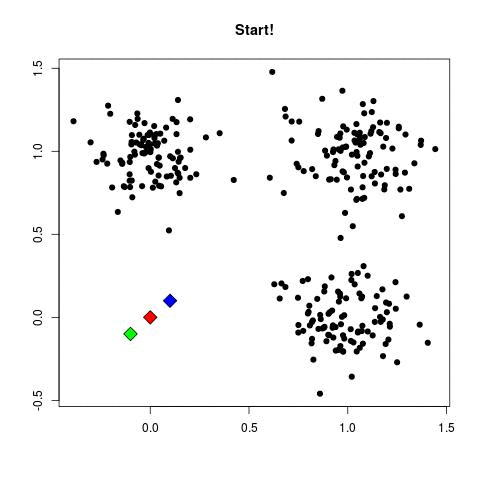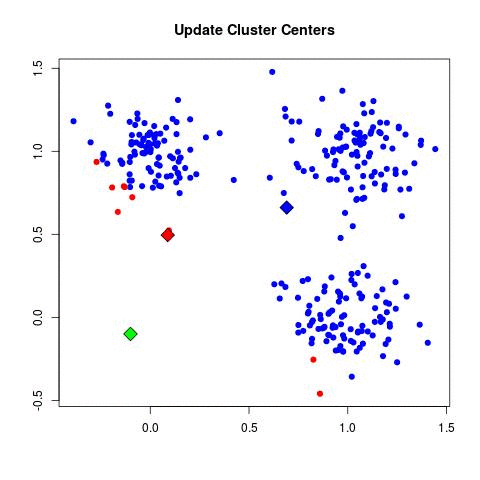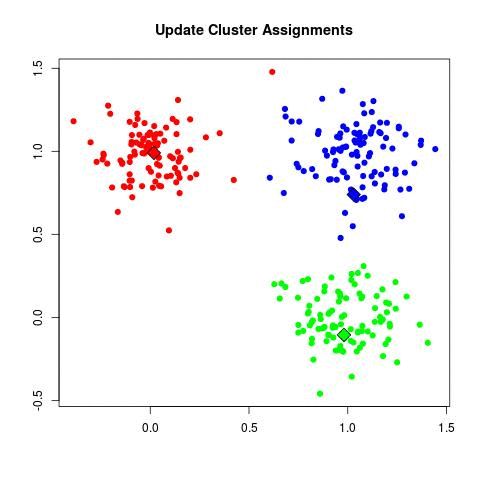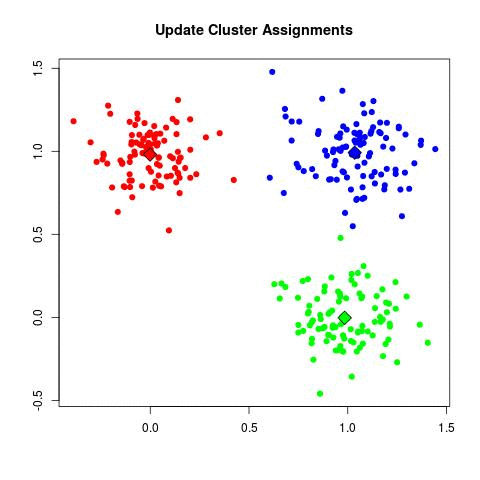
Step 1: 군집화의 기준이 되는 중심을 구성하려는 군집 개수만큼 정함
Step 2: 각 데이터는 가장 가까운 곳에 위치한 중심점에 속함
Step 3: 소속이 결정되면 군집 중심점을 소속된 데이터의 평균 중심으로 이동함
Step 4: 기존에 속한 중심점보다 더 가까운 중심점이 있다면 해당 중심점으로 다시 소속 변경
Step 5: 다시 중심을 소속된 데이터의 평균 중심으로 이동
Step 6: 위 프로세스를 반복, 데이터의 중심점 변경이 없으면 반복 중단 및 군집화 종료
참고 자료
https://velog.io/@hyesoup/%EC%A0%95%EA%B7%9C%ED%99%94Normalization

better than yesterday