머신러닝/딥러닝
1.[1일차] 첫 머신러닝
인공지능과 머신러닝, 딥러닝인공지능사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술인공일반지능(강인공지능) vs 약인공지능인공일반지능(강인공지능)사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템약인공지능현실에서 우리가 마주하고 있는 인공지능,
2.[2일차] 데이터 다루기
지도 학습입력(데이터)과 타깃(정답)으로 이뤄진 훈련 데이터가 필요. 알고리즘이 정답을 맞히는 것을 학습 ex) 도미인지 빙어인지 구분비지도 학습타깃 없이 입력 데이터만 사용, 정답을 사용하지 않으므로 무언가를 맞힐 수 없다. 대신 데이터를 잘 파악하거나 변형하는데 도
3.지도학습, 비지도학습

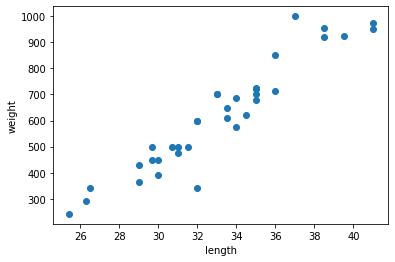
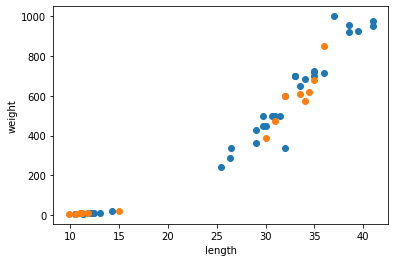
"정답 라벨이 있는" 데이터를 활용해 데이터를 학습시키는 것이다. 입력값(X data) 이 주어지면 입력값에 대한 Label(Y data)를 주어 학습시키며 대표적으로 분류, 회기 문제가 있다.1) 분류(Classification): discrete한 value로 분류
4.(지도학습-분류&회기) KNN(K-Nearest Neighbor) 알고리즘
KNN(K-Nearest Neighbor) 알고리즘은 새로운 데이터로부터 거리가 가까운 'k'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘이다.\*KNN 알고리즘은 일반적으로 분류에 사용되지만 회기로써도 사용될 수 있다.예를 들어 k=1인 경우 새로운 데이터는
5.(비지도학습-클러스터링) K-means 알고리즘
K-means 알고리즘은 k 값이 주어졌을때, 주어진 데이터들을 k 개의 클러스터로 묶는 알고리즘으로 비지도학습의 대표적인 클러스터링 기법 중 하나이다.알고리즘의 매커니즘은 다음과 같다Step 1: 군집화의 기준이 되는 중심을 구성하려는 군집 개수만큼 정함Step 2: