1. 통계 vs 머신러닝
용어
| 통계학 | 머신러닝 |
|---|---|
| 종속변수 | 레이블(타겟) |
| 독립변수 | 특성(column) |
| 케이스 | 인스턴스(row) |
| 분석법(모델) | 알고리즘 |
분석 단위
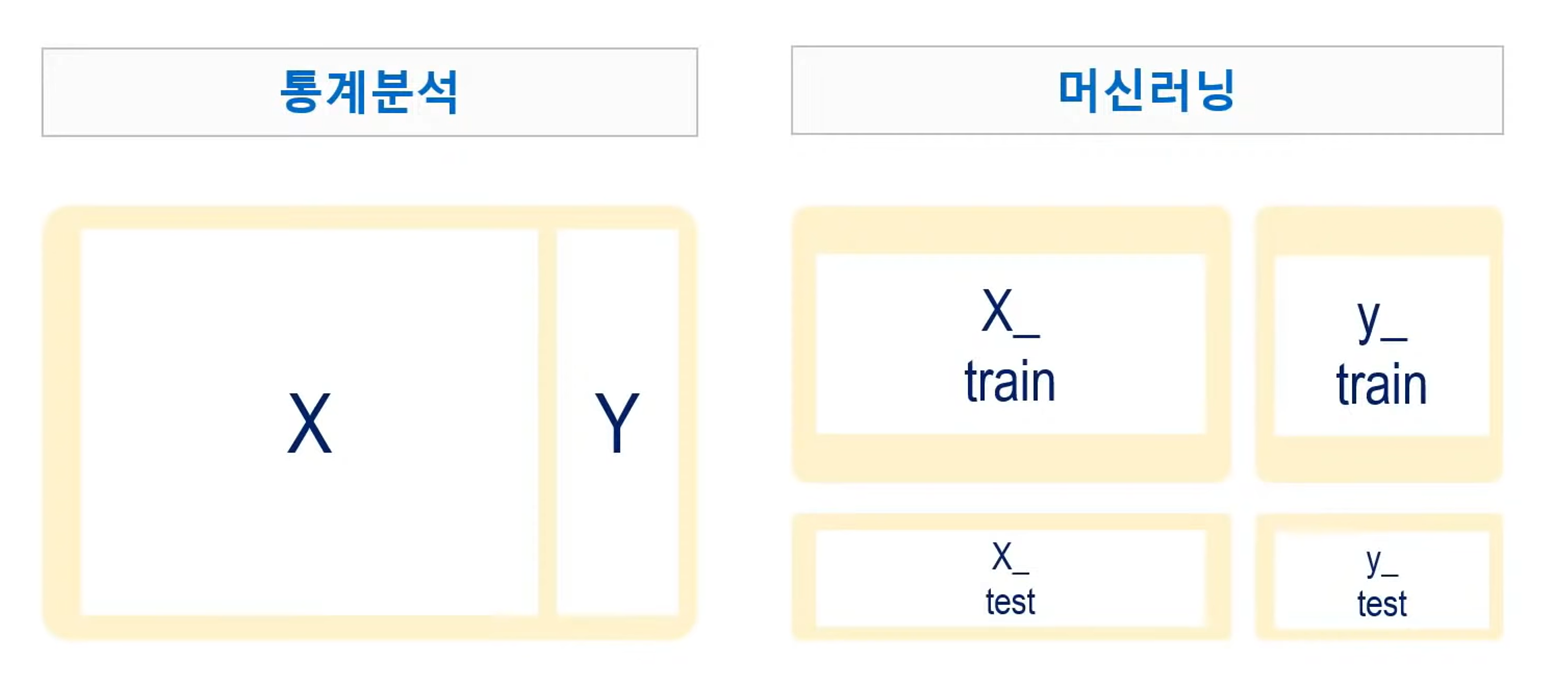
통계분석 : X(모집단)와 Y(표본)로 구성
머신러닝 : 전체 데이터를 학습데이터와 테스트 데이터로 나눔 ➡ 타겟을 Y로 별도로 설정
검증/평가
통계분석
- 이론/기준 (귀무가설)을 바탕으로 현상(데이터)을 통계적으로 추론
ex) 현상이 일어날 확률이 x%이다 - 적은양의 표본으로 모집단을 추론
머신러닝
- 표본을 추출하는 것이 아니라, 전체 데이터로 전체 데이터의 추세를 판단(회귀)하고, 집단을 나눈다(분류)
2. 통계와 머신러닝 실제 분석 차이
가 있는데 adj를 사용하는 이유
- 독립변수의 수가 증가하면 설명력도 같이 증가하는 오류를 막기 위해 사용
=> 설명력 / 독립변수의 수(k-1) = adj
결과에서 std err를 말해주는 이유

- 이게 머신러닝과 통계의 가장 큰 차이점이다
- "다른 표본을 조사했을 때 이정도의 오차가 있을 수 있다" (통계에서는 오차가 중요!)

:]