1. Four Type of Data Scale

자료 구분
범주형 자료 : 명목척도, 서열척도
연속형 자료 : 등간척도, 비율척도
2. Statistics vs Machine Learning
✔ 통계적 방법 - 얼마나 잘 추정하냐
: 집단간 혹은 변인 간 관련성과 영향정도를 표본집단으로부터 분석하여 모집단을 추정하기 위한 목적
✔ 머신러닝 방법 - 얼마나 잘 맞추냐
: 종속변수(레이블)가 존재하는지에 따른 지도학습과 비지도학습의 구분, 혹은(예측), 분류, 군집, 연관의 4대 머신러닝 기법 적용
3-1. Data Scale Type in Statistics
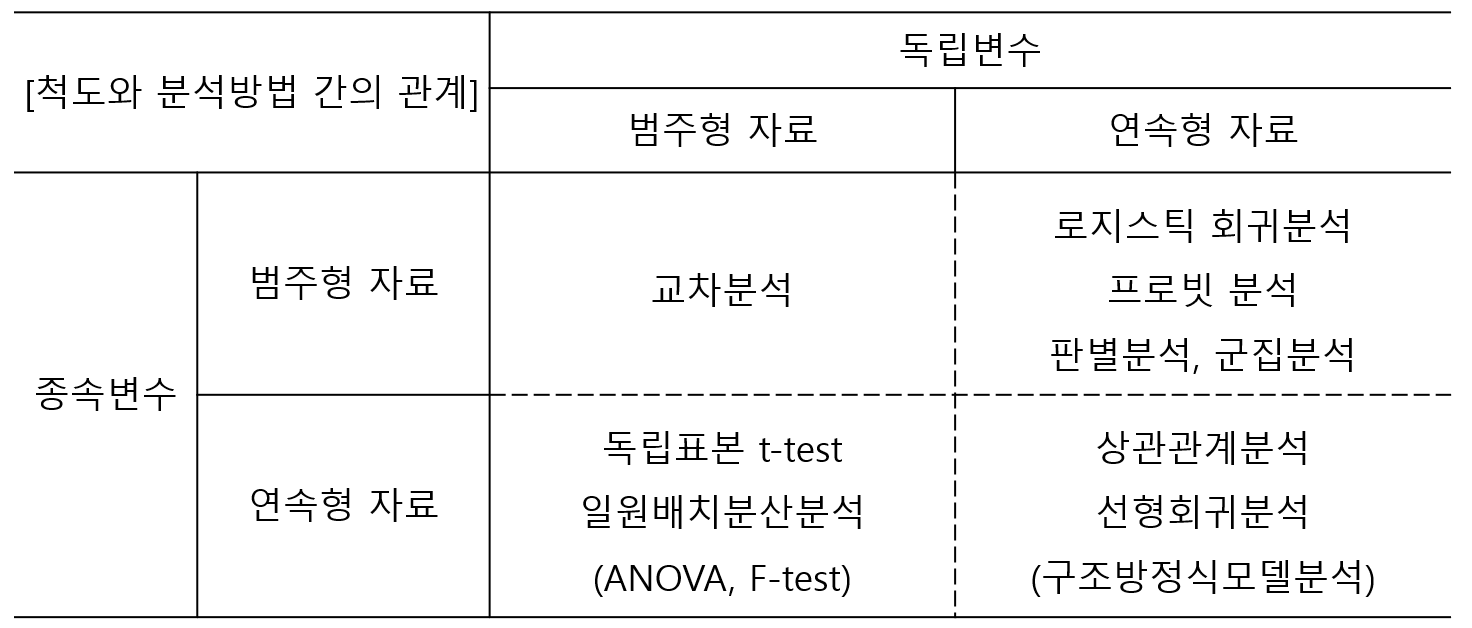
1) 교차분석
독립변수가 범주형 자료이고, 종속변수도 범주형 자료인 경우, 두 변수 간의 관계를 파악하는 통계분석 방법
예시
| 구분 | A당 | B당 | C당 | 전체 | |
|---|---|---|---|---|---|
| 남 | 80 | 15 | 5 | 100명 | 카이제곱 = 12.232 |
| 여 | 40 | 35 | 25 | 100명 | p = 0.021 |
| 전체 | 120 | 50 | 33 | 200명 |
2) t-test와 분산분석
- 독립변수가 연속형 자료이고, 종속변수도 연속형 자료인 경우
- 광고횟수와 매출 간에 상관이 있는지 탐색적으로 파악하고자 하면 두 변수들 간의 상관계수와 유의성 여부로 판단함
2집단의 설탕 농도 예시 - t-test
| 구분 | N | 평균 | 표준편차 | t-value | p |
|---|---|---|---|---|---|
| A공장 | 100 | 3.4 | 0.23 | 0.897 | 0.543 |
| B공장 | 100 | 3.2 | 0.34 |
3집단의 설탕 농도 예시 - F-test
| 구분 | N | 평균 | 표준편차 | t-value | p |
|---|---|---|---|---|---|
| A공장 | 100 | 3.4 | 0.23 | 0.894 | 0.847 |
| B공장 | 100 | 3.2 | 0.34 | ||
| C공장 | 100 | 3.3 | 0.27 |
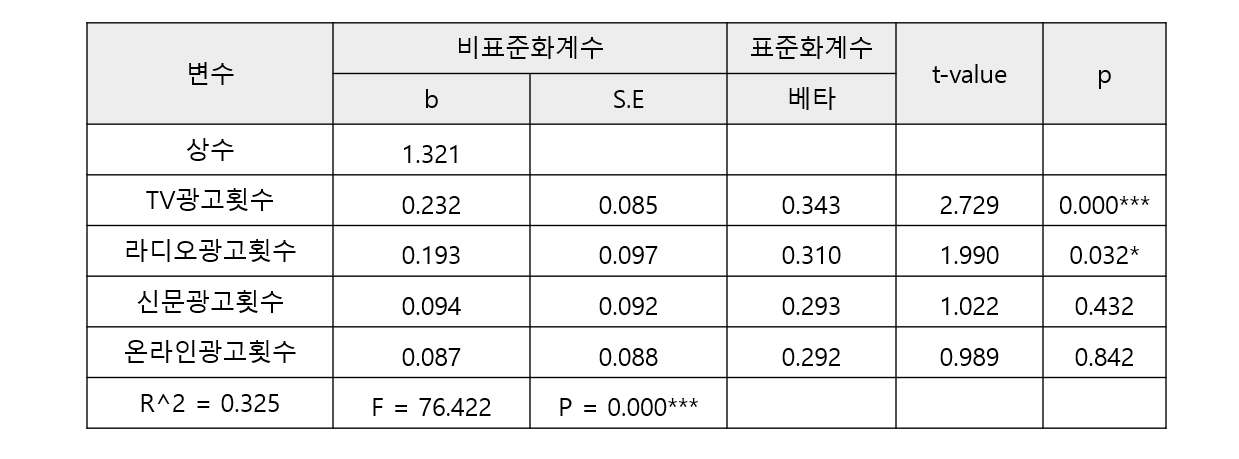
3) ★★ 상관관계와 선형회귀분석
- 매체의 광고가 매출에 영향이 있는지를 파악하고자 할 때 사용
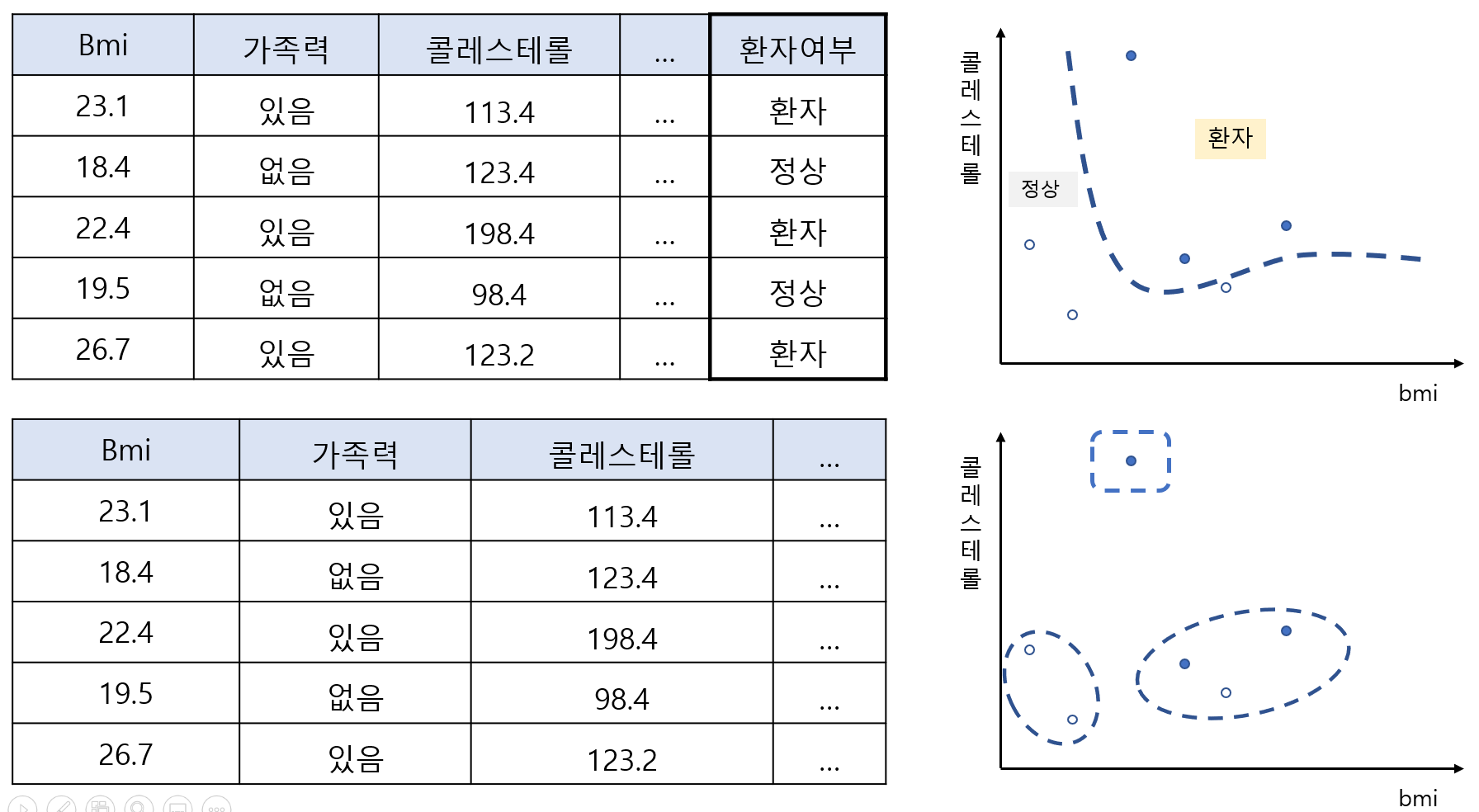
3-2. Data Scale Type in Machine Learning
1) 지도 vs 비지도
- 지도학습 : y가 있는 형태
- 목적 : 분류하고 나누는 선을 찾는 것
- 직선으로 나눈다 : 선형 알고리즘
- s자 모형으로 나눈다 : 로지스틱, 시그모이드 함수
- 비지도학습 : y가 없는 형태
- 목적 : 군집을 파악하는 것
2) 지도학습 알고리즘
| 모델 | 설명 |
|---|---|
| 로지스틱 회귀(Logistic Regression) | 반응변수가 범주형인 경우 적용되는 회귀 분석 모형 |
| 인공신경망 분석(Artificial Neural Network) | 인간의 뉴런 구조를 모방하여 만든 기계학습 모델 |
| 의사결정나무(Decision Tree) | 데이터들이 가진 속성들로부터 분할 기준 속성을 판별하고, 분할 기준 속성에 따라 트리 형태로 모델링하는 분류 및 예측 모델 |
| 서포트 벡터 머신(Support Vector Machine) | 데이터를 분리하는 초평면(Hyperplane) 중에서 데이터들과 거리가 가장 먼 초평면을 선택하여 분리하는 지도 학습 기반의 이진 선형 분류 모델 |
| 랜덤 포레스트(Random Forest) | 의사결정나무 특징인 분산이 크다는 점을 고려하여 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기반들을 생성한 후 이를 선형 결합하여 최종 학습기를 만드는 방법 |
3) 비지도학습 알고리즘
| 모델 | 설명 |
|---|---|
| 군집 모델 (Clustering Model) | 이질적인 집단을 몇 개의 동질적인 소집단으로 세분화하는 작업 |
| . | 1. 데이터에 숨어있으면서 동시에 발생하는 사건 혹은 항목 간의 규칙을 수치화 |
| 연관규칙 모델 (Association Rule Model) | 2. 연관 분석은 장바구니 분석이라고도 불리며 주로 마케팅에서 활용됨 |
| . | 3. 연관 분석은 고객의 구매 데이터를 분석하여 "어떠한 상품이 또 다른 어떠한 상품과 함께 판매될 확률이 높은가?"와 같은 연관된 규칙을 도출하는 기법 |
지도 학습 vs 비지도 학습
| 구분 | 지도 학습 | 비지도 학습 |
|---|---|---|
| 목적 | x가 y를 예측, 분류 | x를 가지고 관계들을 파악 |
| . | 분류 (y변수가 군집일 때) | 군집 (유사한 집단이 몇 개 형성되냐) |
| . | 회귀 (y변수가 숫자일 때) | 연관 (a가 발생했을 때 b도 발생하냐) |



:]