
패션 MNIST, tensorflow
-
패션 MNIST 데이터셋을 활용해 인공신경망에 대해 알아보고자 한다.
-
이때 tensorflow와 keras를 사용했다.
-> [keras는 딥러닝 모델을 쉽게 구축하고 훈련시키기 위한 파이썬의 딥러닝 라이브러리 중 하나입니다. Keras는 사용하기 쉽고 간결한 API를 제공하여 딥러닝 모델을 만들고 훈련시키는 데 도움을 줍니다.] -
input 데이터는 train은 60000개, test는 10000개가 28*28배열로 되어있고, target은 1차원 배열로 되어있다.

-
샘플 데이터로 10개만 출력해서 보면 아래와 같은 이미지로 구성되어 있음을 확인할 수 있다.

-
unique() 함수를 사용하여 train_input을 살펴보면, 10개의 레이블이 각각 6000개씩 들어있는 것을 확인할 수 있다.
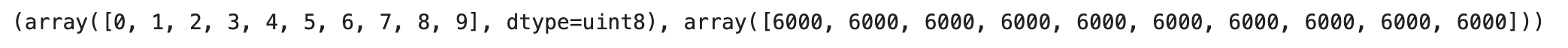
인공신경망이란?
- 28*28인 2차원 배열로 되어있는 train_input 데이터를 1차원 배열로 바꿔주면 (60000, 28, 28)이 (60000, 784)로 변환된다.
-> x1-x784는 입력층으로 각 이미지당 픽셀이 784개가 있기 때문에 784개의 입력층이 존재하게 된다. y1-y10은 출력층이며 10개의 레이블이 있기 때문에 출력층에 10개의 뉴런이 존재한다.
-> 각 뉴런으로 향하는 다른 색깔의 화살표는 각 픽셀에 곱해지는 가중치로 같은 색상의 화살표라도 각 필셀마다의 가중치는 다르다.
-> 입력층과 출력층 사이의 화살표료 표시된 층을 밀집층이라고 부르며 양쪽의 뉴럽이 모두 연결되어 있으면 완전 밀집층이라고 부른다.
인공신경망 모델링
- 먼저 훈련 세트와 검증 세트로 나누어 준다.
from sklearn.model_selection import train_test_split
# 255로 나누는 이유는 패션 MNIST 데이터셋의 각 픽셀이 0-255 사이의 값을 갖기 때문에 이를 0-1사이로 정규화하기 위함.
train_scaled = train_input/255.0
# -1은 첫 번째 차원(행)의 크기를 나타내며, 이 값을 -1로 설정하면 다른 차원(열)의 크기와 맞춰지도록 자동으로 계산됨.
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled,train_target, test_size=0.8, random_state=42)
#이때 random_state 파라미터는 원하는대로 넣어도 됨. - 밀집층을 만들어 신경말 모델에 전달한다.
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
# 10: 뉴런 개수
# input_shape: 입력의 크기
model = keras.Sequential(dense)-> 소프트맥스는 활성화 함수로 뉴런에서 출력되는 값을 확률로 바꾸어주는 역할을 한다. 이때 활성화 함수는 뉴런의 출력에 바로 적용되기 때문에 넓은 의미로 층이라고 볼 수 있다.
- compile()을 사용하여 손실함수, 계산하고 싶은 측정값을 지정한다.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')- 모델을 훈련시켜 성능을 평가해보자
# epochs는 반복회수
model.fit(train_scaled, train_target, epochs=5)
model.evaluate(val_scaled, val_target)
-> 훈련세트와 검증세트 모두 84%의 성능을 보이고 있다.
심층신경망이란?
- 입력층과 출력층 사이의 a1-a100과 같은 모든 층을 은닉층이라고 한다. 은닉층의 활성화 함수는 시그모이드, 렐루 등을 사용한다. 이때 은닉층에 활성화 함수를 사용하는 이유는 선형 계산을 비선형 계산으로 비틀어주기 위함이다.
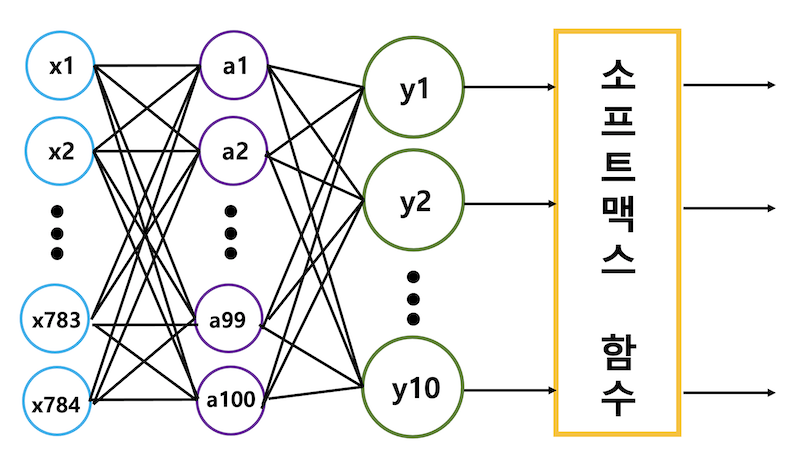
심층 심경망 모델링
- 인공 신경망 모델링과 동일하게 학습 데이터와, 검증 데이터로 나눈 후, 하나의 은닉층을 형성해 심층신경망(DNN)을 만든다.
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')
model = keras.Sequential([dense1, dense2])-> 은닉층의 뉴런의 개수는 적어도 출력층의 뉴런의 수보다는 많게 설정해야한다.
-> model.summary()를 사용하면 층에 대한 정보를 볼 수 있다.

--> 출력 크기를 보면 첫 번째 차원은 샘플의 개수를 나타내는데, 두 층 모두 None인 이유는 샘플의 개수가 아직 정의되어 있지 않기 때문이다. 케라스 모델의 fit() 메서드에 훈련 데이터를 넣으면 미니배치 하강법을 수행한다. 기본 미니배치 크기는 32개이지만, 변경할 수 있기 때문에 None으로 설정한다.
--> 두 번째 차원은 출력되는 뉴런의 개수로 784개가 첫 은닉층을 통과하면서 100개로 압축되고, 두 번째 출력층을 통과하면서 10개로 압축된다.
-> Sequential 클래스의 생성자 안에서 바로 Dense 클래스의 객체를 만들수도 있다.
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))렐루 함수
- 활성화 함수로 렐루 함수를 사용할 수도 있다. 이 함수는 z가 0보다 크면 z를 출력하고 z가 0보다 작으면 0을 출력한다. 특히 이미지 처리에서 좋은 성능을 낸다고 알려져 있다.
Flattern
- reshape() 대신 Flatten 클래스를 사용하여 입력 차원을 일렬로 펼칠 수 있다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))옵티마이저
- 옵티마이저: 케라스는 다양한 종류의 경사 하강법 알고리즘을 제공합니다. 기본적으로는 RMSprop(기본 경사 하강법)을 사용한다.
- SGD(확률적 경사 하강법)으로 변경하기 위해서는 아래와 같은 방법을 사용할 있다.
model.compile(optimizer='sqd', loss='sparse_categorical_crossentropy', metrics='accuracy')sgd = keras.optimizer.SGD()
model.compile(ooptimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')-
이외에도 momentum 매개변수를 변화시켜 모멘텀 최적화를 사용할 수도 있고, nesterov 매개변수를 기본값 False에서 True로 바꿔서 네스테로프 모멘텀 최적화를 사용할 수도 있다. learning_rate 매개변수를 변경할 수도 있다.
-
모델이 최적점에 가까이 갈수록 학습률을 낮출 수 있는 적응적 학습률를 사용할 수도 있다. 이때 optimizer은 Adagrad나 RMSprop를 사용할 수 있다.
드롭아웃
- 드롭아웃: 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 출력을 0으로 만들어서 과대적합을 막는 방법으로 아래와 같이 조정할 수 있다.
model = model(keras.layers.Dropout(0.3))-> 일부 뉴런의 출력을 0으로 만들지만 전체 출력 배열의 크기를 바꾸지는 않는다. 훈련이 끝난 뒤에 평가나 예측을 수행할 때는 드롭아웃을 적용하면 안되는데, 텐서플로와 케라스는 모델 평가와 예측시 자동으로 드롭아웃을 적용하지 않는다.
콜백
- 콜백: 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체이다.
- ModelCheckpoint와 save_best_only=True를 사용하면 가장 낮은 검증 점수를 만드는 모델을 저장할 수 있다.
- EarlyStopping와 restore_best_weights=True를 사용하면 과대적합이 시작되기 전에 훈련을 미리 중지하는 조기 종료를 사용할 수 있다.
-> 이때 patience 매개변수를 이용하여 검증 점수가 향상되지 않더라도 참을 에포크 횟수를 지정할 수 있다.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbakcs.ModelCheckpoint('best-model.h5', save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_wights=True)
model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb], callbacks=[checkpoint_cb, early_stopping_cb])
# verbose=0은 각 에포크마다의 값을 보여주는 것을 생략한다는 의미참고
-
인공신경망에서는 교차검증을 잘 사용하지 않고 검증세트를 별도로 덜어내어 사용한다.
-> 그 이유는 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적이고, 교차 검증을 수행하기에는 훈력 시간이 너무 오래 걸리기 때문이다. -
다중 분류에는 소프트맥스 함수를, 이진 분류에는 시그모이드 함수를 사용한다.
-
다중 분류에서는 손실함수로 categorical_crossentropy를 사용하고, 이진 분류에서는 binary_crossentropy를 사용한다.
