분류
- 아이리스 꽃 품종을 분류하는 모델을 작성
원핫 인코딩
-
수식의 결과는 범주형 데이터인 문자열이 못오는 경우나 독립변수가 범주형 데이터에서 수식에 넣을수 없기 때문에 변경이 필요하다.
-
범주형 -> 숫자형 으로 변경하는 작업이다 (1/0)
-
Decision Tree , Random Forest , XGBoost , LigitGBM 은 원핫 인코딩이 필요가 없다.
-
만약 종속변수가 원핫 인코딩을 수행하면 그만큼 종속변수에 결과 가 늘어난다.
sigmoid
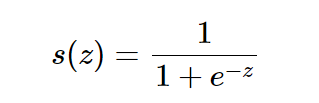
- 0 ~ 100 사이의 확률로 만들고 싶어서 sigmoid(확률함수) 를 사용한다.
- 범주의 결과는 합이 항상 1이고 각각의 범주가 결정되는 확률 이 나타난다.
softmax
- 분류를 예측할때는 확률로 예측을 한다.
- 비가 올 확률 , 합격할 확률 , 당첨될 확률
- 범주의 결과는 합이 항상 1이고 각각의 범주가 결정되는 확률 이 나타난다.
crossentropy
- 시그모이드에 기반한 loss 함수
- 확률로 만든 결과값들을 비교하기 위한 기능
- softmax - categorical_crossentropy / sigmoid - binarycrossentropy
활성화 함수(Activation)
- 퍼셉트론의 출력값을 결정하는 활성화 함수이다.
- Identity (회귀모델)
- Softmax(분류모델)
metrics
- loss 값만 보고 모델이 얼마나 좋은지는 모른다 따라서 metrics 값에 정확도를 볼수 있는 수치를 적어줘야 한다.
실습
데이터 준비
# 데이터 준비
path = "https://raw.githubusercontent.com/blackdew/ml-tensorflow/master/data/csv/iris.csv"
data = pd.read_csv(path)
data.head()
data = pd.get_dummies(data)
data.head()
x = data[['꽃잎길이' , '꽃잎폭','꽃받침길이','꽃받침폭']]
y = data[['품종_setosa','품종_versicolor','품종_virginica']]
print(x.shape , y.shape)모델 준비
# 모델을 준비한다.
X = tf.keras.Input([4])
Y = tf.keras.layers.Dense(3 , activation='softmax')(X)
model = tf.keras.Model(X,Y)
model.compile(loss='categorical_crossentropy',metrics='accuracy')
model.summary()모델 학습
#데이터로 모델을 학습한다.
model.fit(x,y,epochs = 500)모델 예측
#모델을 이용한다
model.predict(x[:10])모델 저장
model.save("my_model.h5") # "모델 이름.h5"모델 불러오기
m = tf.keras.models.load_model("my_model.h5") "불러올 모델의 이름.h5"
m.predict(x[:10])

개발자 되고 싶어요