딥러닝
1.딥러닝 - 1

사람의 뇌세포를 묘사해서 구조를 만들고 사람의 두뇌처럼 연결해 놓은것이 인공 신경망이다.과거의 데이터를 준비하고 -> 모델의 선택 및 구조를 만든다. -> 데이터로 모델을 학습 합니다 -> 모델을 이용한다.Input shape 와 Dense 안에 수치는 종속변수와 독립
2.딥러닝 - 2
보스턴 지역의 집값 을 예측 하는 모델을 작성독립 변수가 많은 데이터 하나의 뉴런 구조를 퍼셉트론이라고 부른다.y = 가중치 \* x + 편향(기본값) 가중치가 0 일떄 편향이 기본값이다.만약 종속 변수가 2개 라고 하면 수식도 2개가 생긴다.독립변수가 13개 가 있기
3.딥러닝 - 3
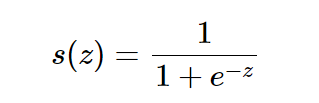
아이리스 꽃 품종을 분류하는 모델을 작성 수식의 결과는 범주형 데이터인 문자열이 못오는 경우나 독립변수가 범주형 데이터에서 수식에 넣을수 없기 때문에 변경이 필요하다.범주형 -> 숫자형 으로 변경하는 작업이다 (1/0) Decision Tree , Random Fore
4.딥러닝 - 4
Hidden Layer x->y 1층 구조가 아니라 x->y 사이에 hidden layer 를 추가하여 y를 가는과정이다 중간에 다른 데이터를 만들겠다는 과정 딥러닝이 스스로 히든 레이어를 유의미하게 만들었다 특징 자동 추출기 노드와 레이어 가 적을수록 좋다.
5.딥러닝 - 5
어떤값에서 예측 한값을 뺀것이 오차 이값을 제곱하면 loss 함수이다.loss 함수는 mse 를 사용한다 (Mean Squared Error)mse 가 최소가 되도록 하는 w 를 찾는것이 목표이다.$$e^x /e^x - 1$$loss 를 측정하는 함수 이다.0 ~ 1
6.딥러닝 - 6
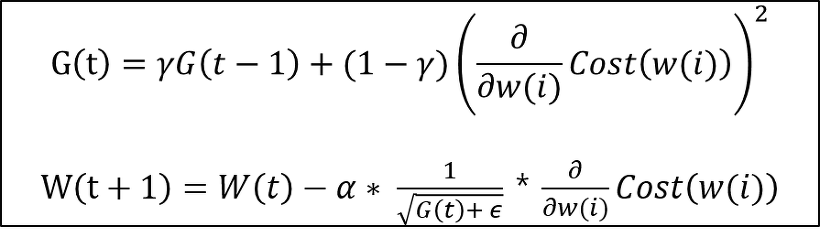
loss 가 가장 작아지는 지점을 찾는 방법함수의 기울기 를 구하여 함수의 극값에 이를 떄까지 기울기가 낮은 쪽으로 이동하는 방법 $$W(t+1) = W(t) - α ∂/∂w Cost(w)$$경사 하강법에서 얼만큼 이동할것인지에 대한 정보 경사 하강법에서 learn
7.딥러닝 - 7
관측치 = N 차원 공간의 한점변수의 개수 = 공간의 차원수 배열의 깊이 = 차원수 x1,x2,x3 는 1차원 이지만 변수를 하나의 차원으로 합치면 2차원이 된다.2차원 데이터를 하나의 표로 만들었기 떄문에 3차원 이다.784차원 공간에 점 6만개를 찍을수 있는 데이터
8.딥러닝 - 8
n차원 데이터 를 차원을 낮추는 작업이다model 의 input shape 을 맞추기 위해 사용하는 작업이다레이어에서 쉽게 처리하기 위해 만들어주는 역할을 합니다.train 만 이용할려면 학습하다가는 오래 걸린다 (overfitting )따라서 중간에 멈출수 있는 장치
9.딥러닝 - 9
훈련 데이터에 특화된 학습을 하게 되어 새로운 데이터에 대한 예측이 오히려 나빠지거나 학습이 효과가 나타나지 않는 상태 충분한 데이터 확보 (데이터가 부족한 경우를 해소)Dropout / Ensemble Batch NormalizationL1,L2 Regularizat
10.딥러닝 - 10
fit 함수 내에 call 로직을 수행하는데 커스터 마이징을 통해 model 에 구조를 작성따라서 히든 레이어 만들때는 call 함수 안에서 만들어야 한다.keras.model 을 만들려면 상속을 받아야 한다 무조건 !init 을 할떄 layer들에 기본적인 구조 in
11.딥러닝 - 11
현재에 유용한 무언가를 만들기 위한 굉장히 좋은 도구(프로그래밍)앞으로 유용한 무언가를 만들기 위해 매우 필요한 도구(딥러닝)함수를 만드는 프로그래밍 모델을 만드는 딥러닝직접 작성하지 않는다필요한 함수에 라이브러리 프레임워크를 찾는다함수 방법을 익힌다필요한 함수로 ap
12.딥러닝 - 12
다양한 언어 모델과 chatGPT 를 제공하는 회사이다학습이 끝난 모델로 서비스를 만들어 둔 상태라 설명서 대로 이용하면 된다.학습에 관련된 텍스트에 관한 설정을 조절할수 있다 (토큰 , 문장길이 등등)prompt 를 조절하여 다양한 앱을 만들어 줄수 있다.prompt