
🍒 CatboostRegressor에 User Defined Loss Function 사용하기
01. RMSLE 구현
def rmsle(y, pred):
log_y = np.log1p(abs(y))
log_pred = np.log1p(abs(pred))
squared_error = (log_y - log_pred)**2
rmsle = np.sqrt(np.mean(squared_error))
return rmsle02. User Defined Objective
1 ) 공식 문서에서 가이드하는 class
calc_ders_reange함수를 포함하는 class 작성- parameters : approxes, targets, weights
- weights : None일 수 있음
- approxes : 예측 값
- targets : 목표 값
- returns : (der1, der2)
- 1차 도함수와 2차 도함수 pair
- 1차 도함수 : 예측 값과 실제 값의 차이
- 2차 도함수 : 예측 값에 대한 오차의 변화율을 계산
- 1차 도함수와 2차 도함수 pair
- parameters : approxes, targets, weights
class UserDefinedObjective(object):
def calc_ders_range(self, approxes, targets, weights):
# approxes, targets, weights are indexed containers of floats
# (containers which have only __len__ and __getitem__ defined).
# weights parameter can be None.
#
# To understand what these parameters mean, assume that there is
# a subset of your dataset that is currently being processed.
# approxes contains current predictions for this subset,
# targets contains target values you provided with the dataset.
#
# This function should return a list of pairs (-der1, -der2), where
# der1 is the first derivative of the loss function with respect
# to the predicted value, and der2 is the second derivative.
pass
2 ) 구현
class RMSLEObjective(object):
def calc_ders_range(self, approxes, targets, weights):
assert len(approxes) == len(targets)
if weights is not None:
assert len(weights) == len(approxes[0])
max_delta_step = 0.7 # 추가: max_delta_step 값 설정
result = []
for index in range(len(targets)):
der1 = rmsle(targets[index], approxes[index])
der2 = -1
if weights is not None:
der1 *= weights[index]
der2 *= weights[index]
# 추가: max_delta_step 적용
der2 *= np.exp(approxes[index] + max_delta_step)
result.append((der1, der2))
return result03. User Defined Metric
1 ) 공식 문서에서 가이드하는 class
is_max_optimal,evaluate,get_final_error함수를 포함하는 class 작성is_max_optimal- metric이 클수록 더 나은 것인지 여부를 return
evaluate- parameters : approxes, targets, weights
- weights : None일 수 있음
- approxes : 예측 값
- targets : 목표 값
- returns : (error, weights sum)
- parameters : approxes, targets, weights
get_final_error- error와 weight에 기반한 metric의 최종 값
class UserDefinedMetric(object):
def is_max_optimal(self):
# Returns whether great values of metric are better
pass
def evaluate(self, approxes, target, weight):
# approxes is a list of indexed containers
# (containers with only __len__ and __getitem__ defined),
# one container per approx dimension.
# Each container contains floats.
# weight is a one dimensional indexed container.
# target is a one dimensional indexed container.
# weight parameter can be None.
# Returns pair (error, weights sum)
pass
def get_final_error(self, error, weight):
# Returns final value of metric based on error and weight
pass
2) 구현
class CustomMetric(object):
def get_final_error(self, error, weight):
return error
def is_max_optimal(self):
return False
def evaluate(self, approxes, target, weight):
assert len(approxes) == 1
assert len(target) == len(approxes[0])
approx = approxes[0]
log_target = np.log1p(np.abs(target))
log_approx = np.log1p(np.abs(approx))
squared_error = np.square(log_target - log_approx)
rmsle = np.sqrt(np.mean(squared_error))
return rmsle, 0
04. CatBoostRegressor
예측값인 ECLO가 대부분 평균치인 3~4에 몰려있고, 일부 높은 값을 가짐
- RMSLE를 실제 값과 예측 값의 상대적인 오차를 측정
예측 값이 실제 값보다 과대평가되는 경우에 패널티를 부여
1 ) 모델 선언
clf = CatBoostRegressor(iterations=10000,\
depth=10,\
learning_rate=0.01,\
cat_features=cat_col_list,\
random_state=42,\
# loss_function=RMSLEObjective, # The custom loss function
loss_function='RMSE',
eval_metric=CustomMetric(), # The custom evaluation metric
use_best_model=True) # Use the best model found during training)
clf.fit(X_train, y_train,
cat_features=cat_col_list,
early_stopping_rounds=200,
eval_set=(X_val, y_val),
use_best_model=True, plot=True,
)
print('CatBoost model is fitted: ' + str(clf.is_fitted()))
print('CatBoost model parameters:')
print(clf.get_params())2 ) 모델 선언
X = train_df[target_column]
y = train_df[prediction_column]
# ECLO의 분포가 다양하기 때문에 log 값을 취해줌
y = np.log1p(y)
# train, valid data 나누기
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# category 변수로 전달할 column 명 수집
datatype = X.dtypes
cat_col_list = datatype[(datatype == 'object') | (datatype == 'category')].index.to_list()
clf = CatBoostRegressor(iterations=500, depth=10, learning_rate=0.01,cat_features=cat_col_list,random_state=42,\
loss_function='RMSE', # The custom loss function
eval_metric=CustomMetric(), # The custom evaluation metric
use_best_model=True) # Use the best model found during training)
# clf = CatBoostRegressor(**grid.best_params_)
4 ) 학습
2분 소요
clf.fit(X_train, y_train,
cat_features=cat_col_list,
early_stopping_rounds=200,
eval_set=(X_val, y_val),
use_best_model=True, plot=True,
)
print('CatBoost model is fitted: ' + str(clf.is_fitted()))
print('CatBoost model parameters:')
print(clf.get_params())
valid_pred=clf.predict(X_val[target_column])
valid_pred = np.expm1(valid_pred)
rmsle(valid_pred, np.expm1(y_val['ECLO'])) # 0.443149781285607
Metric - RMSLE
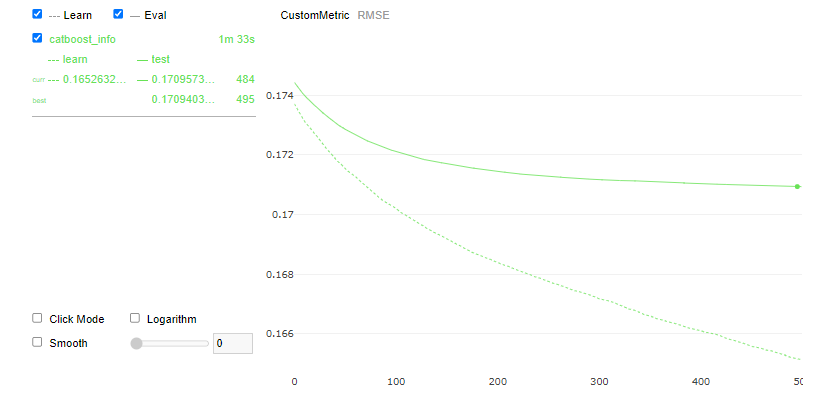
Metric - RMSE
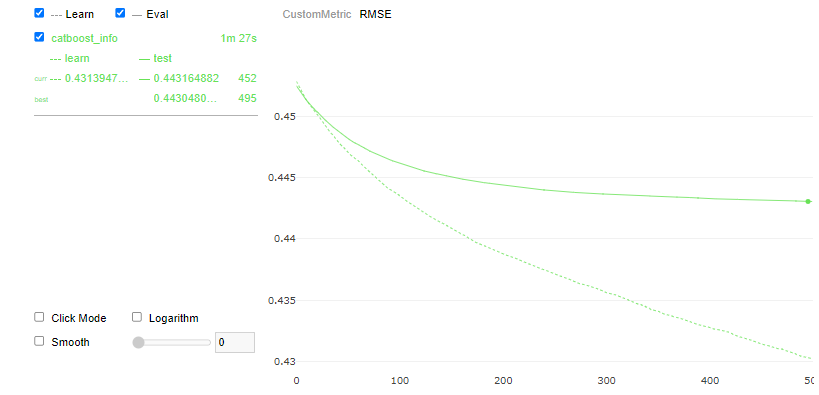
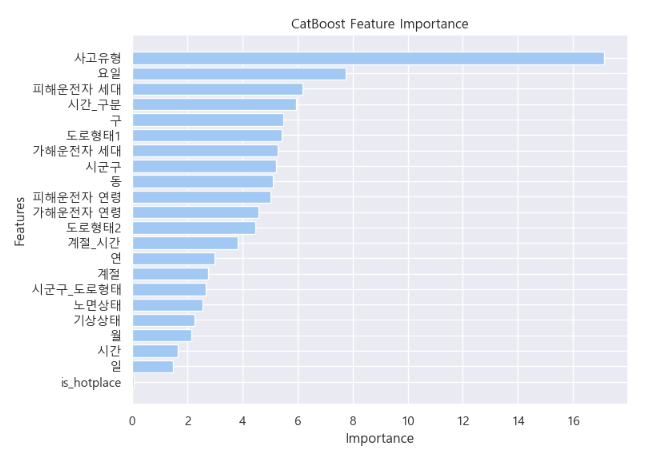
3 ) 변수 중요도
- is_hotplace의 경우, 대구 내 주요 시내를 1로 표시한 것
- 동성로, 두류동, 동천동
- 동성로, 광장코아, 칠곡 3지구
- 동성로, 두류동, 동천동
사고유형, 요일, 피해운전자 세대가 가장 중요한 변수로 꼽혔음
4 ) 평가
Public - 0.4278564328
Private - 0.4282959564
