[주제]
- 교통사고 정보로부터 사고위험도(ECLO) 예측 AI 모델 개발
[배경]
- 교통사고의 원인을 규명하고 대책을 세우기 위해 조건에 따른 ECLO를 예측하고자 함
※ ECLO(Equivalent Casualty Loss Only) : 인명피해 심각도
ECLO = 사망자수 10 + 중상자수 5 + 경상자수 3 + 부상자수 1
본 대회에서는 사고의 위험도를 인명피해 심각도로 측정
01. 영향 요소 생각하기
- 사고가 자주 발생하는 시군구, 도로가 존재할 것임
- 부산의 연산교차로나 서면 같이 통행량이 많고, 도로가 복잡한 지점
- 인구 밀집, 고령화 동네, 횡단보도 통행 시간이 짧거나 부족한 경우
- CCTV 등 보조 시스템이 부족한 경우
- 교통량이 증가하는 출퇴근 시간에 사고 발생 횟수가 많을 것임
- 새벽 시간대에 치명적인 교통사고가 많이 발생할 것임
- 높은 ECLO
- 사망 교통사고이면서 가해/피해 운전자의 연령대가 높을수록 사망확률이 높을 것임
- 비가 오거나 눈이 온 경우, 사고 확률이 높을 것임
02. EDA 결론
- 도로유형 별로 사고가 잦은 곳과 ECLO가 평균보다 높은 곳이 있음
- ECLO가 높은 사고일 경우, 주말에 발생건수가 더 많음
- 출퇴근 시간에 사고 발생 횟수가 더 많음
- 새벽시간 대의 경우 사고 발생 횟수는 적지만 ECLO가 높음
- 천에 인접하고 자전거 대여소가 있는
비산동에서 자전거 사고 발생 횟수가 많음 - 가해운전자/피해운전자 연령에 따라 상해정도가 차이 날 수 있음
통행량이 많은 곳에서 사고 발생 횟수가 많아짐
도로 폭, 레인 수, 혼잡 지역 여부(관광지, 시장, 시내, 교회 등)가 주요 외부 요소가 될 수 있음
02. EDA
1 ) 제공 데이터 null 비율 확인
# dataset의 각 column에 존재하는 null 값 비율 확인
nullvalues = ((train_df.isna().sum() / train_df.shape[0])*100).reset_index().rename({0:'count'}, axis = 1)
nullvalues.style.highlight_max('count')

# 991건
train_df[train_df['피해운전자 성별'].isna()].groupby('사고유형').count()차량 단독 사고인 경우, 피해운전자의 정보가 제공되지 않음
2 ) 사상자가 1명보다 많으면서 차량 단독 사고인 경우
- 버스 교통사고인 경우 사상자의 수가 많아 ECLO도 높은 경향
- 차량 단독 사고인 경우, 노면 상태가 젖음/습기 일때, 평균보다 높은 ECLO를 보임
# 필터링된 데이터 추출
filtered_data = train_df[(train_df['사상자합계'] > 1) & (train_df['피해운전자 성별'].isna())]
# ECLO 컬럼 시각화 - 바이올린 플롯
plt.figure(figsize=(5, 4))
sns.violinplot(y=filtered_data['ECLO'], color='skyblue')
plt.ylabel('ECLO')
plt.title('사상자가 2명이상인 경우 ECLO')
plt.show()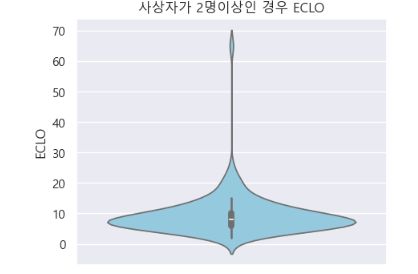
a ) ECLO가 가장 높은 행
- 20년 09월 22일에 발생한 버스 교통사고 판결문
차량 단독 교통사고 중 ECLO가 가장 높은 것은 버스 교통사고
b ) 노면상태에 따른 사고 횟수와 ECLO 평균
# 노면상태 별 사고 횟수 시각화 (막대 그래프)
plt.figure(figsize=(10, 6))
ax1 = sns.countplot(x='노면상태', data=filtered_data, color='skyblue')
ax1.set_ylabel('사고 발생 횟수')
# 노면 상태 별 ECLO 평균 시각화 (선 그래프)
ax2 = ax1.twinx()
sns.lineplot(x='노면상태', y='ECLO', data=filtered_data, color='r', ax=ax2)
ax2.set_ylabel('ECLO')
# ECLO 평균 값의 수평선 추가
avg = filtered_data['ECLO'].mean()
ax2.axhline(avg, ls='--', label=f'ECLO 평균 ({round(avg, 2)})', color='g')
ax2.legend()
plt.title('노면상태에 따른 사고 횟수와 ECLO 평균')
plt.show()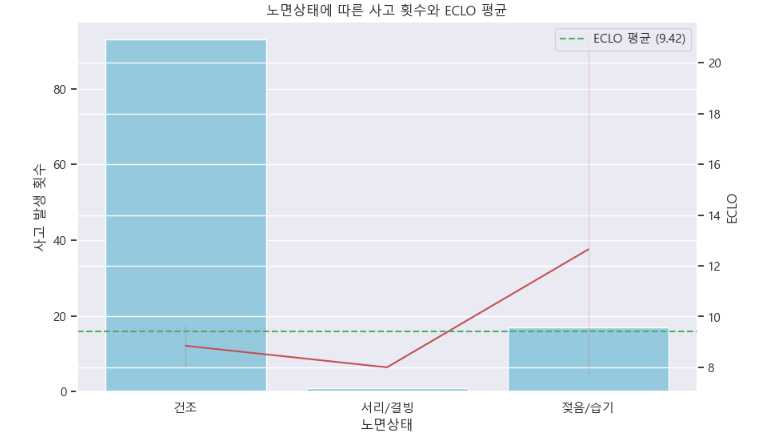
3 ) 전체 데이터
a ) 노면상태에 따른 사고 횟수와 ECLO 평균
# 노면상태 별 사고 횟수 시각화 (막대 그래프)
plt.figure(figsize=(10, 6))
ax1 = sns.countplot(x='노면상태', data=train_df, color='skyblue')
ax1.set_ylabel('사고 발생 횟수')
# 노면 상태 별 ECLO 평균 시각화 (선 그래프)
ax2 = ax1.twinx()
sns.lineplot(x='노면상태', y='ECLO', data=train_df, color='r', ax=ax2)
ax2.set_ylabel('ECLO')
# ECLO 평균 값의 수평선 추가
avg = train_df['ECLO'].mean()
ax2.axhline(avg, ls='--', label=f'ECLO 평균 ({round(avg, 2)})', color='g')
ax2.legend()
plt.title('노면상태에 따른 사고 횟수와 ECLO 평균')
plt.show()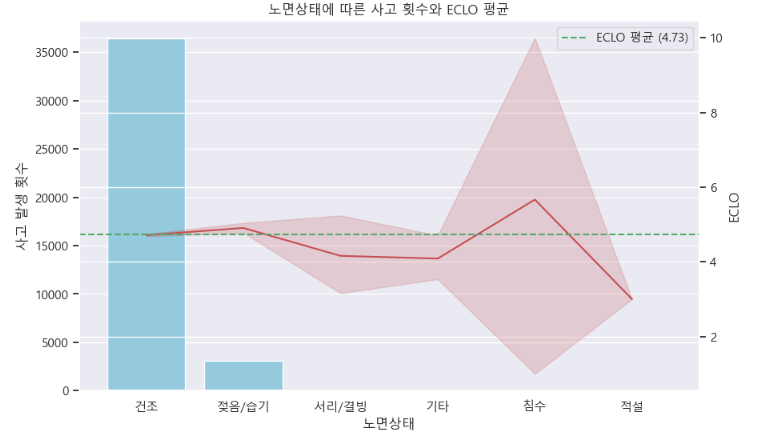
b ) 도로 형태 별 ECLO
# '도로형태'와 'ECLO'의 관계 시각화
plt.figure(figsize=(10, 6))
ax1 = sns.barplot(x='도로형태', y='ECLO', data=train_df, color='skyblue')
plt.xticks(rotation=45)
plt.title('도로형태별 ECLO')
avg = train_df['ECLO'].mean()
ax1.axhline(avg, ls='--', label=f'ECLO 평균 ({round(avg, 2)})', color='g')
ax1.legend()
plt.show()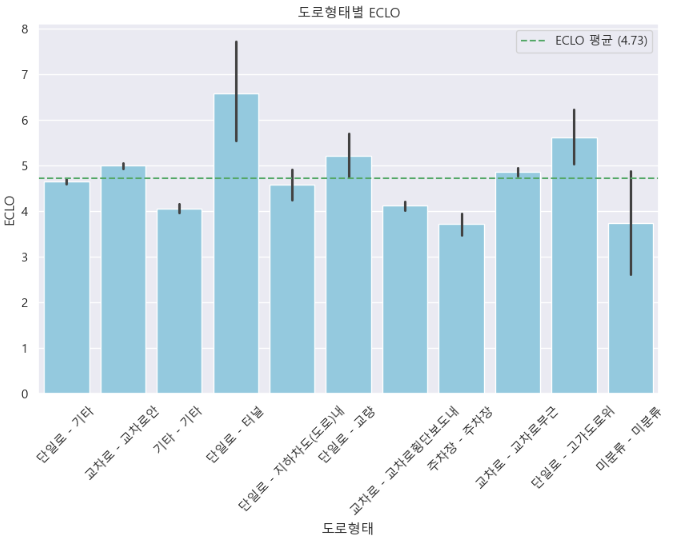
c ) 운전자 차종 별 ECLO 평균
import seaborn as sns
import matplotlib.pyplot as plt
victim_car_kind_df = train_df.groupby('피해운전자 차종')[['ECLO']].mean().reset_index()
attacker_car_kind_df = train_df.groupby('가해운전자 차종')[['ECLO']].mean().reset_index()
plt.figure(figsize=(10,6))
sns.lineplot(data = victim_car_kind_df, x = '피해운전자 차종', y = 'ECLO', label='피해운전자 차종')
sns.lineplot(data = attacker_car_kind_df, x = '가해운전자 차종', y = 'ECLO', label='가해운전자 차종')
plt.legend(title='운전자 차종')
plt.title('운전자 차종별 ECLO 평균')
plt.xlabel('운전자 차종')
plt.xticks(rotation=25)
plt.ylabel('ECLO 평균')
plt.show()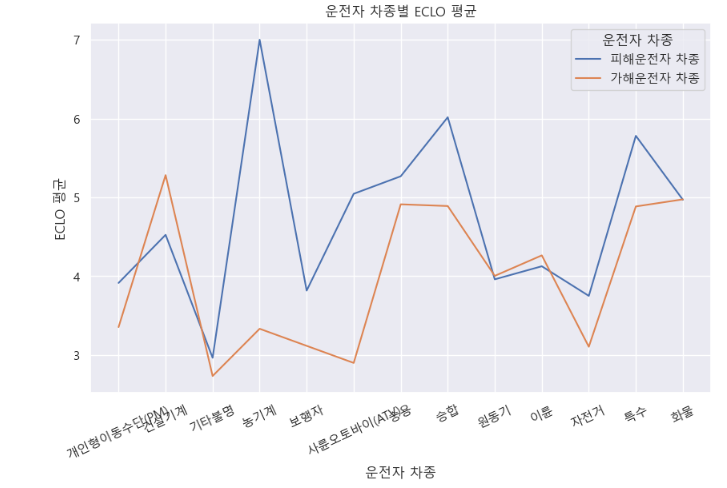
d ) 기상상태 별 ECLO 평균
plt.figure(figsize=(10, 6))
ax1 = sns.barplot(x='기상상태', y='ECLO', data=train_df, color='skyblue')
plt.xticks(rotation=45)
plt.title('기상상태별 ECLO 평균')
avg = train_df['ECLO'].mean()
ax1.axhline(avg, ls='--', label=f'ECLO 평균 ({round(avg, 2)})', color='g')
ax1.legend()
plt.show()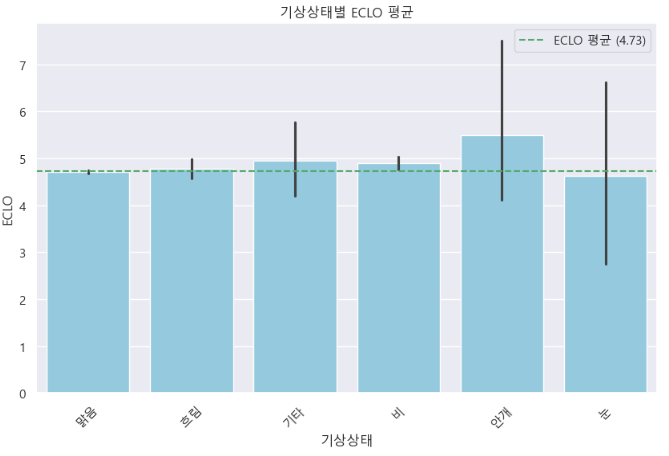
e ) 시군구별 사고건수
- 남구 대명동, 수성구 범어동, 달서구 상인동의 교통사고 건수가 많음
- 각각 전체의 4%, 2%, 2%
e ) 시군구별 ECLO 평균
- 북구 노곡동, 동구 덕곡동, 중구 대안동 순으로 ECLO 평균이 높음
f ) 요일과 ECLO의 관계
# ECLO upper bound 구하기
Q1 = train_df['ECLO'].quantile(0.25)
Q3 = train_df['ECLO'].quantile(0.75)
IQR = Q3-Q1
upper_bound = Q3 + 1.5 * IQR
plt.figure(figsize=(6,4))
sns.boxplot(x='ECLO', data=train_df,color='skyblue')
plt.axvline(x=upper_bound, color='r', linestyle='--', label='Upper Bound')
plt.text(upper_bound+12, 0.5, f'Upper Bound: {upper_bound:.2f}', color='r', ha='center', va='bottom')
plt.legend()
plt.title("box plot of ECLO")
plt.show()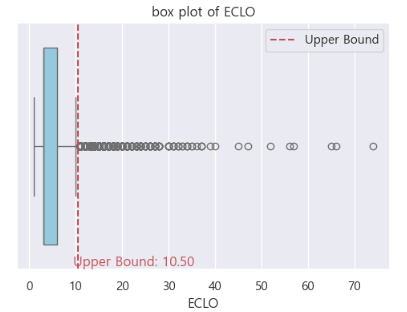
# ECLO 10.5를 기준으로 데이터 분리
high_ECLO_df = train_df[train_df['ECLO'] > 10.5]
no_high_ECLO_df = train_df[train_df['ECLO'] <= 10.5]
x_order = ['월요일', '화요일', '수요일', '목요일', '금요일', '토요일', '일요일']
fig, axes = plt.subplots(1, 2, figsize=(6,4))
sns.countplot(x='요일', data=high_ECLO_df,color='skyblue', order=x_order, ax=axes[0])
sns.countplot(x='요일', data=no_high_ECLO_df,color='skyblue', order=x_order, ax=axes[1])
axes[0].tick_params(axis='x', rotation=30)
axes[1].tick_params(axis='x', rotation=30)
axes[0].set_title("ECLO > 10.5")
axes[1].set_title("ECLO <= 10.5 ")
plt.tight_layout()
plt.show()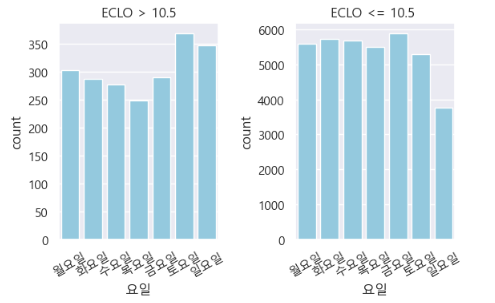
g ) 가해운전자 차종 별 사고 다발 시군구
train_df['주말_주중_구분'] = train_df['요일'].apply(lambda x: '주말' if x in ['토요일','일요일'] else '주중')
attacked_car_df = train_df.groupby(['가해운전자 차종','주말_주중_구분','시군구']).size().reset_index(name='count')
accidnet_cnt_per_attacked_car = attacked_car_df.loc[attacked_car_df.groupby(['가해운전자 차종','주말_주중_구분'])['count'].idxmax()]
accidnet_cnt_per_attacked_car.sort_values(['가해운전자 차종','count'], ascending = False).style.background_gradient()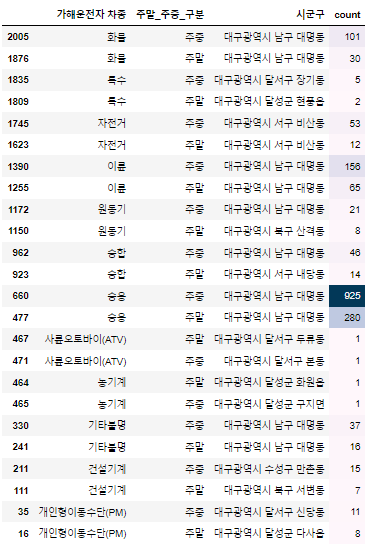
h ) 피해운전자 차종 별 사고 다발 시군구
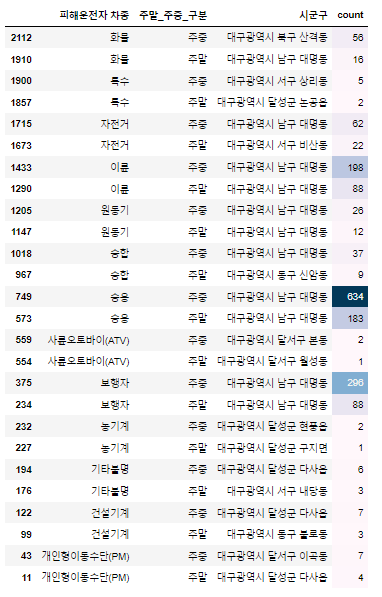
자전거 사고의 경우 비산동에서 많이 발생
- 비산동은 달서천과 인접해있고 자전거 대여소가 있어 주말에 많이 찾는 공간
i ) 사고 시간대 별 발생 횟수와 ECLO 평균
- 주중 출퇴근 시간대인 7-8, 17-19 사이에 사고 발생 횟수가 높음
- 새벽 시간대의 경우 사고 발생 횟수는 적은 편이지만 ECLO 평균값이 높음
plt.figure(figsize=(10, 6))
ax1 = sns.countplot(x='사고시간', hue ='주말_주중_구분', data = train_df, color='skyblue')
ax1.set_ylabel('사고 발생 횟수')
# 노면 상태 별 ECLO 평균 시각화 (선 그래프)
ax2 = ax1.twinx()
ax1 = sns.lineplot(x='사고시간', y='ECLO', data=train_df, color='r', ax=ax2)
ax2.set_ylabel('ECLO')
plt.title('사고 시간대별 사고 횟수와 ECLO 평균')
plt.show()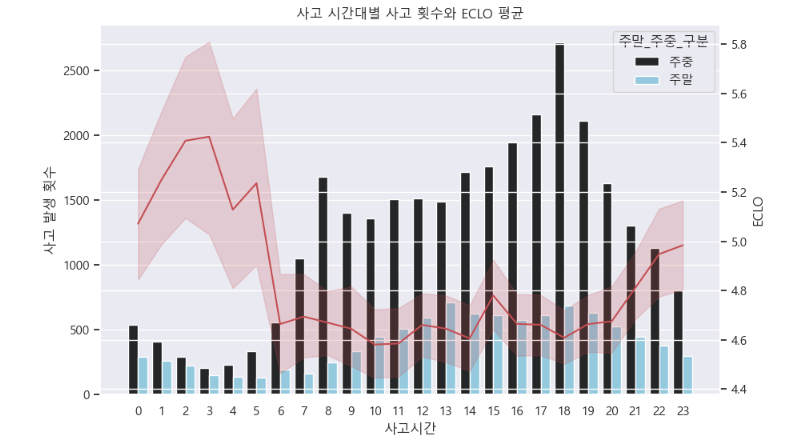
j ) 나이대 별 상해정도
나이대 가공 코드 생략
import matplotlib.pyplot as plt
# '피해운전자 상해정도'와 '가해운전자 상해정도'가 '사망'인 데이터를 세대별로 그룹화
fatal_by_generation = train_df[train_df['피해운전자 상해정도'] == '사망'].groupby('피해운전자 세대').count()
fatal_by_generation['가해운전자 상해정도'] = train_df[train_df['가해운전자 상해정도'] == '사망'].groupby('가해운전자 세대').count()['가해운전자 상해정도']
# pie plot 그리기
labels = fatal_by_generation.index
sizes1 = fatal_by_generation['피해운전자 상해정도']
sizes2 = fatal_by_generation['가해운전자 상해정도']
colors = sns.color_palette('hls',len(labels))
fig, axs = plt.subplots(1, 2, figsize=(10, 5)) # 1행 2열의 subplot 생성
# 피해운전자 상해정도 pie plot
axs[0].pie(sizes1, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
axs[0].set_title('피해운전자 세대별 사망 비율')
# 가해운전자 상해정도 pie plot
axs[1].pie(sizes2, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
axs[1].set_title('가해운전자 세대별 사망 비율')
plt.axis('equal')
plt.show()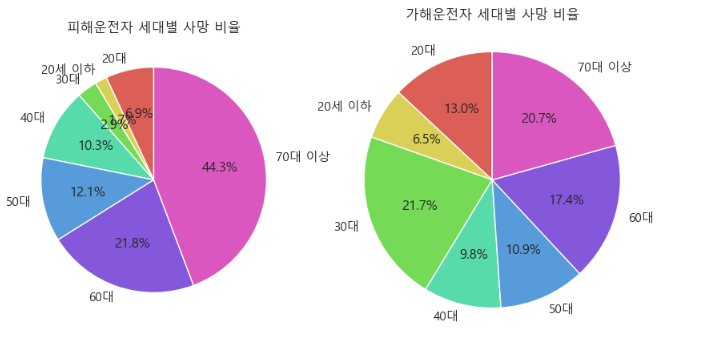
k) 참고 - QGIS 시각화
- 행정동 정보와 2020년 사망교통사고 정보 그리고 23년 로드링크 정보로 시각화
주의로드링크 정보는 갱신되는 정보로, 되도록이면 조회일시를 맞추어서 보는게 좋음- 고속도로급 (ROAD_RANK 101 또는 102) 도로를 굵게 칠해두었음
- 사망 교통사고가 일반도 보다는 주요 도로에 주로 위치함을 볼 수 있음