Sequence Model : Recurrent Neural Networks
Machine Learning
해당 게시물은 2023년 구글 머신러닝 부트캠프에 참여하게 되면서, 제공된 코세라 Sequence model 강의를 기반으로 배운 내용을 요약하고 '밑바닥부터 시작하는 딥러닝' 책과 병행하며 추가로 필요한 부분을 찾아 넣어 개인 공부를 위해 작성하였습니다.
[coursera] Sequence Model
1주차 Recurrent Neural Networks
Sequence data
- sequence data(시퀀스 데이터)
- sequence data란 sequence(순서)가 있는 데이터
- 시간에 따라 순서대로 발생하는 데이터의 형태인데, 이러한 데이터는 여러 개의 요소/사건이 연속성을 가지는게 특징임
Examples of sequence data
- speech recognition (음성 인식)
- music generaton (음악 생성)
- sentiment classification (감성 분류)
- DNA sequence analysis (DNA 분석)
- machine translation (기계 번역)
- video activity recognition (비디오 인식)
- Name Entity Recognition (개체명 인식)
sequence data modeling
-
일반적인 supervised learning algorithm은 input data가 'iid(Independent and Identically Distribution)', 독립 동일 분포라고 가정하기 때문에 n개의 데이터 샘플로 학습 시 데이터를 사용하는 순서는 상관이 없다.
-
그러나, sequence data들은 '연속성' 그러니까 순서를 가지고 있기 때문에 독립적이지 않고, 이전 요소와 다음 요소 간의 상호작용 및 패턴을 포착하거나 예측하기 위해 해당 데이터를 사용하려면 'standard network' 즉, 일반적인 신경망 모델이 아닌 다른 구조를 가진 모델이 필요하다.
why not a standard network?
(1) inputs, outputs can be different lengths in different examples.
입력과 출력은 서로 다른 길이를 가질 수 있고, 서로 다른 예시가 될 수 있다.
(2) Doen't share features learned across different positions of text
일반적인 나이브 신경망 아키텍처는 텍스트의 서로 다른 위치에서 학습한 기능을 공유하지 않는다.
Motivating example
( 코세라 강의에 나오는 예시 인용)
x : Harry potter and Hermione Granger invented a new spell
이라는 문장이 있을 때, x 문장의 띄어쓰기로 구분되어 있는 word를 일시적인 시퀀스로 나타낼 수 있다.
x : Harry potter and Hermione Granger ... new spell
x<1> x<2> x<3> x<4> x<5> ... x<8> x<9>
로 총 x의 시퀀스는 9개로 이를 input으로 한다면 입력시퀀스의 길이는 9이다.
이어서 위의 입력 문장 x의 각각의 시퀀스가 인명(사람의 이름)에 해당하면 1, 아니면 0을 반환하는 target y를 출력으로 나타낸다면
x : Harry potter and Hermione Granger invented a new spell
y: 1 1 0 1 1 0 0 0 0
이고, 각 입력 시퀀스 길이에 따른 출력 시퀀스의 길이도 9 이다.
Notation
- 위의 문장에서 x<1>, x<2> 의
x<t>는 일시적인 시퀀스 라는 것을 나타내고, 훈련 예제 i에 대한 입력 시퀀스의 길이를Tx(i), 훈련 예제에 대한 출력 시퀀스의 길이를Ty(i)로 표기할 수 있다. x(i)<t>는 훈련 예제 i에 대한 시퀀스 t를 나타내는 것으로, 앞에 나오는 중괄호 () 는 훈련예시를, 홑화살괄호 <> 는 시퀀스를 나타낸다.
위의 (i) 와 <t>는 모두 윗첨자이다!
RNN (Recurrente Neural Network)
- 'Recurrent'로 순환하는 으로 직역하여 RNN은 순환 신경망이라고 한다.
- 어느 한 지점에서 시작해, 다시 원래 장소로 돌아오는 것을 반복하는 것이 '순환' 인데 순환하기 위해서는 '닫힌 경로'가 필요하다.
'닫힌 경로' 혹은 '순환하는 경로'가 있으면 데이터가 같은 장소를 순환하면서 정보가 갱신된다.
짧게 정의하면 RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델임
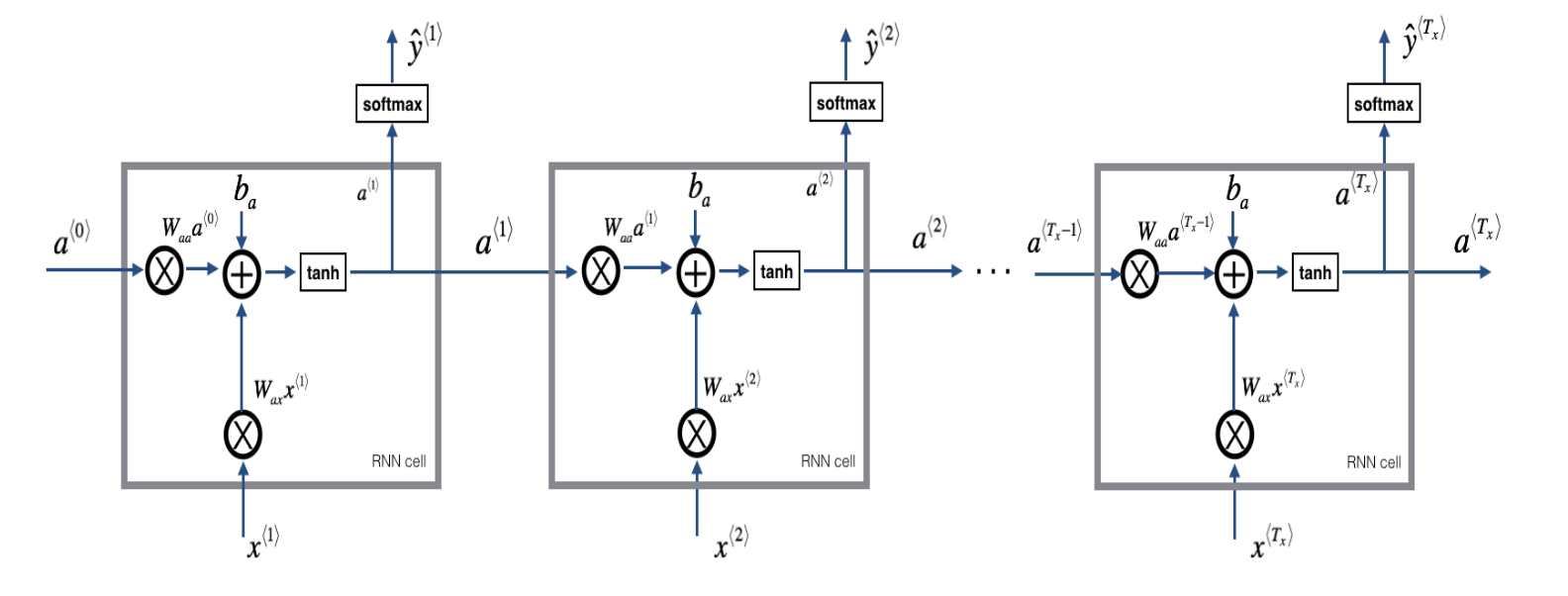
RNN Structure
사실 코세라 강의 듣기 전에 책에서 그려진 RNN 그림을 보고 이해가 잘 안됐는데, 코세라 강의를 들으면서 입력 시퀀스에 따라 출력 시퀀스가 나오고 이를 왼쪽에서 오른쪽으로 펼쳐서 그리니까 이해가 좀 쉬웠음
코세라에서는 hidden state를 a로 notation 하였고, 위키독스나 다른 문헌에서는 주로 h로 표기한다.
나는 코세라에서 강의를 들으면서 이해했기 때문에 notation을 a로 하는게 더 편해졌다.
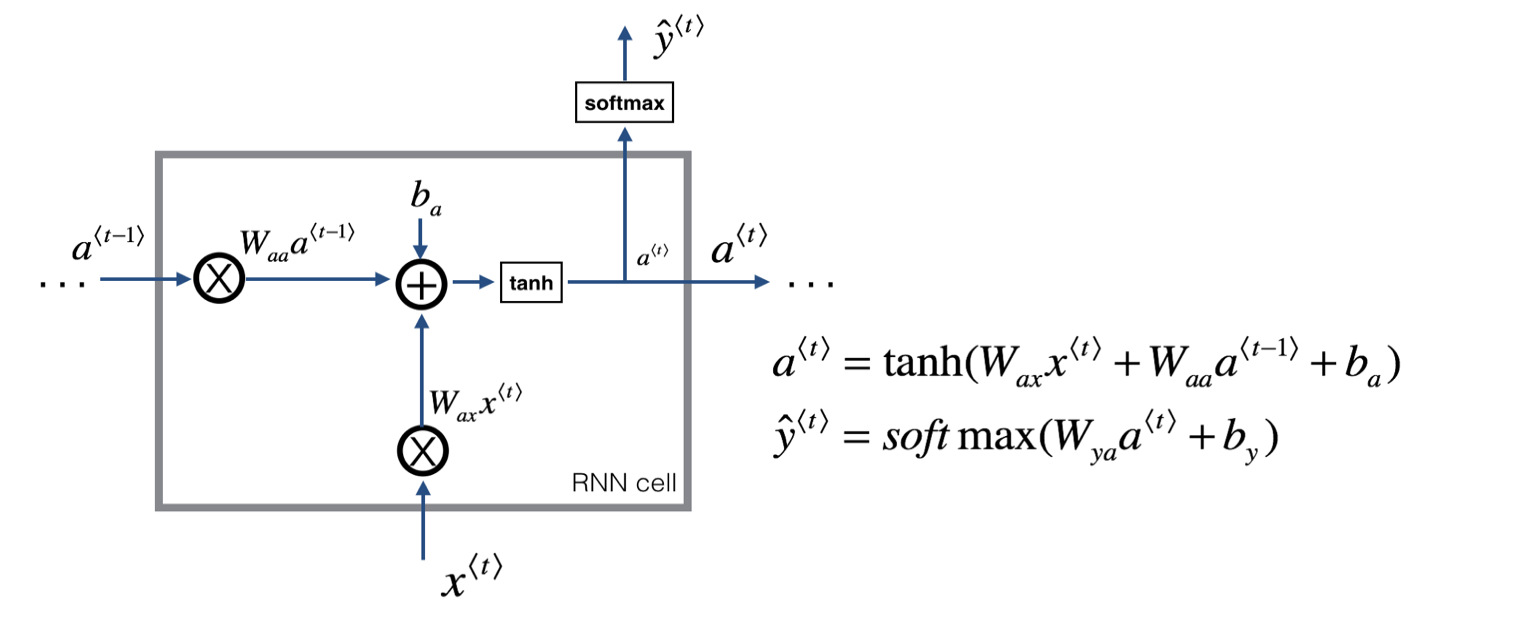
- 현재 시점 t에서의 은닉 상태값을
a<t>라고 정의할 때, 은닉층의 메모리 셀은a<t>를 계산하기 위해 총 두 개의 가중치를 가진다.- 하나는 입력층을 위한 가중치
Wax이고, 하나는 이전 시점 t-1의 은닉 상태값인a<t-1>을 위한 가중치Waa이다.
이를 식으로 표현하면,
은닉층 :
a<t> = tanh(Waa*a<t-1> + Wax*x<t> + ba)
출력층 :y^<t> = f(Wya*a<t> + by)
(f는 비선형 활성화 함수 중 하나로, 이진 분류면 sigmoid, 다중 분류면 softmax를 사용)
으로 나타낼 수 있다.
RNN simplified notation
코세라에서는 a<t>, y^<t>를 간단한 notation으로 바꿔서 나타냈는데,
a<t> = tanh(Wa[a<t-1>,x<t>] +ba)
y^<t> = f(Wya<t> + by)
로 간단하게 표현한다.
해당 notation으로 표현할 수 있는 방법은 아래의 hidden state 연산을 참고하면 된다.
RNN의 hidden state 연산
- RNN의 은닉층 연산은 벡터와 행렬의 연산이다.
- RNN의 입력
x<t>가 d차원을 가진 word vector이고, 은닉상태의 크기가 Dh 라고 가정한다면,
Waa = Dh x Dh
a<t-1> = Dh x 1
Wax = Dh x d
x<t> = d x 1
b = Dh x 1
이게 되고 위의 식에서 각각의 가중치 Waa, Wax, Wya는 하나의 층에서는 모든 시점에서 값을 동일하게 공유한다. (하지만 은닉층이 2개 이상일 경우에는 각 은닉층에서의 가중치는 서로 다름)
RNN의 약점
- 앞서 나온 정보만을 사용해 예측하므로 y^<3> 예측시 x<5>, x<6>, x<7> 의 정보를 사용하지 않는다.
- 후술하겠지만 기본 RNN의 문제 중 하나는 기울기 값이 소멸되는 Gradient Vanishing (기울기 소멸)이 발생한다는 것이다.
- 또한 장거리 의존성을 잡는데 그다지 뛰어나지 않은 경향이 있다.
Gradient Vanishing/Exploding with RNN
-
기울기 소멸과 기울기 폭주는 RNN 학습에서 발생할 수 있는 문제다.
-
먼저 기울기 폭주(Grdieng Exploding)은 gradient가 기하급수적으로 커지면서 parameter가 매우 커져, 신경망의 매개변수가 엉망이 되어 학습에 치명적이다.
-
Exploding gradients make the training process more difficult, because the updates may be so large that they "overshoot" the optimal values during back propagation.
(폭주하는 기울기는 업데이트하기 너무 커서 역전파 중에 최적 값을 "오버슛"할 수 있기 때문에 훈련 프로세스를 더 어렵게 만듦) -
그러나 기울기 폭주는 숫자 오버플로우('NaN')로 발견하기 쉽고, Gradient clipping 으로 해결 할 수 있다.
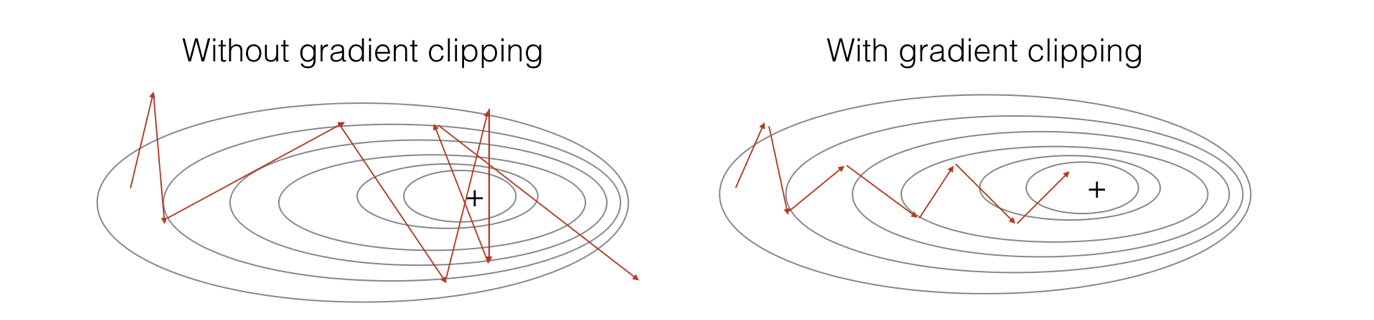
그림 출처 : coursera Sequence model programming task
Gradient clipping(그래디언트 클리핑)
- RNN에서 gradient exploding을 방지하여 학습의 안정화를 도모
- Gradient가 일정 threshold를 넘어가면 clipping을 해줌
- clipping이 없으면 gradient가 너무 뛰어서 global minimum에 도달하지 못하고 엉뚱한 방향으로 향하게 되지만, clipping을 해줌으로써 gradient vector가 방향은 유지하고 적은 값만큼 이동해 도달하고자 하는 곳으로 안정적으로 내려가게 된다.
BackPropagation through time with RNN
- RNN의 BackPropagation(역전파)는 잠재변수의 연결그래프에 따라 순차적으로 계산 하는데, 가중치의 영향도를 Chain rule에 의해 구한다.
- 위와 같은 방법을 Backpropagation Through Time(BPTT)라고 하며 RNN의 역전파 방법이다.
- RNN의 역전파의 방법을 이용하면 Chain Rule에 의해 편미분 값이 계속 곱해져서 1보다 큰 수, 1보다 작은 수가 많이 곱해져 위에서 언급한 gradient 증폭, 손실이 발생한다.
그래서 위에서 언급한 RNN의 약점인 과거 시점에서의 데이터 영향도가 불안정해지는 현상이 발생하는 것이다.
RNN lossfunction
- sequence modeling에서의 Loss function은 negative log likelihood를 사용한다.
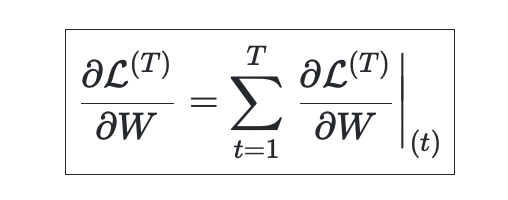
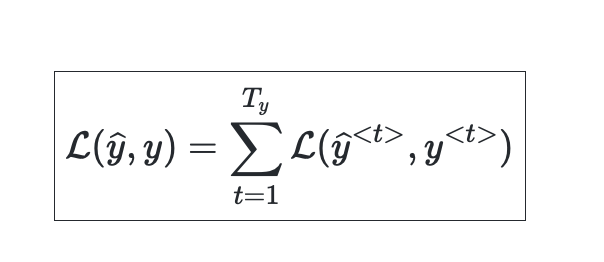
해당 내용은 다시 공부하면서 추가할 예정 !
Different types of RNNs
- RNN으로 시퀀스 데이터를 모델링할 때 항상 입력 시퀀스와 출력 시퀀스의 길이가 같지 않을 수 있고, 다른 형태일 수 도 있다.
- 예를 들어 speech recognition 같은 경우에는 주파수인 입력 시퀀스의 형태에서 'The cat~' 등의 텍스트 형태인 출력 시퀀스의 형태일 수 도 있다.
music generation의 경우에는 입력 시퀀스가 null 이지만 음악을 출력해 낼 수 있다. - 이러한 RNN은 여러 architecture가 존재한다.
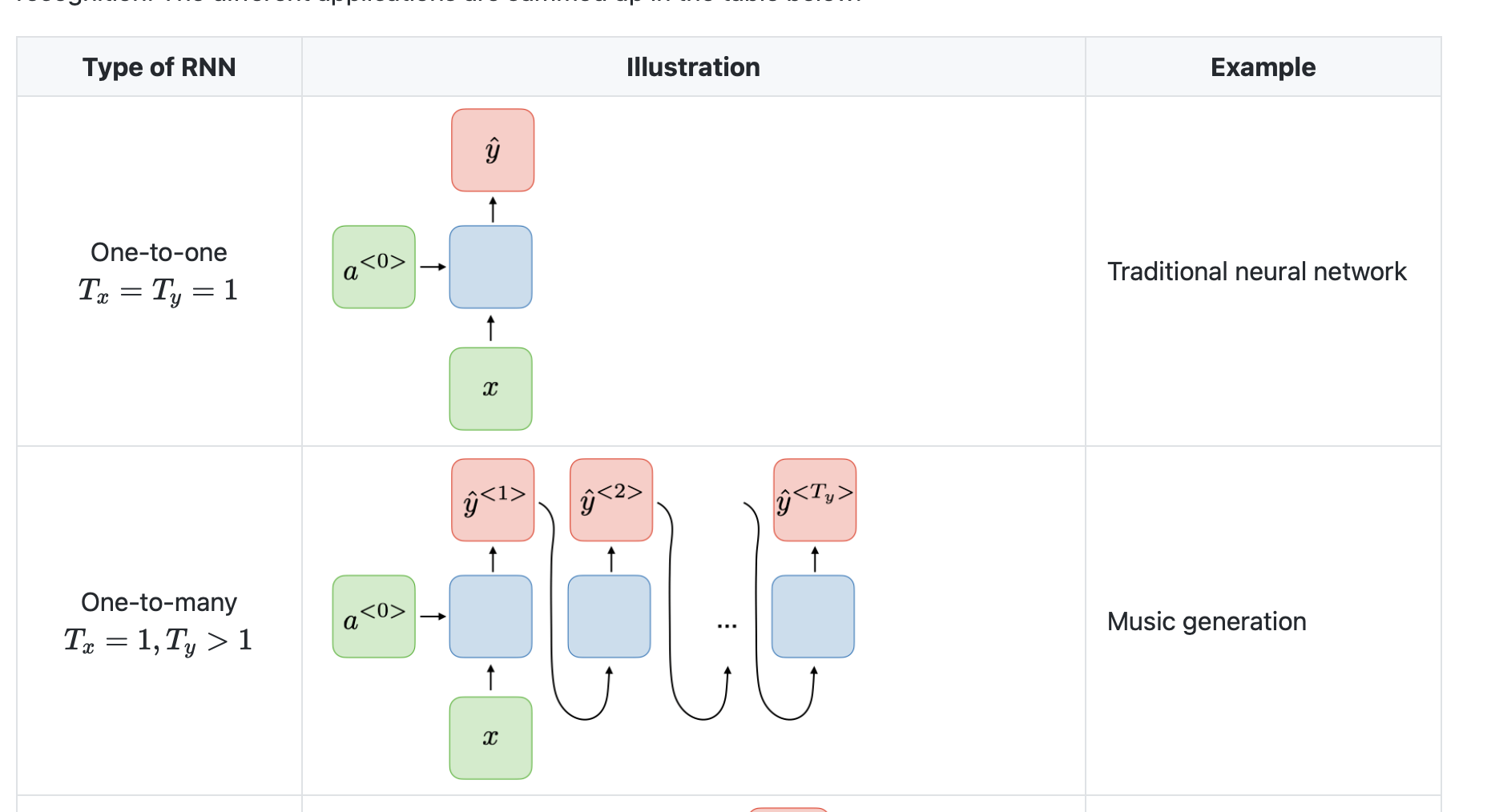
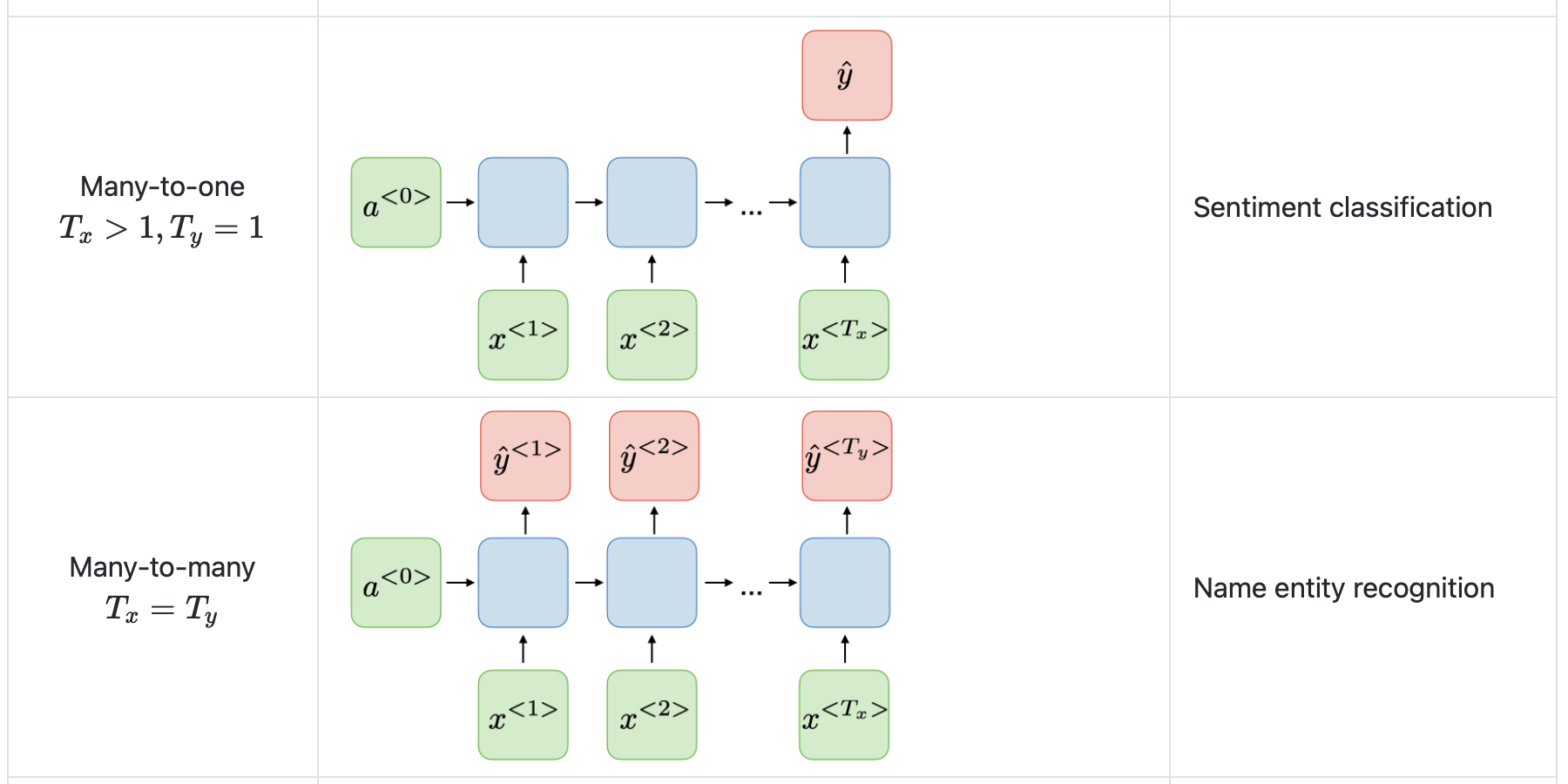
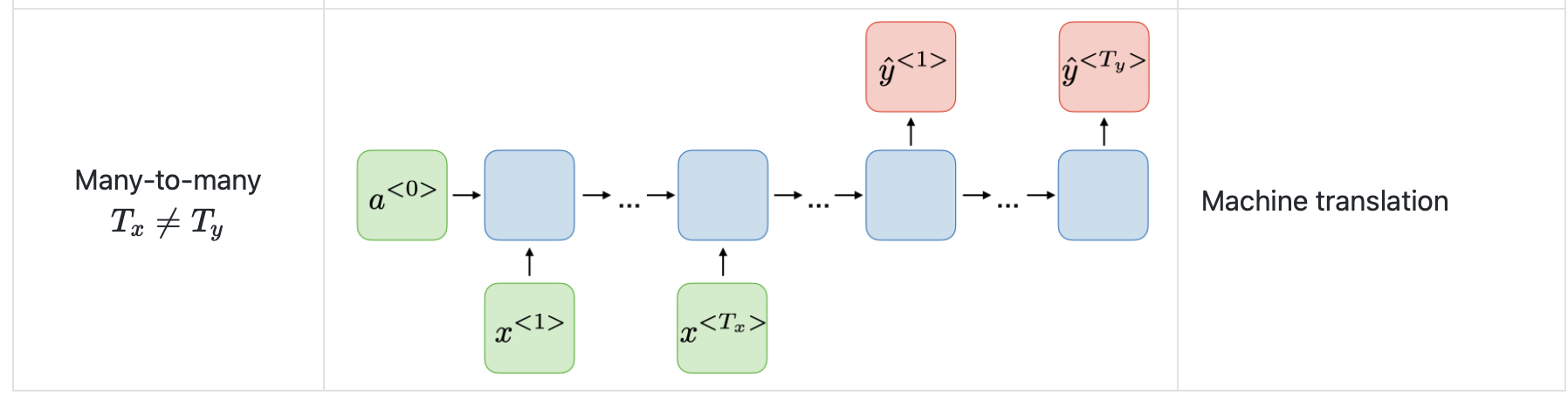
그림 출처 : 스텐포드 홈페이지
https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
Character-level language model
- charactoer-level(문자 언어 모델) 은 문장의 초기 부분이 문장의 뒷부분에 어떻게 영향을 주는지에 대해, 긴 길이의 문장의 종속성 측면에서 단어 수준 언어모델만큼 좋지 않으며, 훈련 시 계산 비용이 많이 든다.
GRU(Gate Recurrent unit)
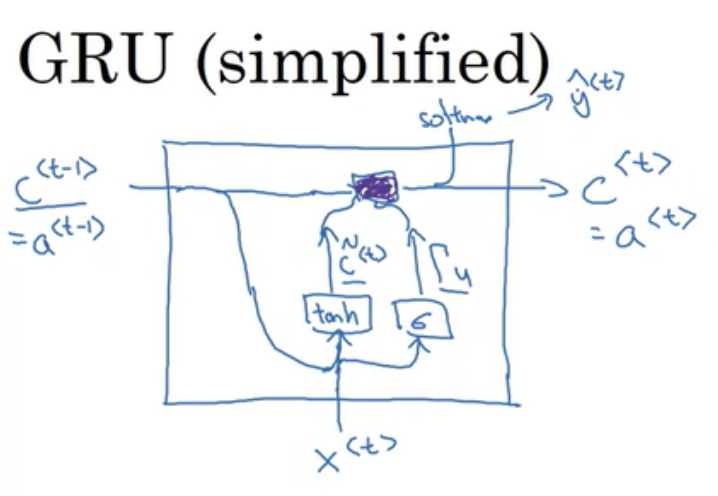
- 장거리 의존성과 기울기 소멸 문제를 해결하기 위해 RNN의 숨겨진 레이어를 수정한 것
- Reset Gate, Update gate가 추가된 모델
- 코세라 강의에서는 memory cell이라고, 시간 t에서 메모리 셀의 값이라고 하여 a 대신 c로 notation 하고 있고, 이전 정보들이 저장되는 공간이다.
- 핵심 아이디어는
c<t-1>를 통해 전달되고, 이전 정보와 현재 input인x<t>와 결합하여 다음 time step으로 전달된다.
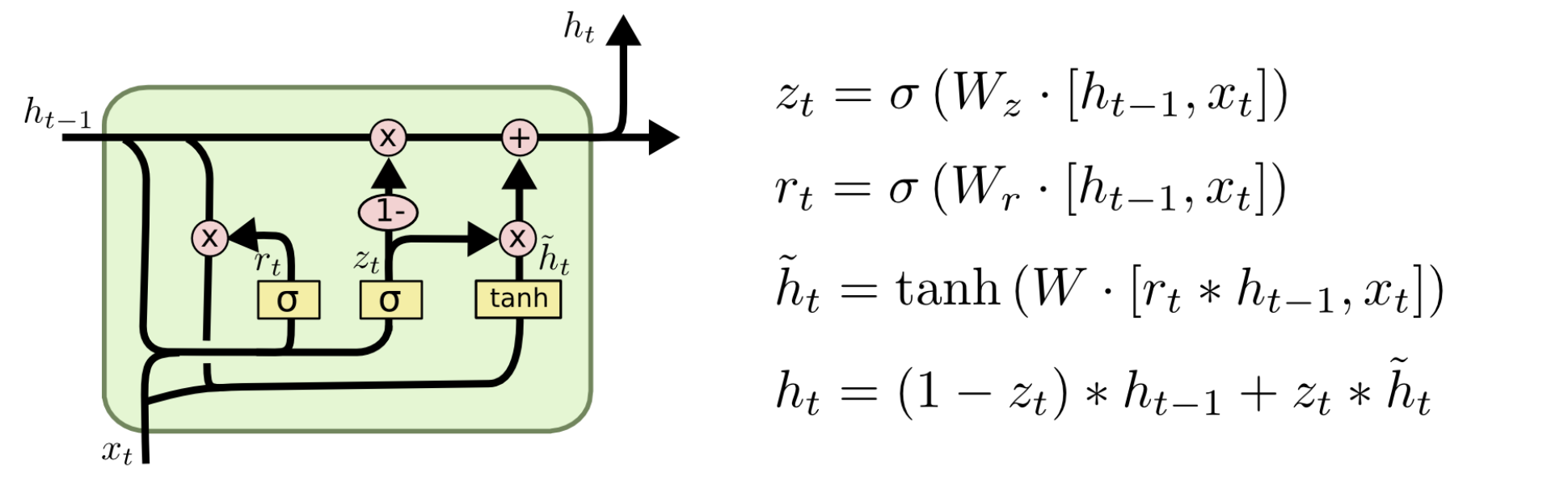
출처 : https://wagenaartje.github.io/neataptic/docs/builtins/gru/
LSTM
- GRU보다 파워풀하고 일반적인 버전이라고 언급하고 있다.
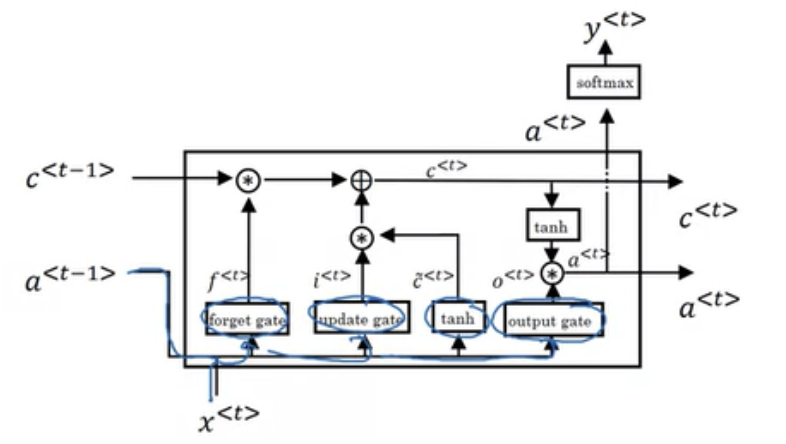
- 메모리 셀에 추가로 forget gate, update gate, output gate 가 추가되어 있다.
- 이전의 time step에서 전달받는 input이 c<t−1>, a<t−1>이고
각 Forget gate, Update gate, Output gate을 통해서 각각의 연산을 수행하고, tanh를 통해서c~<t>연산을 수행한다.
GRU와 같이c~<t>는 현재 time step에서 다음 time step으로 업데이트할 정보들의 후보군이다. - LSTM의 핵심 아이디어는 현재 time step의 정보를 바탕으로 이전 time step의 정보를 얼마나 잊을지 정해주고(Forget gate), 그 결과에 현재 time step의 정보의 일부(Update gate와
c~<t>의 연산)를 더해서 다음 time step으로 정보를 전달하는 것에 있다.
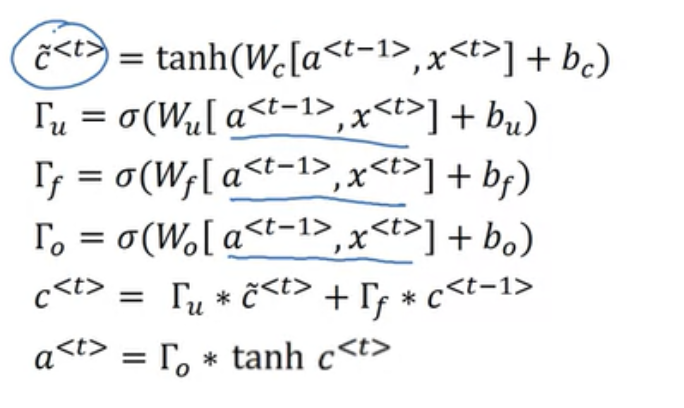
각 모델들의 구조를 도식화하자면
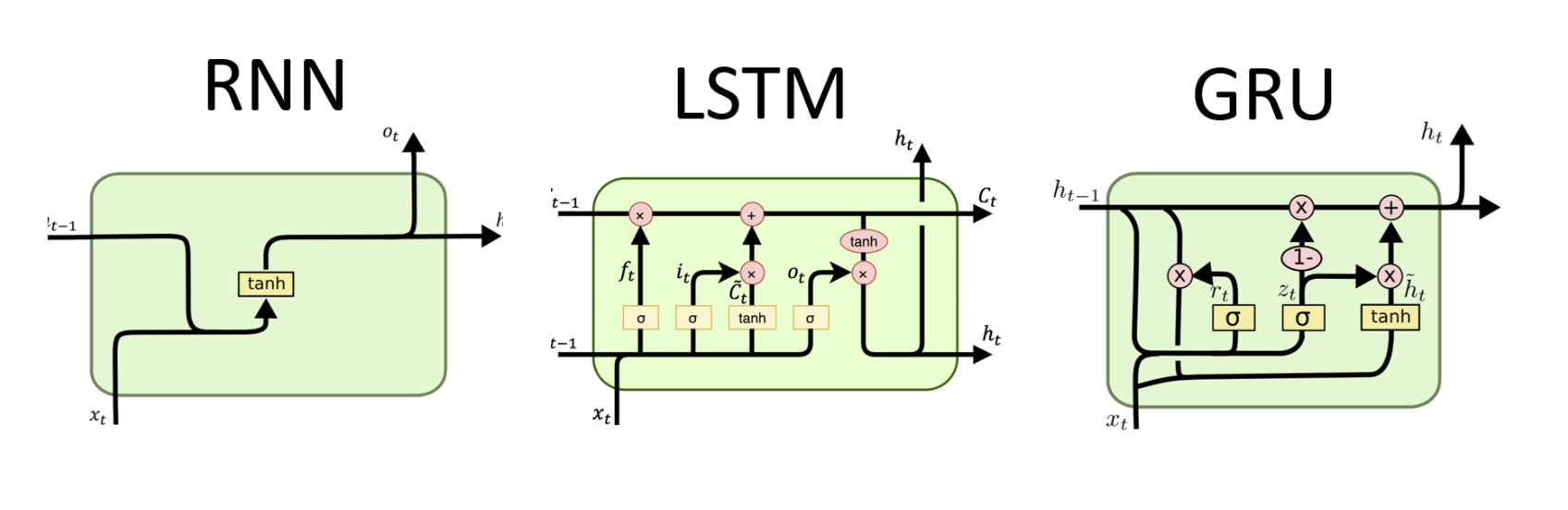
출처 : http://dprogrammer.org/rnn-lstm-gru
Sequence Model 강의 회고
1주차 Recurrent Neural Networks를 듣고 나면,
sequence 데이터와 더불어 이러한 데이터를 모델링할 수 있는
RNN, GRU, LSTM, BRNN 등의 네트워크들을 알게 된다.
추가로 각각의 structure와 학습시 수반되는 gradient vanishing, exploding 등과 이를 해결할 수 있는 clipping에 대해서 알게 된다.
현업에서 별 다른 배경지식 없이 nlp project를 하면서 바로 transformer 모델을 사용하면서, 자연어처리 관련 개요들을 개략적으로만 보고 넘어가서 그 안에 structure 들에 대해서 완전히 이해하지는 않고 감만 잡고 있는 상태였다.
해당 강의를 들으면서 순차적으로 RNN 계열들을 훑으니 건성으로 이해하고 있었던 부분들을 집고 넘어갈 수 있었다.
이해했다고 생각했지만 quiz 를 풀고 70점이 뜨고 넘어가지 못할 때의 그 허탈함이란.. 다시 처음부터 강의를 들으면서 기록했던 강의록들을 다시 써보면서 퀴즈를 다시 풀고 100점으로 완료
그렇지만 rnn, lstm structure 짜는 프로그래밍 과제는 진짜.. 너무 어려운거 아닌가 어질어질함
찾아가면서 풀긴했는데 프로그래밍 과제는 한 3번 정도 더 봐야 할 것 같다.
<1주차 퀴즈>
Sequence model 퀴즈 패턴을 보면,
(1) 시퀀스 데이터를 나타내는 노테이션 문제
(2) RNN의 여러 유형들의 architecture를 보고 입력 시퀀스 길이, 출력 시퀀스 길이에 대한 이해
(3) RNN architecture 들 (many-to-many, many-to-one)에 해당하는 예제
(4) RNN 모델에서 일시적인 시퀀스 t time step에서 일어나는 과정들에 대한 이해 (t time step이 RNN이 추정하는 y에 대한 이해 등)
(5) gradient exploding
(6) RNN, LSTM의 각 gate에서의 차원의 크기
(7) GRU와 LSTM 의 각 게이트에서 일어나는 과정에 대한 이해
(8) 한 예제에서 BRNN을 사용할 것인가에 대한 이해도
에서 문제가 나온다.
1차에서는 70/100, 2차에서는 90/100, 3차에서 100/100 으로 통과했는데 내가 계속 걸렸던 부분은 LSTM에서의 gate 연산들이다.
이 부분은 다시 봐야 할 것 같음~!
자 그럼 이제 2주차 Natural Language Processing & Word Embedding으로 넘어가 볼까나
