Instruction
매우 복잡한 기능을 학습하는 경우 RNN의 여러 계층을 함께 쌓아 딥러닝 모델을 구현하는 것이 효과적일 수 있다.
Deep RNN example
표준 신경망에는 입력값 x가 있고 어떤 은닉층에 쌓여 있고 첫 번째 은닉층에 활성화 a_1가 있고 a_2로 다른 층으로 a_3이 쌓이면서 y^(y hat)이 시간에 따라 펼쳐진다.
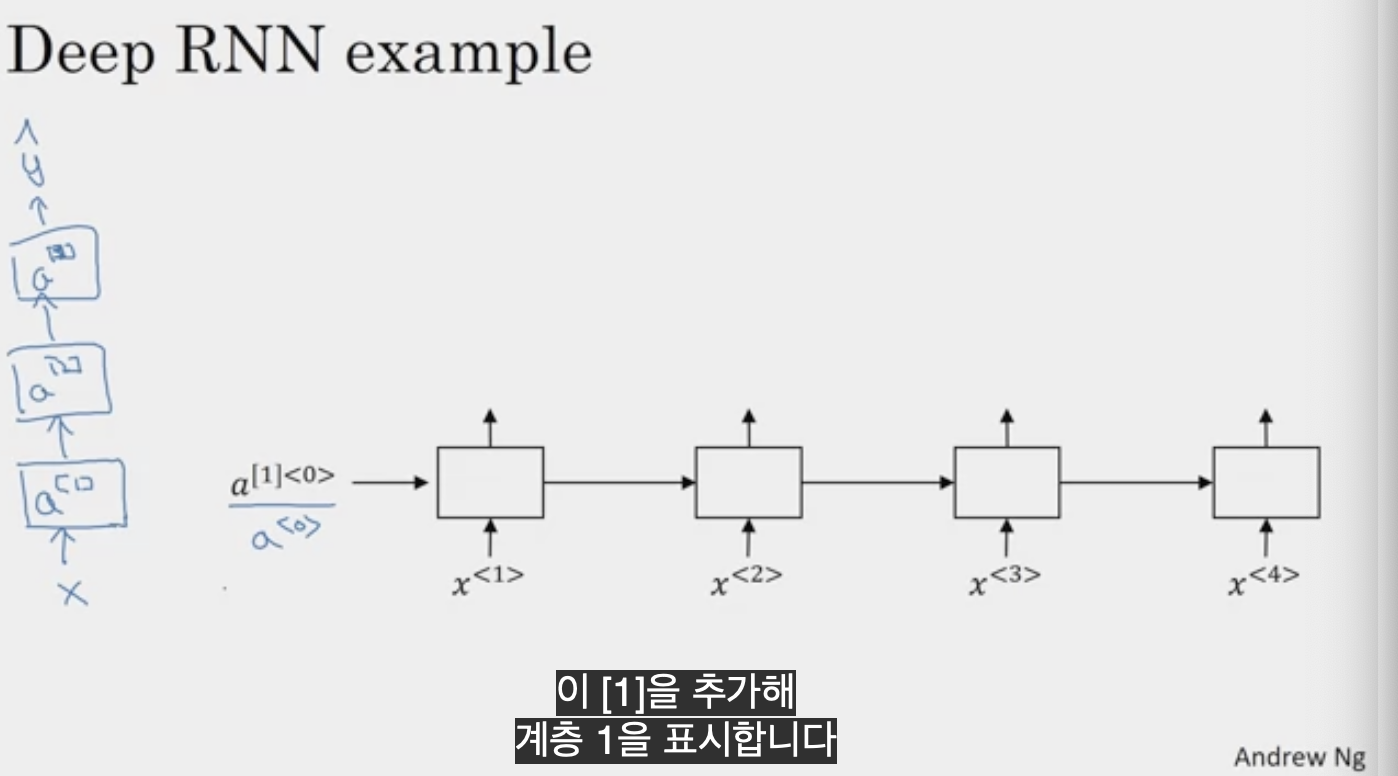
여기서의 notation은 a[l]<t>로 layer l과 연결된 활성화이며 시간 t와 연결된 것을 표시하기 위해 사용한다.
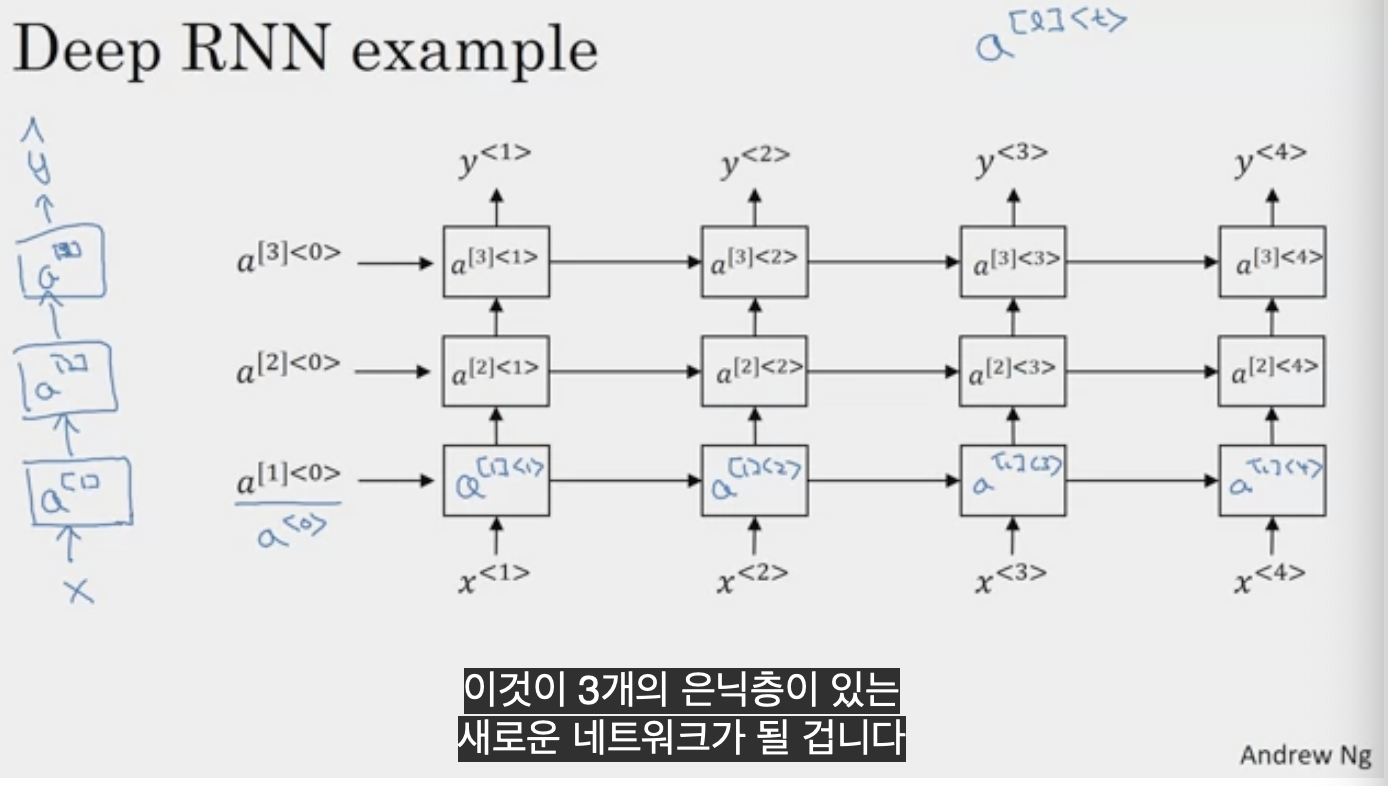
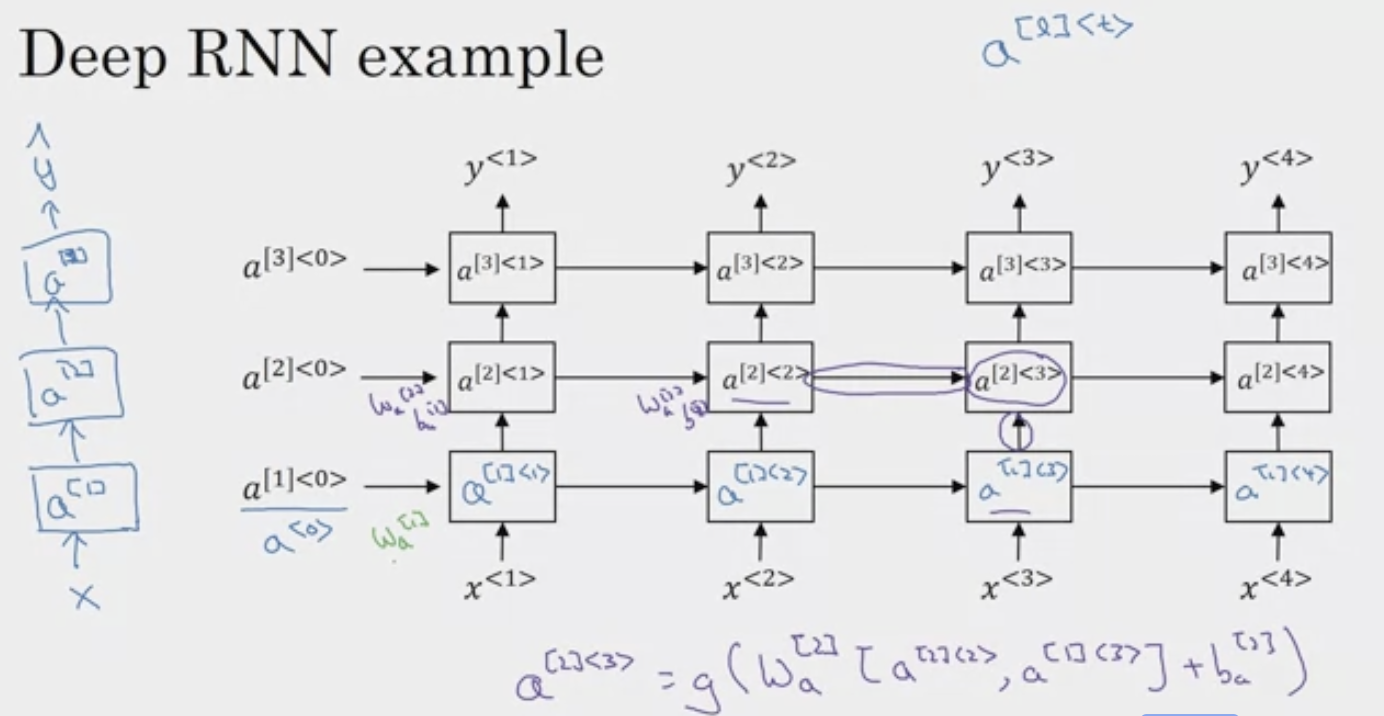
여기서 a[2]<3> 은 왼쪽의 a[2]<2>와 아래의 a[1]<3>을 더해준다.
서로의 위에 쌓인 순환층이 있고, 여기서 출력을 가지고 수평으로 연결되지 않은 심층 다발을 가질 수 있고 심층 네트워크가 최종적으로 y^1, y^2를 예측한다.
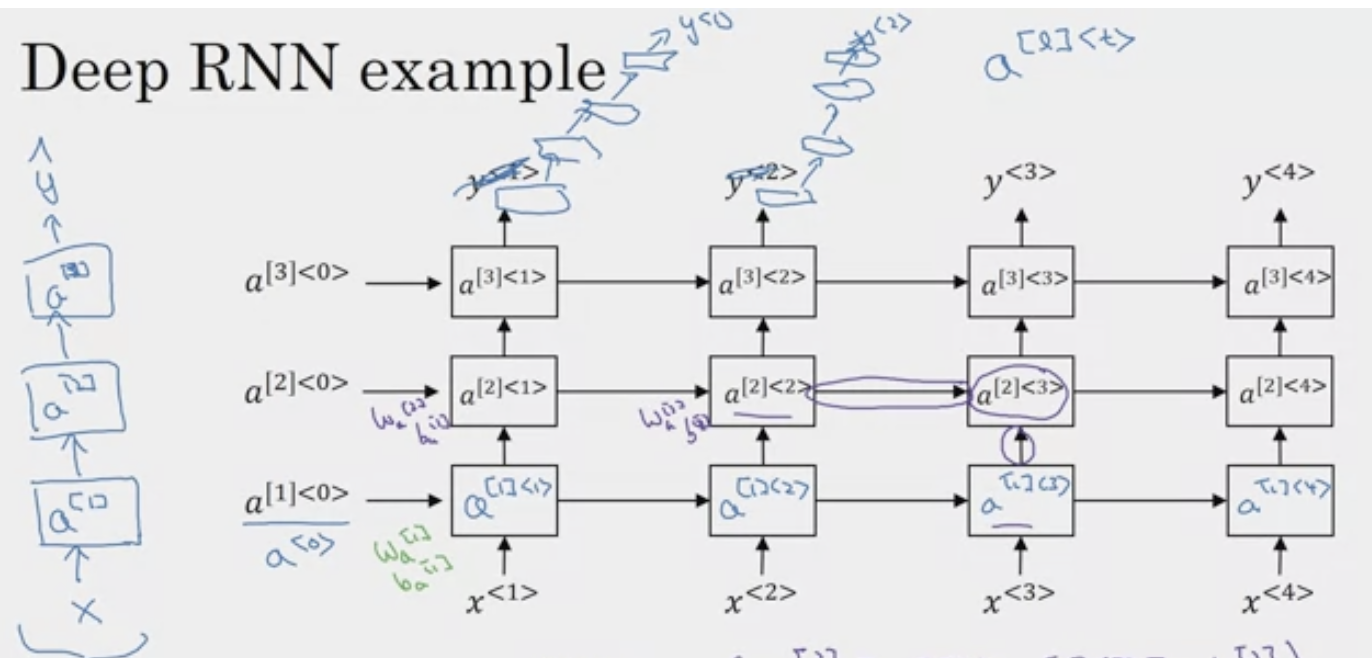
y^3, y^4도 있는데 심층 네트워크는 있지만 수평적인 연결은 없다.
이것이 우리가 더 많이 보는 아키텍처 종류이다.
해당 블록은 Bidirectional RNN, GRU, LSTM이 될 수 있다.
심층 RNN은 계산하는데 cost가 많이 든다.

꿈꾸는 것도 개발처럼 깊게