
썸네일 이미지 출처: https://www.pinterest.co.kr/pin/299841287687472213/
05 고찰 & 결론
(1) Heatmap Again
1) copy()
이전 포스트에서 범주를 재구성한 새로운 컬럼들이 있는데, 그 컬럼들의 원래 컬럼을 제거할 것이다. 하지만, 필자는 Heatmap으로 상관계수 비교를 하기 위해 (이전 포스트 마지막에서) 다음과 같은 작업을 하였다.
# 1) df_n을 copy()하여 df_n1에
df_n1 = df_n.copy()
# 2) df_n에서는 'mort_acc', 'pub_rec_bankruptcies', 'new_sg' 세 컬럼 삭제
df_n = df_n.drop(['mort_acc', 'pub_rec_bankruptcies', 'new_sg'], axis=1)
# 3) df_n1 에서는 'mort_acc', 'pub_rec_bankruptcies', 'new_sg' 세 컬럼이 삭제되지 않고 그대로 살아있다. df_n을 복사하여 df_n1에 저장하고 그 뒤에 df_n에서 'mort_acc', 'pub_rec_bankruptcies', 'new_sg' 컬럼들을 삭제하였다. 결과적으로 df_n1 에서는 'mort_acc', 'pub_rec_bankruptcies', 'new_sg' 세 컬럼이 삭제되지 않고 그대로 있고, df_n은 세 컬럼이 제거 되었다.
2) Helpful HEATMAP
먼저 df_n DataFrame을 다음 코드로 Heatmap을 그려보았다. 출력결과도 같이 첨부하겠다.
sns.set(style = 'whitegrid', font_scale = 1)
plt.figure(figsize = (12, 12))
plt.title("Helpful Heatmap", fontsize = 24)
sns.heatmap(df_n.corr(), linewidths = 0.25, vmax= 0.7, square = True,
cmap = 'Blues', linecolor='w',
annot=True, annot_kws = {'size':10},
cbar_kws={'shrink': .7})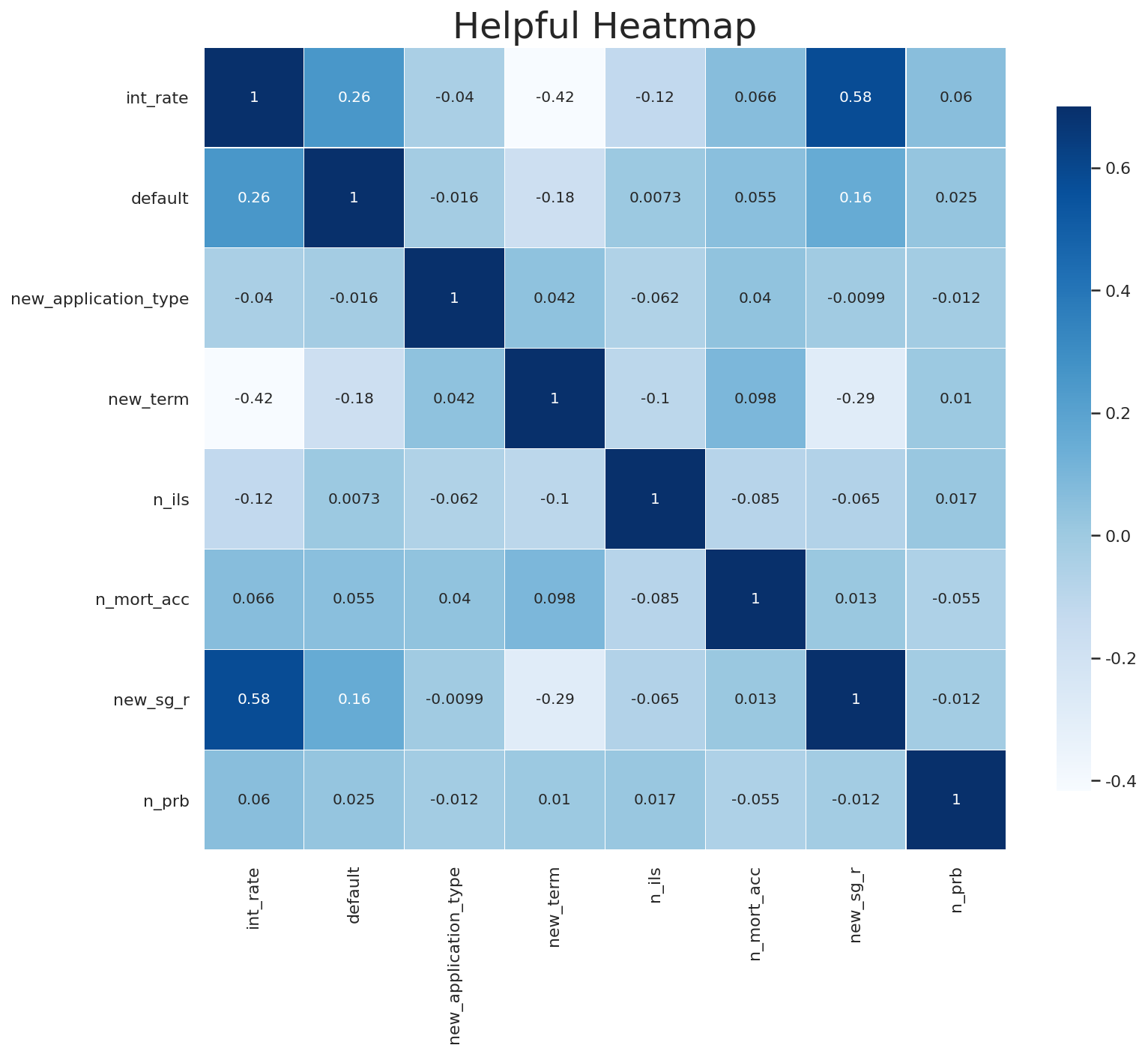
어라?
결과를 보면, 조금 의아한 부분들이 발견되었다. 먼저 각 컬럼별로 'default'와의 상관계수를 살펴보면, 상관계수가 0.1보다 크거나 -0.1보다 작은 값을 갖는 컬럼이 3개 밖에 없다. 예상을 했던 대로라면, helpful 에 있는 모든 컬럼이 default 와의 상관계수가 0.1을 넘어 최소 0.4 ~ 0.8 정도를 생각했었는데... 예상과 달랐다.
default와의 상관계수
- new_sg_r (sub_grdae) : 0.16
- int_rate : 0.26
- new_term (term) : -0.18
3) 다른 Helpful HEATMAP
이번에는 df_n1 DataFrame을 Heatmap을 그려보았다. 역시 출력결과도 같이 첨부하겠다.
# 삭제한 컬럼과 비교해볼까?
sns.set(style = 'whitegrid', font_scale = 1)
plt.figure(figsize = (12, 12))
plt.title("Helpful Heatmap", fontsize = 24)
sns.heatmap(df_n1.corr(), linewidths = 0.25, vmax= 0.7, square = True,
cmap = 'Blues', linecolor='w',
annot=True, annot_kws = {'size':10},
cbar_kws={'shrink': .7}).png)
상관계수 변화를 살펴보자
1) 상관계수가 증가
- new_sg (0.067) : sub_grade 컬럼의 value 값들을 숫자로 바꾼 컬럼
- new_sg_r(0.16) : sub_grade 컬럼의 35가지나 되는 고유 value 값들을 4가지로 범주를 재구성한 컬럼
2) 상관계수가 낮은 컬럼
n_prb, n_mort_acc, n_ils, new_application_type 이 네 가지 컬럼을 수치화하고 범주값을 줄였음에도 불구하고 상관계수가 적게 나왔다. 왜 이렇게 되었는 지 고민에 고민을 거듭해본 결과, '애초에 이 세 컬럼을 잘못 선택했던 것' 밖에 없었다. 그래서 이 세 컬럼들의 문제점을 어떤 과정에서 간과했었는지 살펴보기로 했다.
(2) 고찰
1) 뭐가 문제였을 까?
고민을 하던 끝에, default = 0 일 때와 default = 1 일 때 분포모양이 같으면, 제외를 했었어야 했는데, 스케일(크기) 만 보고 간과를 했던 것 같은 느낌이 들었다. 그래서 다시 groupby와 시각화를 진행해보았다. 예시로 한 컬럼 new_application_type (application_type의 value를 숫자로 바꾼 컬럼)을 들어보겠다.
2) new application type
groupby 뿐만 아니라, value_counts(normalize = True)를 이용해서 value 별 비율을 구해보았다.
df_n.new_application_type.groupby(df_n.default).value_counts(normalize=True)
default가 0일 때와 1일 때, new_application_type 컬럼의 value의 비율은 거의 동일하다고 봐도 무방할 정도로 비슷한 비율을 가진다. 이를 시각화해보자.
plt.figure(figsize= (7,7))
plt.title("percentage new_application_type by default", fontsize = 15)
df_n.new_application_type.groupby(df_n.default).value_counts(normalize=True).plot.bar().png)
이 컬럼 외에도, helpful 컬럼에 있으나 default와의 상관계수가 낮은 n prb, n mort acc, n ils 컬럼도 default 값에 따라 같은 분포를 보였다. '비율'을 고려하지 않은 것이 실수였다.
(3) Conclusion
이 데이터셋에서 'default' 타겟과 상관계수가 높은 컬럼은
int_rate, new_sg_r, new_term 이렇게 총 3개다.
이게 필자가 내린 결론이다. 이 해당 내용의 증명은 지금까지 필자가 작성한 내용이기도 하다. df_n2에 int_rate, new_sg_r, new_term 세 가지 컬럼만이 남도록 하였고, 이를 바탕으로 HEATMAP으로 다시 한 번 시각화를 진행해보았다.
df_n2 = df_n.drop(['n_prb', 'n_mort_acc', 'n_ils', 'new_application_type'], axis=1)sns.set(style = 'whitegrid', font_scale = 1)
plt.figure(figsize = (11, 11))
plt.title("new Helpful Heatmap", fontsize = 24)
sns.heatmap(df_n2.corr(), linewidths = 0.25, vmax= 0.7, square = True,
cmap = 'Blues', linecolor='w',
annot=True, annot_kws = {'size':10},
cbar_kws={'shrink': .7}).png)
- Useless Heatmap
Useless 리스트에 존재하는 컬럼들의 default 와의 상관계수를 확인해보겠다.
sns.set(style = 'whitegrid', font_scale = 1)
plt.figure(figsize = (12, 12))
plt.title("Useless Heatmap", fontsize = 24)
sns.heatmap(df_u.corr(), linewidths = 0.25, vmax= 0.7, square = True,
cmap = 'Greens', linecolor='w',
annot=True, annot_kws = {'size':10},
cbar_kws={'shrink': .7})
.png)
Useless 리스트에 있는 컬럼들과 default 간의 상관계수를 보면 모두 0.1 이하이다. (심지어 0.02, 0.066, ... 이런 식) 그러므로, 상관관계가 없다고 봐도 무방하다.
(4) What I needs
- 선형대수학, 확률, 통계 등 수학적 지식
: 이번에 초반에 EDA 노트를 참고하면서 Heatmap 을 시각화할 때, 처음에 correlation matrix, 상관계수 등 정확한 개념이 없었기에 왜 HEATMAP 으로 시각화를 왜 하면, 상관계수 등 의미를 몰랐다. 머신러닝에서는 더 더욱 수학의 비중이 훨씬 더 커진다. 그래서 수학적 지식에 대한 공부의 필요성을 많이 느끼게 된 계기가 되었다. - matplotlib, seaborn 등 시각화 기법
: 시각화 기법에 대한 욕심이 컸다. 하지만, EDA 하느라, 간단한 것 조차도 처음에 제대로 구현을 하지 못 했다. 예를 들어, boxplot이나 violinplot은 어떤 경우에 사용할 수 있으며, 파라미터, 키워드 파라미터를 어떻게 넣어야하며, 어떤 결과가 나오는 지 대략적으로 잘 알지 못 했다. 그래서 이번 MINI EDA에서는 간단한 시각화를 했다. - 데이터 용량 & RAM
: 데이터셋이 2.5GB 를 훌쩍 넘으니까 Colab에서 RAM도 버거웠다. 중간중간에 슬라이싱한 DataFrame을 df.to_csv()로 저장을 했다. 하지만, 이에 대한 방법도 찾아보고, 조언 좀 구해봐야겠다. 연구도 해보고... - Feature Engineering
: 데이터셋의 용량은 둘째치고, 처음에 데이터셋을 확인했을 때, 컬럼의 수가 150개였다. 내가 필요한 컬럼을 어떻게 골라야하는 지 처음에 막막했다. EDA 노트 참고 안 했으면, 아마 지금도 절망 가운데 있었을 것이다. 다른 관점에서 말하자면, 그 만큼 센스가 필요하다는 뜻이고, 그 만큼 연습이 필요하다는 뜻일 것이다. 분발해야겠다.
MINI EDA 포스트를 이제 마치겠다.
긴 글을 읽어줘서 고맙다.
