
2단계: 개략적 설계안 제시 및 동의 구하기
-
알아두어야 할 객체 저장소의 특성
-
객체 불변성(object immutability):
- 객체 저장소에 저장된 객체는 수정할 수 없다.
- 오로지 완전한 대체만 가능하다.
-
키-값 저장소(key-value store): 객체가 저장될 때 특정 URI를 부여한다.
-
저장은 1회, 읽기는 여러 번: 객체 저장소에 대한 요청의 95%는 읽기이다.
❗ 객체 저장소의 읽기, 쓰기 비율
생각했던것보다 쓰기 비율이 높다(5%).
5%라 하면, 1번 쓴 객체를 20번밖에 읽지 않는다는게 아닌가?
-
개략적 설계안
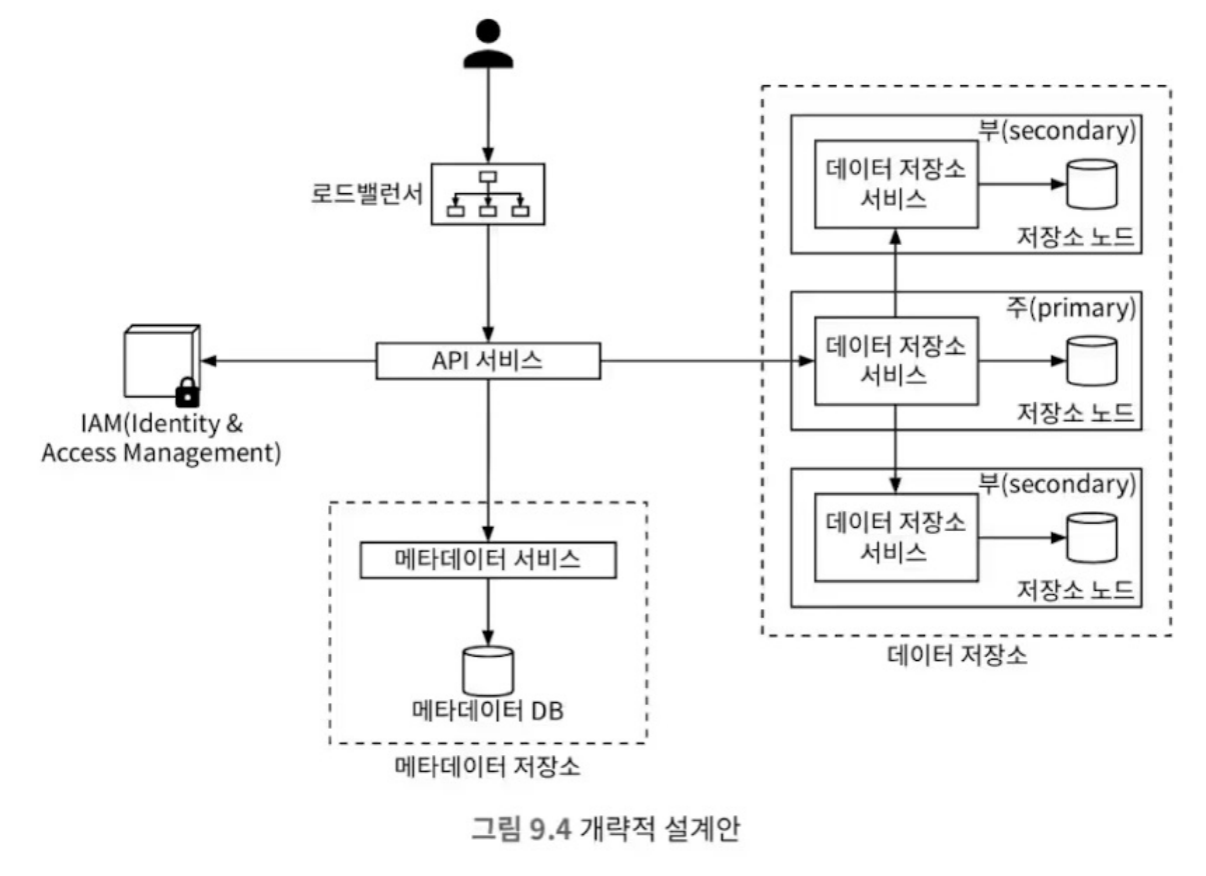
- 주요 컴포넌트
- API 서비스: 무상태 서비스로 확장성 고려
- IAM 서비스
- 인증(authentication)
- 권한 부여(authorization)
- 접근 제어(access control)
- 메타데이터 저장소: 객체의 메타데이터만 별도로 저장
- 데이터 저장소: 객체의 바이너리 데이터만 별도로 저장
객체 업로드
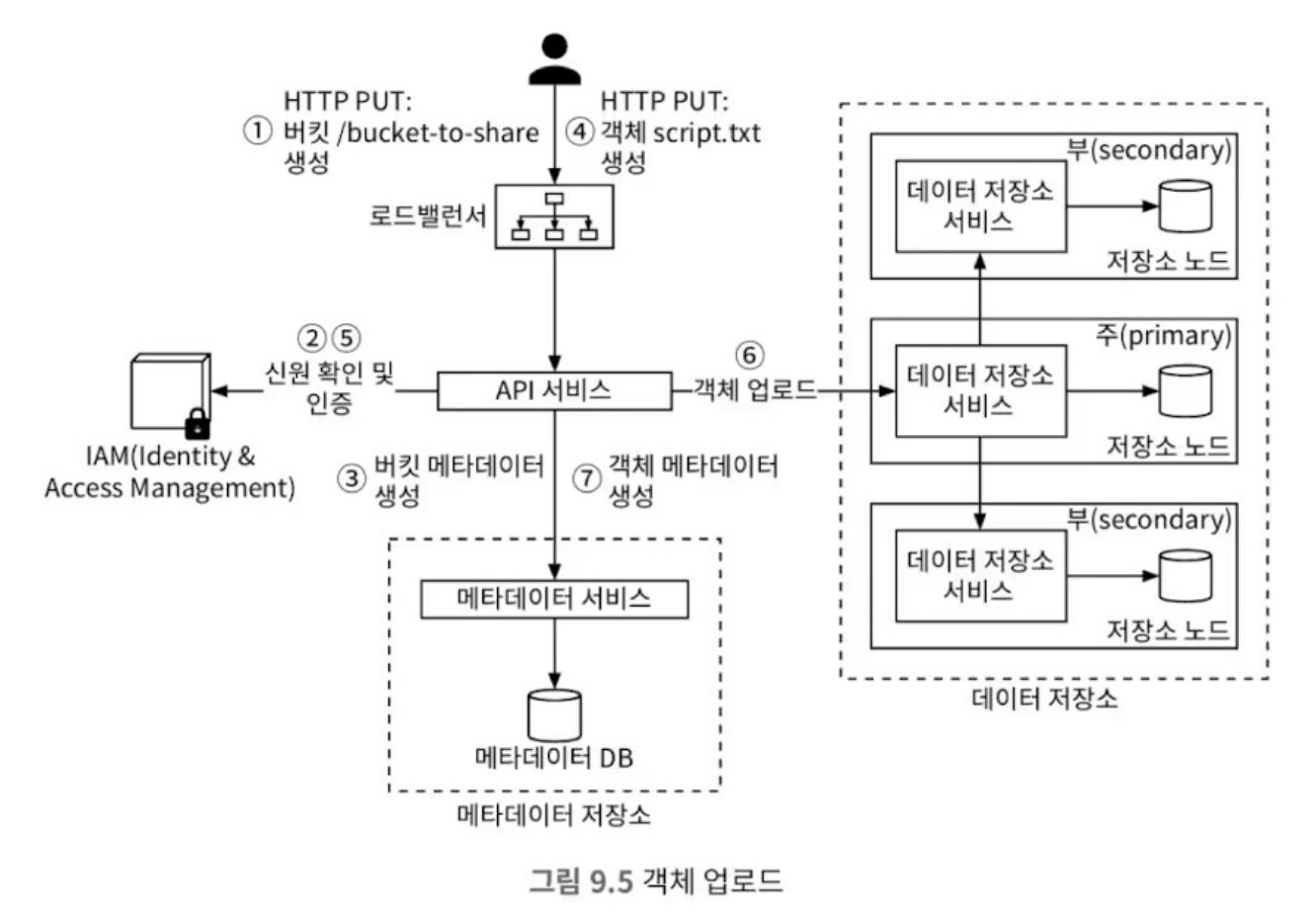
- 버킷 생성(bucket-to-share)
- IAM 서비스로부터 신원 확인
- 버킷 메타데이터 생성
- 객체(script.txt) 업로드 요청
- IAM 서비스로부터 권한 확인
- 객체 업로드
- 객체 메타데이터 업로드
Q. 객체 업로드와 메타데이터 업로드의 순서
메타데이터 업로드가 객체 업로드 이전에 이루어지는 이유는 무엇인가?
- 데이터 정합성 보장
바이너리 객체가 먼저 성공적으로 저장되면, 실제 데이터가 이미 안전하게 보관된 상태임
메타데이터 저장 중 오류가 발생하더라도 실제 데이터는 이미 저장되어 있어 데이터 손실 위험이 적음- 롤백 처리의 용이성
바이너리 저장 후 메타데이터 저장에 실패한 경우: 바이너리 데이터만 삭제하면 됨
메타데이터 저장 후 바이너리 저장에 실패한 경우: 메타데이터가 가리키는 실제 데이터가 없는 상태가 되어 데이터 정합성이 깨질 수 있음- 성능 최적화
큰 바이너리 데이터의 전송과 저장에는 더 많은 시간이 소요됨
바이너리를 먼저 저장함으로써, 실제 데이터 전송 중 발생할 수 있는 네트워크 지연이나 오류에 더 효과적으로 대응 가능
객체 다운로드
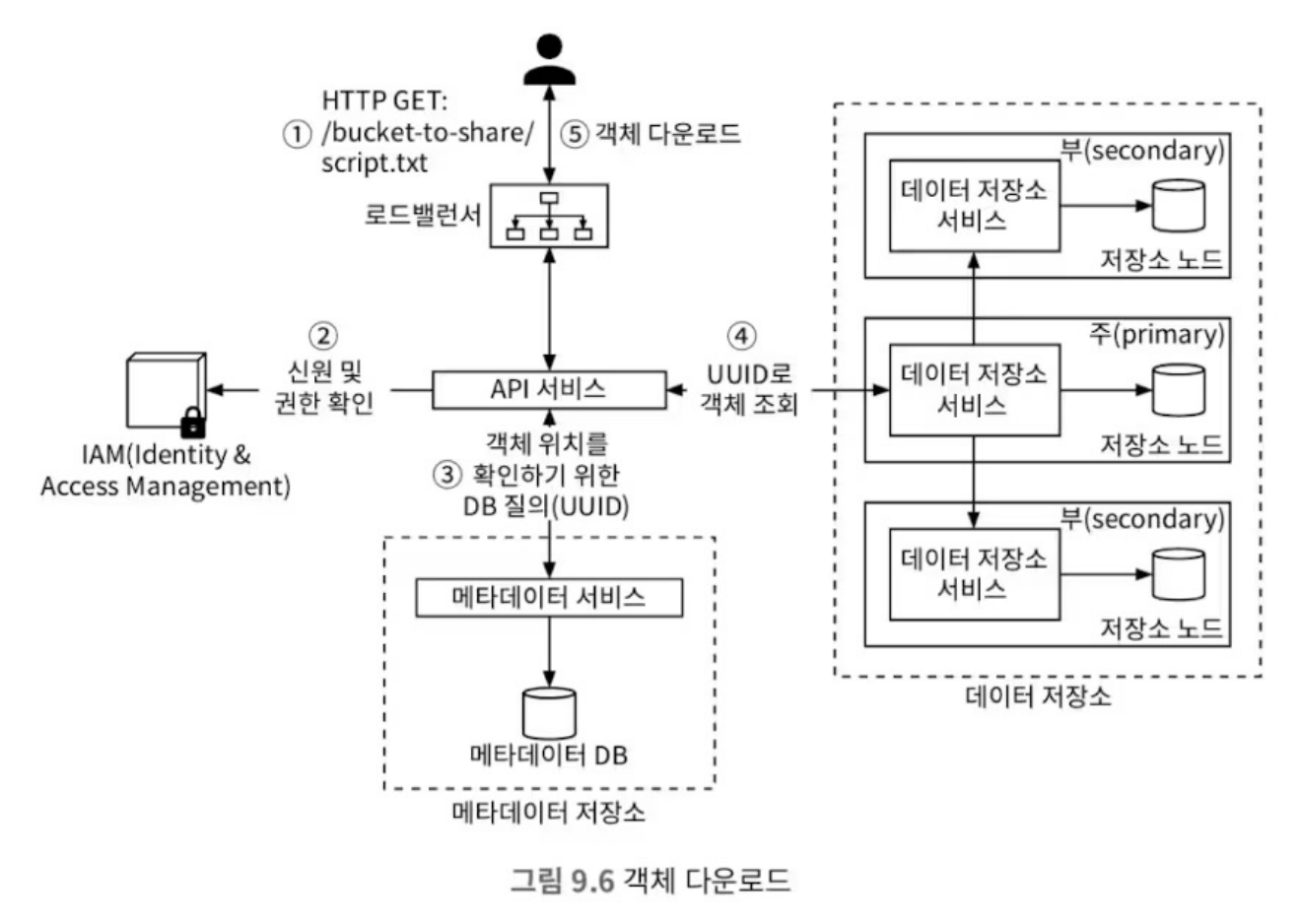
bucket-to-share/script.txt요청- IAM 서비스로부터 READ 권한 확인
- 메타데이터 조회 및 UUID 확인
- UUID를 바탕으로 객체의 바이너리 데이터 조회가
- 데이터 전송

안녕하세요!