
3단계: 상세 설계
- 주요 주제
- 데이터 저장소
- 메타데이터 데이터 모델
- 버킷 내의 객체 목록 확인
- 객체 버전
- 큰 파일의 업로드 성능 최적화
- 쓰레기 수집(garbage collection)
데이터 저장소
- 데이터 저장소는 실제 바이너리 데이터를 저장하는 곳임.
- API 서비스와 연계하여 객체 업로드/다운로드 요청을 처리한다.
데이터 저장소의 개략적 설계
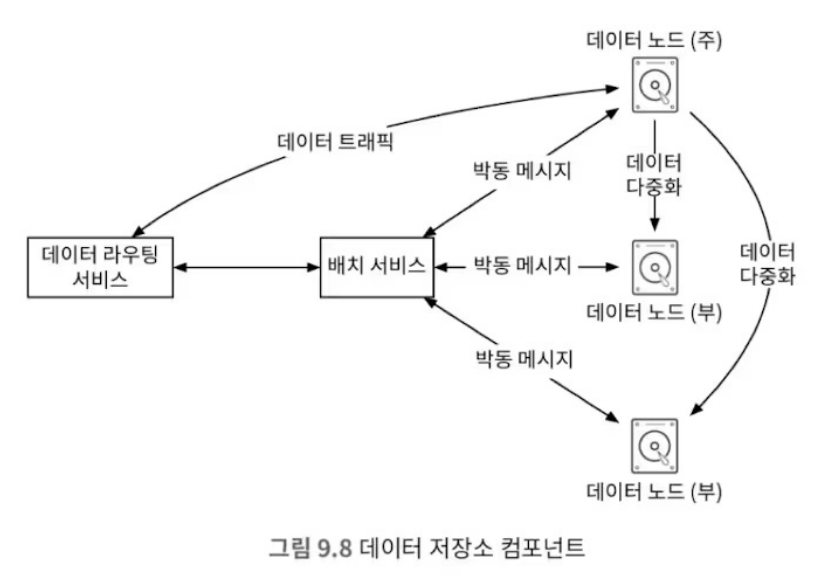
데이터 라우팅 서비스
-
데이터 노드 클러스터에 접근하기위한 REST, 또는 gRPC 인터페이스를 제공한다.
-
무상태 서비스로 확장성을 고려한다.
-
배치 서비스를 호출하여 데이터를 저장할 노드를 선정한다.
-
배치 서비스
-
데잍를 데이터 노드 클러스터 중 어느 노드에 저장할지 결정한다.
-
내부적으로 가상 클러스터 지도를 유지하며, 이를 바탕으로 원본과 사본이 다른 노드에 저장되도록 한다.
-
모든 데이터 노드의 하트비트를 확인하며, 팩서스(Paxos), 래프트(Raft) 등의 분산 합의 알고리즘을 사용하여 데이터 노드 클러스터의 리더를 선출한다.
-
새로운 노드가 추가되면, 이를 가상 클러스터 지도에 추가하고 아래 정보를 반환한다.
- 추가된 데이터 노드의 고유 식별자
- 가상 클러스터 지도
- 데이터 사본을 보관할 위치
-
❗ Paxos, Raft 알고리즘
분산 합의 알고리즘은 분산 시스템에서 여러 노드가 일관된 상태를 유지하고 데이터를 동기화하기 위해 사용되는 알고리즘임.
두 알고리즘의 특징은 다음과 같다.
Paxos
- 역할: Proposer, Acceptor, Learner (노드가 다중 역할 가능)
- 과정: 2단계 커밋 (Prepare → Accept)
- 특징: 이론적 완성도 높음, 구현 복잡, 최적화 가능성 많음
- 사용: Google Chubby, Microsoft Azure
Raft
- 역할: Leader, Follower, Candidate (한 노드 = 한 역할)
- 과정: 리더 선출 → 로그 복제 (임기 기반)
- 특징: 이해/구현 쉬움, 강한 리더십, 단순한 설계
- 사용: etcd, Consul
- 데이터 노드
- 실제 데이터가 보관되는 곳.
- 다수의 노드에 데이터를 복제하여 안정성과 내구성을 보증(다중화 그룹; replication group)
- 각 노드에 서비스 데몬(service daemon)이 실행되어 하트비트를 보내며, 아래와 같은 정보를 함께 전달한다.
- 해당 노드에 부착된 디스크(HDD/SSD)의 수
- 각 드라이브에 저장된 데이터의 양
- 새로운 데이터 노드가 추가되면
데이터 저장 흐름
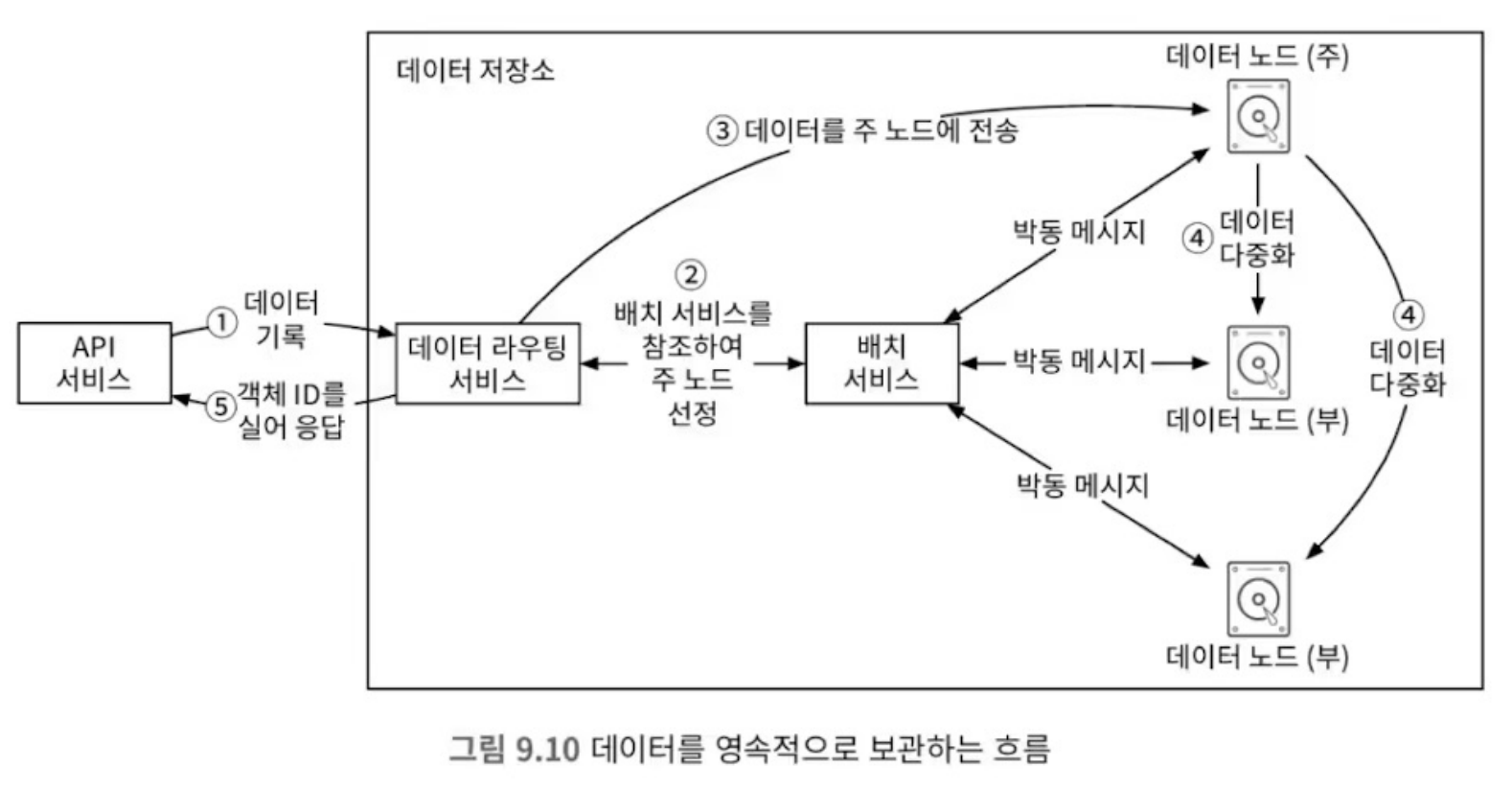
- API 서비스가 객체 데이터를 데이터 저장소로 포워딩
- 데이터 라우팅 서비스는 객체에 UUID를 할당하고, 배치서비스를 통해 데이터를 보관할 노드를 결정
- 데이터 라우팅 서비스가 UUID와 데이터를 주 데이터 노드에게 전달
- 주 데이터 노드는 수신한 데이터를 저장하고, 두 개의 부 데이터 노드에 다중화. 완료 후 데이터 라우팅 서비스에 알림
- 객체의 UUID를 API 서비스에 반환
데이터는 어떻게 저장되는가
-
가장 단순한 방안은 객체 데이터 각각을 파일로 저장하는 것임.
- 이 경우 파일 시스템의 특성상 낭비되는 데이터 블록(일반적으로 4kb)의 수가 늘어남
- 또한 아이노드(inode) 수가 한계를 초과할 수 있음
- 일반적인 경우 아이노드는 디스크 초기화 순간에 결정됨
-
따라서 작은 객체들을 하나의 큰 파일(수 GB)로 모아서 저장
- 이 방법은 같은 파일에 여러 객체를 써야하므로, 순차쓰기가 보장되어야 함.
- 이렇게 객체 소재 확인을 위해 아래의 세 가지 정보가 필요함.
- 객체의 소재 위치(파일 이름)
- 객체의 크기
- 객체의 길이
- 이 정보를 관리하기위해 각 노드에서 SQLite 등의 관계형 데이터베이스를 사용할 수 있음.
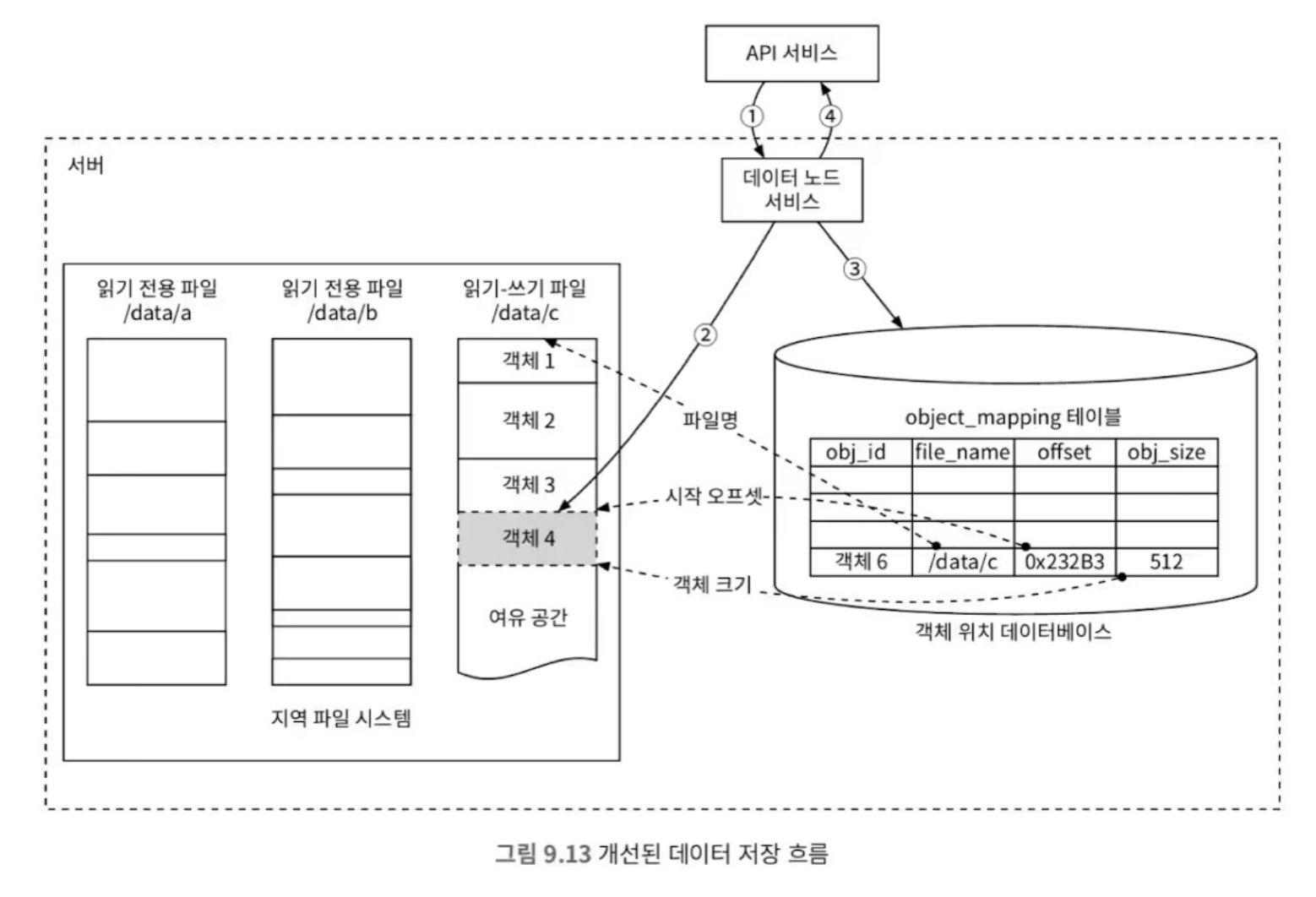
- API 서비스는 데이터를 데이터 노드 서비스로 전달
- 데이터 노드 서비스는 데이터를 파일의 뒤쪽에 append
- 해당 객체에 대한 새로운 레코드를 관계형 DB 내에 row로 추가
- 데이터 노드 서비스는 API 서비스에 객체의 UUID를 반환

안녕하세요!