What's Machine Learning?
머신 러닝은 데이터를 이해하는 알고리즘의 과학이자 애플리케이션이다. 스스로 학습할 수 있는 머신 러닝 알고리즘을 사용하면 이 데이터를 지식으로 바꿀 수 있다.
Types of Machine Learning

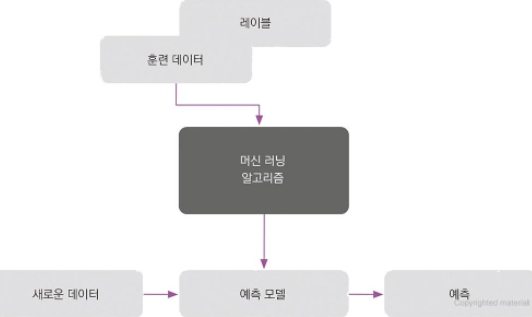
- 지도 학습(supervised learning): 훈련 데이터에서 모델을 학습하며 본 적 없는 미래 데이터를 예측한다. 여기서 지도(supervised)는 희망하는 출력 신호(레이블)가 있는 인련의 샘플(데이터 입력)을 의미한다.
-
분류(classification): 라벨링된 이메일 데이터셋을 지도 학습 머신 러닝 알고리즘을 사용하여 모델을 훈련한다. 훈련된 모델은 새로운 이메일이 두개의 범주(category)중 어디에 속하는지 예측한다. 범주형 순서가 없는 레이블을 샘플에 할당하는 것.
-
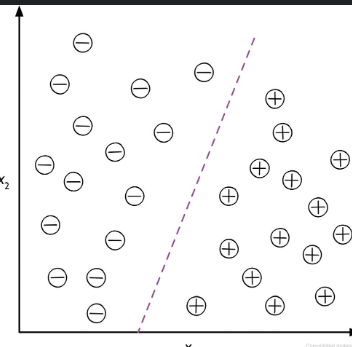
결정 경계(decision boundary): 지도 학습 알고르짐을 사용하여 두 클래스를 구분할 수 있는 규칙을 학습한다. 점선으로 표현한 것이 결정 경계이다. 아래의 그래프에서 x1, x2 주어지면 두개으 범주 중 하나로 분류된다.
-
다중 분류(multiple classification): 두 개 이상의 클래스 레이블을 가진 경우. 예를 들어 손으로 쓴 글자의 인식이다. 예측하려는 대상이 순서가 없는 범주나 클래스 레이블로 표현된다.
- 회귀 분석(regression analysis)
회귀는 예측 변수 또는 설명 변수(predictor variable or explanatory variable)와 연속적인 반응 변수(response variable)가 주어졌을 때 출력 값을 예측한다. 머신 러닝에서는 예측 변수를 feature, 반응 변수를 target이라고 부르기도 한다.
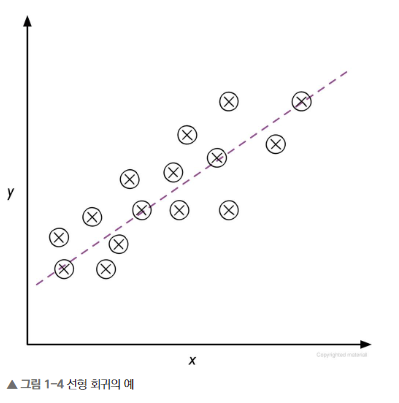
- 선형 회귀(linear regression): feature x와 target y가 주어지면 데이터 포인터와 직선 사이 거리가 최소가 되는 직선을 그을 수 있다.
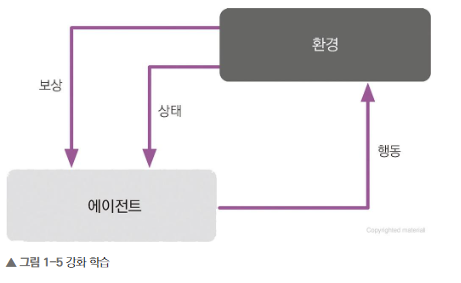
- 강화 학습(reinforcement learning): 강화 학습의 피드백은 정답(ground truth)레이블이나 값이 아니다. 보상 함수로 얼마나 행동이 좋은 측정한다. 예를 들면 체스 게임에서 에이전트는 체스판에 따라 체스말의 이동을 결정한다. 보상은 승리하거나 패배한 것으러 정의한다.
- 비지도 학습(unsupervised classfication): 지도 학습은 모델을 훈련할 때 사전에 옳은 답을 알고 있다. 강화 학습에서는 에이전트의 특정 행동을 보상하는 방법도 같은 이치이다. 비지도 학습에서는 레이블이 아니거나 구조가 알 수 없는 데이터를 다룬다.
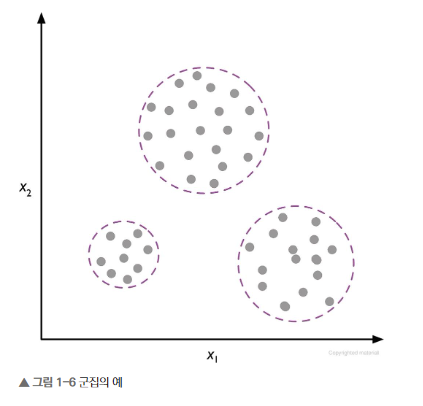
- 군집(clustering): 사전 정보 없이 쌓여 있는 그룹 정보를 의미 있는 서브그룹 또는 클러스로 묶는 탐색적 데이터 분석 기법이다.
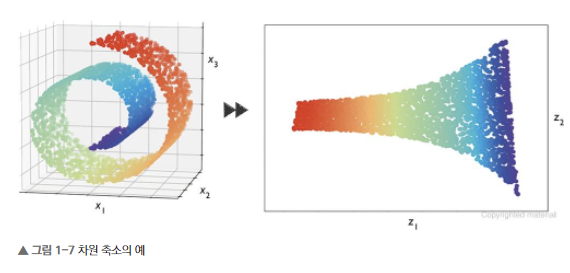
- 차원 축소(dimensionality reduction): 하나의 관측 샘플에 많은 측정 지표가 있어서 머신 러닝 알고리즘이 계산 성능과 저장 공간의 한계에 맞닥뜨릴 수 있다. 비지도 차원 축소는 잡음데이터를 제거하기 위해 feature enginering 단계에서 종종 사용한다.

Hi there! I'm from Korea and currently working in Singapore. This is my journey to master Machine Learning/Deep Learning