- 저자 : davide scaramuzza, Fraundorfer (2011년)
0. Introduction
- visual odometry(VO)는 하나 또는 여러개의 카메라를 사용하여 agent(차량, 사람, 로봇)의 egomotion(자기 자신의 움직임)을 추정하는 과정이다
Visual Odometry
- Visual Odometry라는 단어는 2004년 Nidter의 논문에서 처음 등장
- Wheel Odometry와의 유사성으로 인해 Visual Odometry라고 붙였다
- Wheel Odometry는 바퀴의 회전 수를 이용하여 차량의 움직임을 추정하는 것인데 wheel 아니라 camera를 사용하니까 Visual Odometry
VO 작동 환경
- 충분한 광량
- 고정된 환경(static scene)에서 tecture가 충분해야한다
- 연속된 frame들은 서로 충분하에 ovarlap 되어야한다
VO의 장점
- 울퉁불퉁한 면(uneven terrain)에서 wheel slip이 일어나서 오류가 쌓이지만 VO는 영향을 받지 않는다
- tragectory 추정이 더 정확하다
- wheel odometry, GPS, IMU, laser odometry(lidar)와 함께 사용할 수 있다
- 심해,공중과 같이 GPS를 사용할 수 없는 곳에서 VO는 중요하다
1. History of Visual Odometry
- Structure From Motion(SFM)
- 여러 장의 카메라 이미지가 있을 때 camera pose와 3D 공간을 추정하는 것
- VO
- SFM의 종류 중 하나
- 3D reconstruction과 camera pose를 구하는 것은 같은데 이미지가 무조건 연속적이여야하고 실시간으로 동작해야하기 때문에 SFM의 특정한 경우이다
- moravac의 VO
- slider stereo 사용 : 카메라를 rail위에 올리고 rail 위에서 움직일 수 있다
- maravac corner detector로 코너를 찾고 epipolar line을 기반으로 매칭
- tracking을 할 때는 normalized cross correlation을 이용
- ormalized cross correlation : 템플릿 매칭 방법 중 하나
- matching을 할 때는 coarse-to-fine 방법
- outlier 제거
- 나미저 data로 motion 계산
- triangulation을 통해 3D point를 만들어 준다
- weighted least square 사용
- weighted : 3D point과의 거리를 반비례해서 사용 (가까우면 큰 weight)
- mono view의 단점
- motion은 scale factor까지만 계산된다
- 실제 세상의 m단위의 scale이 아니다, scale은 어떤 것이 될지 모른다
- absolute scale (matrix scale)을 얻고 싶으면
- direct measurement (실제 scene의 물체의 크기를 잰다)
- motion constraint를 넣어준다
- imu, air-pressure 등의 다른 센서로부터 거리값을 받아와서 matrix scale을 복원할 수 있다
- Stereo VO
- mono처럼 안좋아질 수 있다
- stereo base line보다 sence이 훨씬 큰 경우에는 mono랑 다르지 않다
--
1-1. Stereo VO
- 과거에는 어떤 방법들이 사용되어있는지 확인
- harris corner detector 사용
- RANSAC을 통해 outlier 제거
- stereo disparity map 사용
- Iterative Closest Point(ICP) 방법을 통해 motion 추정
- 3D-to-3D point registration
- 두 이미지에서 3D 포인트를 추정하고 그 추정된 3D point들을 alignment해서 두 라메라 사이의 relative pose를 구하는 방법
- 초창기에 이 방법을 통해 stereo VO가 많이 사용되었다
Nister 논문
- VO 용어를 처음 만든 논문
- real-time long-run implementation(멀리까지 가능) with robust outlier rejection
- frame 마다 tracking을 하지 않고 harris corner를 사용하여 모든 frame에서 독립적으로 찾은 후 매칭이 된 feature만 사용
- feature drift가 없어져서 더 좋은 결과가 나왔다
- 이전의 방식은 이전 프레임의 feature의 patch를 다음 프레임과 매칭하며 tracking하였는데 이렇게 되면 시간이 지나면서 drift가 쌓일 수 있다
- 3D-to-2D 카메라 pose로 relative motion을 계산했다 -> 이게 PnP 방식
- 이전에는 3D-to-3D
- RANSAC을 사용해서 outlier를 제거
1-2. Monocular VO
- 특징
- absolute scale을 알 수 없다
- 첫번째와 두번째 frame 사이의 거리가 scale에 따라 달라지는데 1로 고정
- 그 이후부터는 3D structure를 reconstruction하면서 scale을 구하면서 간다
- 3가지 방식
- feature-based method (feature SLAM)
- salient and repeatable feature 사용 (같은 곳에서 재검출될 수 있는 feature)
- frame 마다 tracking하면서 3D reconstruction
- appearance-based method (direct 방식)
- 모든 픽셀의 intensity 정보 사용
- hybrid method
- feature-based method (feature SLAM)
feature-based method
- 처음으로 실시간, large scale VO를 성공 -> nister
- 5point minimal solver 사용 -> essential matrix 계산
- local windowed-bundle adjustment 사용 -> motion과 3D map을 구하는 방법도 있다
- motion을 구할 때 rotation과 translation 따로 계산하는 경우도 있다
appearance-based method
- 2010년에는 많은 연구가 진행되지 않았다
hybrid method
- SVO부터 이 방법이 유명해지기 시작했는데 SVO는 2015년이다. 이 논문은 2010년
정리하면..
- 모든 방식들은 6Dof에서 motion을 계산
- 6DoF : 3축 회전 + 이동 모두 가능 -> 자유도가 매우 높다
- 차량의 경우 motion constraint가 있기 때문에 6DoF가 필요없다
- 특별한 VO 방법을 사용하면 연산 시간이 단축되고 motion 정확도가 증가
1-3. Reducing the Drift
- drift : frame-to-frame motion을 계산하면서 나타나는 error가 시간이 지나면서 쌓인 것
- sliding window bundle adjustment 또는 windowed bundle adjustment를 통해 줄일 수 있다
- 마지막 n개의 카메라 pose에 대해 local optimization
1-4. V-SLAM
- V-SLAM의 구현 방식
- filtering : kalman filter
- non-filtering (keyframe 방식) : BA
1-5. VO와 V-SLAM의 차이
- SLAM
- global consistance 해야한다 (전체 map과 pose가 정확해야한다)
- loop closure : 이전에 방문한 곳에 다시 왔다는 것을 알아채야한다 / drift 제거 가능
- loop closure, global optimization -> matrically consistent map을 구한다
- VO
- incrementally recovering the path
- window BA : 최근 n개의 pose만 최적화하고 있을 가능성이 높다
- local consistency가 중요
- incremental motion을 구한다
- envirment map이 아닌 카메라 path만 궁금 -> VO를 쓰면 된다고 생각할 수 있지만 VSLAM이 더 정확하니까 여전히 VSLAM을 써야할 수도 있다.
- VO와 VSLAM 선택
- 속도, 정확도, consistency, 구현의 simplicity를 고려
2. Formulation of the VO problem
- k : 시점
- monocular의 경우 시점 k에 찍힌 사진들의 모음
- stereo의 경우 시점 k에 찍힌 사진들의 모음
- 카메라 coordinate frame을 agent의 coordinate frame으로 가정 (카메라가 agent라고 생각)
- stereo의 경우, 왼쪽을 원점으로 사용
- k-1과 k 시점의 카메라 position은 rigid body transformation으로 이어져있다
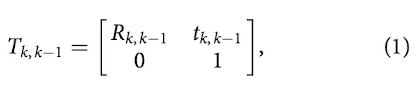
- : k-1에서 k로 가는 transformation
- : 4x4 형태의 실수들의 집합
- R_{k, k-1} \in SO(3)} : rotation matrix
- : 3x1 실수 형태의 translation matrix
- 전체 motion의 집합
- 를 이제는 라고 하겠다
- 카메라 pose의 집합
- 카메라 pose는 world에서 카메라간의
- relative motion는 시간이 지나면서의 카메라의 이동에 대한 것
- 첫 에 모든 transformation을 concatenating(계속 곱)하면 현재 이 구해진다
- VO의 main task
- relative transformation을 계속 구해서 full trajectory(카메라 전체 궤적) 을 구하는 것
- VO는 순차적으로 path를 구한다
- 3D point를 triangulation해서 map을 구한다
- monocular VO에서 언급했듯이 T를 계산하는 2가지 방식
- appearance-based(global) method는 feature-based 방법보다 부정확하고 연산량이 많다
- 이때는 그럴 수 있지만 나중에는 global 방식이 더 좋을 수 있다
VO pipeline
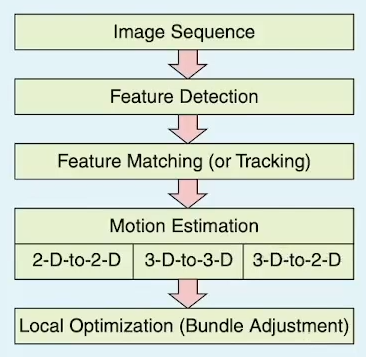
- motion 추정
- 2D -> 2D : essential / fundamental matrix 방식
- 3D -> 3D : ICP
- 3D -> 2D : PnP
- feature mapping과 tracking을 한다
- 모든 이미지에서 독립적으로 feature를 찾고 similarity metrics로 matching
- local search technique을 써서 tracking
3. Camera Modeling and Calibration
3-1. Perspective Camera Model
- 핀홀 카메라 projection 시스템을 의미
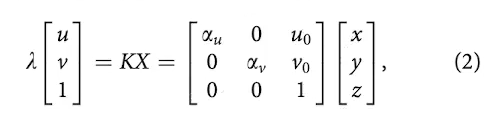
- : depth factor
- , : focal length
- , : projection 중심의 image coordinate
- 이것들은 intrinsic parameter라고 한다
- field of view(화각)이 45도가 넘으면 radial distortion이 생길 수 있기 때문에 조금 더 높은 계수를 사용해서 radial distortion을 모델링 해야한다
3-2. Omnidirectional Camera Model
- 180도가 넘어가는 화각을 가진 카메라 -> fish eye lens, 거울을 사용한 catadiopric camera에서도 사용가능
- 두 개의 모델을 사용
- Geyer and Daniilidis
- Scaramuzza
- fiehc
3-3. Spherical Model
3-4. Camera Calibration
- intrinsic과 extrincis 파라미터를 정확하게 측정하기 위한 방법
- plannar checkerboard-like 패턴을 여러 위치, 방향에서 찍은 후 least square minimization 방식을 사용하여 계산
4. Motion Estimation
- 현재 이미지와 이전 이미지 간의 카메라 motion을 추정
- 3가지 방법
- 2D -> 2D : essential / fundamental matrix
- 3D -> 3D : ICP
- 3D -> 2D : 3D에서 2D를 가지고 추정, PnP
- feature : point 또는 line으로 사용, plane도 가능
- 이 당시에, 일반적인 상황에서는 line이 뽑힐 경우가 많이 없기 때문에 point를 사용하는 경우가 많다
4-1. 2D to 2D: motion from Image feature correspondences
essential matrix 추정
- 카메라 motion 파라미터 : 5DoF (rotation 3, translation 2, scale 모름)
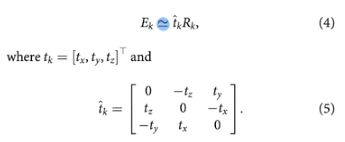
- essential matrix를 계산할 때는 2D-2D feature correspondence가 필요
- E로부터 rotation과 translation을 뽑을 수 있다
- epipolar constraint
- feature는 반대쪽의 epipolar line에 위치해있다
- minimal case solution
- 가장 적은 수의 data point를 사용하여 E 추정 -> 5 point 알고리즘
- outlier가 있으면 RANSAC도 적용
- 이 방법이 standard
- 8 point 알고리즘
- calbrated uncalibrated 카메라 모두 쓸 수 있다
- 5 point는 calbrated가 되어 있어야한다
- 동작하지 않는 경우 : 모든 3D point가 coplanar의 경우 (후에 8개 중에 5개 이상이 coplanar이면)
R, t, E 추출
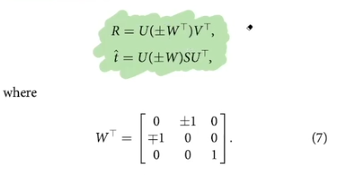
- 4개의 답이 나올 수 있다
- 이런 경우 point 하나를 triangulation해서 방향이 맞는지 확인
- 좋은 값을 찾으면 비선형 최적화를 해서 정확도를 높인다
- 비선형 최적화를 할 때 초기값은 5 point RANSAC으로 구한 R, t 사용
- reprojection error 기반으로 최적화
Relative Scale 계산
- 이미지 두개로는 scale을 알 수 없다
- 상대적인 scale만 구할 수 있다
- 2갸의 이미지에서 3D point를 triangulate하고 2개 point 사이의 거리를 구하면 relative scale 구할 수 있다
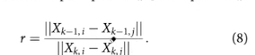
- 이렇게 구한 scale값을 translation vector에 곱해서 distance 값을 구할 수 있다
- 자율주행에서는 wheel encoder를 활용하여 wheel odometry 값을 통해 motion 값을 얻을 수 있다. wheel slip이 없다고 하면 이를 scale값으로 사용하여 여기서 translation을 추가하여 사용하는 경우도 있다. wheel을 사용하면 연산이 짧아진다.
4-2. 3D-to-3D: motion from 3D Structure Correspondences (ICP)
- 두개의 3D landmark를 align하면서 둘 사이의 transformation을 구한다
- stereo에서 많이 쓴다고 하지만 요즘에는 PnP를 많이 쓴다
- lidar slam에서 많이 사용한다
- ICP 알고리즘
- 과거의 data들을 현재 시점으로 옮겨주는 transformation을 수행하고 그 결과가 현재 data와의 차이가 최소화되도록
- noncolinear한 3개의 correspondence를 통해 minimal case solution을 할 수 있다
- 하지만 3개 이상의 correspondence를 활용하면 계산할 수 있다 (ICP)
4-3. 3D-to-2D: Motion from 3D Structure and Image Feature Correspondences (PnP)
- 3D to 2D 방법이 3D to 3D보다 정확하다
- image reprojection error를 최소화
- 이 방법이 PnP이다
- minimal case
- P3P : 4개의 solution을 return하는데 하나의 point를 더 사용하여 더 정확한 결과를 얻을 수 있다 -> P3P plue 1 또는 P4P
- 3D-to-2D에서 P3P는 outlier가 있을때에도 쓸 수 있는 standard 방법
- Direct linear transformation(DLT)
- 6개 이상의 point를 사용하는 PnP
- SVD를 활용하여 계산한다
- 이를 통해 R, t를 구한 후 모든 data에서 nonlinear optimization을 통해 보정
4-4. Triangulation and Keyframe selection
- Triangulation이 필요한 이유
- PnP를 하기 위해서는 3D point가 필요
- 3D point는 2D image의 correspondence를 사용해서 구할 수 있다
- BA를 하는데에도 3D가 필요
- Triangulation 하는 법
- 최소 2개의 image frame에서 2D coresspondence가 있을 때 coresspondence를 ray로 back=projection하여 intersection하는 부분을 찾는다
- 하지만 ray는 실제로 intersect하지 않는다
- 그래서 최소 거리의 point를 least squares를 통해 구한다
- uncertainty가 높으면 그 frame은 skip -> keyframe으로 사용
Discussion
- stereo의 경우 3D to 2D를 쓰는 경우가 많다
- 3D만 쓰는 경우는 position error가 크기 때문에
- monocular의 경우 3D to 2D를 쓴다
- 더 빠르기 때문
- 2D to 2D를 하는 경우 최소 5개의 correspondence가 필요한데 3D to 2D의 경우 3개만 있으면 되어서 더 빠르다
- 하지만 나중에 비교를 해보면 2D to 2D의 경우 scale이 변경될 수 있지만 3Dto2D의 경우 map이 잘되어 있다면 잘된다
- stereo의 경우 좋은 점
- 3D feature를 바로 absolute scale에 맞춰 계산할 수 있다
- triangulation을 할 때 camera간의 baseline을 사용하기 때문
- 그래서 stereo가 monocular에 비해 drift가 더 좋다
- stereo의 경우 baseline이 너무 길면 mono처럼 된다
- local BA를 항상 돌려야한다
