[Paper review] Learning Transferable Visual Models From Natural Language Supervision
Paper review
논문 링크 : https://arxiv.org/pdf/2103.00020.pdf
CLIP: ConnectingText and Images
Contrastive Language-Image Pre-training(CLIP)
일반적인 컴퓨터 비전 모델은 사전학습된(pre-trained) task에 대해 우수한 성능을 보이지만, 그 외 task에 대해서는 낮은 성능을 보인다. 따라서 새로운 task에 적합한 미세조정(fine-tuning)이 필요하며, 이를 위해 새로운 데이터셋과 추가 레이블링 작업이 많은 비용과 함께 뒤따른다.
이처럼 일반화 성능이 낮고 비효율적인 기존 사전학습 기법에서 벗어나, 최근 인터넷 상의 이미지와 텍스트 데이터를 함께 사용하여 미세조정 없이도 일반화된 이미지의 특징을 잘 추출하는 대조학습(contrative learning) 기법이 고안됐다.
what we need is
- fine-tuning 이 필요 없는 일반화된 모델
- 이미지 수집 및 정답 레이블 생성에 적은 노력이 드는 모델
- 벤치마크 데이터셋 외 여러 현실 데이터셋에서도 좋은 성능을 보이는 강건한 모델
CLIP의 핵심은 텍스트에 포함된 supervision으로 학습하는 것
- 자연어를 이용하는 학습 방법은 un/semi/self-supervised learning 방법과는 달리 이미지 representation 뿐만 아니라, 언어 representation을 가지기 때문에 조금 더 유연하고 robust한 장점을 가지게 된다. (유연한 zero-shot transfer 를 가능하게 함)
- 기존 일반적인 분류 모델은 이미지의 의미론적 정보를 학습하지 못함
- CLIP은 이미지와 이미지를 설명하는 텍스트를 결합한 image-text pair를 입력으로 사용
- 이미지와 언어에 대한 representation을 함께 학습하여 일반화된 특징 학습 가능
- 기존 : visual representation → CLIP: visual representation + Semantic information
- 라벨링을 요구하지 않기 때문에 확장에 용이함. 기존에 CV분야는 라벨링이 필수적이었지만 텍스트를 이용하면 그러한 과정이 없어도 됨.
- WebImageText (WIT) - 규모 : 4억개, 범주: 50만개, 레이블링 인력 : 불필요
- 인터넷으로부터 레이블링이 필요없는 약 4억개의 image-text pair 데이터 수집
- 다양한 분야의 텍스트 및 이미지를 수집하기 위해 총 50만건의 검색 수행
- 이미지의 균형을 맞추기 위해 각 검색어당 이미지는 최대 2만개로 조절
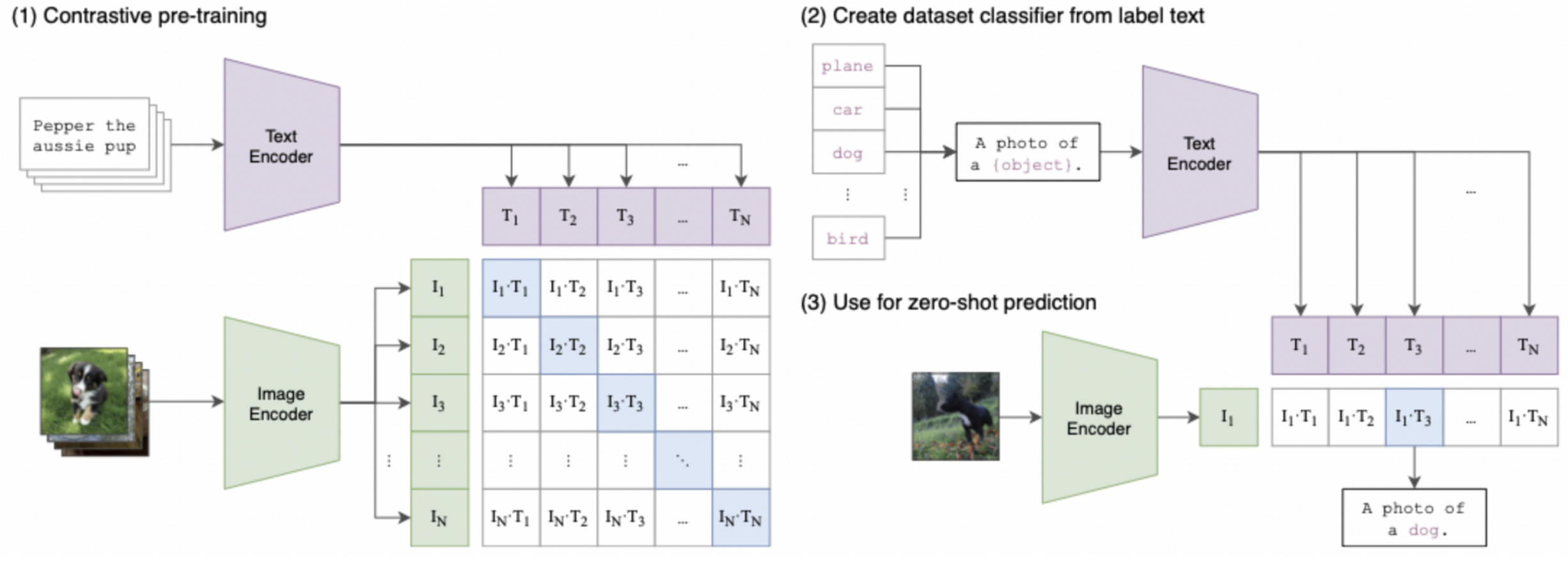
1. Contrastive pre-training
대각선의 코사인 유사도를 최대화하고, 나머지 쌍들은 코사인 유사도를 최소화 하는 방향으로 이미지 인코더와 텍스트 인코더를 함께 학습. → multi-modal 임베딩 공간을 학습
Image encoder
이미지 인코더를 두개의 구조로 고려했는데, 하나는 ResNet-50 이며, 다른 하나는 Vision Transformer(ViT)
1) ResNet-50
원래 ResNet 에서 수정된 버전을 사용했는데, global average pooling을 attention pooling으로 대체하고 ResNet-D 버전 사용
2) ViT (Vision Transformer)
layer normalization을 추가하는 것 외에 기존의 모델을 따로 수정하지는 않고 사용
3. Text encoder
Transformer, max length는 76으로 제한
- 적용하고자 하는 특정 하위 문제의 데이터셋 레이블을 텍스트로 변환
- 단순 단어가 아닌 “a photo of {}”에 해당하는 구로 변환
- 단어에서 구로 변환하여 인코더 입력 시 성능 향상되었다는 실험 결과
정리
why?
-
fine-tuning 이 필요 없는 일반화된 모델
-
이미지 수집 및 정답 레이블 생성에 적은 노력이 드는 모델
-
벤치마크 데이터셋 외 여러 현실 데이터셋에서도 좋은 성능을 보이는 강건한 모델
How?
- Web-based image-text pair를 기반으로 visual representation 을 학습
- 대량의 레이블링이 필요없는 데이터셋을 기반으로 다양한 분야에 대해 학습 가능
- Contrastive learning 기반 pre-training을 통해 효율적이면서 domain shift에 강건한 학습 가능
