[Paper review] “Why Should I Trust You?” Explaining the Predictions of Any Classifier
Paper review
논문 링크 : https://arxiv.org/abs/1602.04938
Abstract
현재 머신러닝 모델들은 대부분 블랙박스 모델
모델 예측의 근거를 이해하는 것은 매우 중요하고 이는 전체적인 모델의 신뢰도를 판단하는 데에 사용 될 수 있다.
-
이 연구에서는 해석 가능한 학습을 통해 모든 classifier의 예측을 해석 가능하고 충실하게 설명하는 새로운 설명 기법인 LIME를 제안한다.
LIME 기법의 유연성을 보여주기 위해 텍스트 분류와 이미지 분류를 예시로 보여준다.
-
또한 서브모듈러 최적화 문제로 작업을 프레이밍하여 대표적인 개별 예측과 설명을 중복되지 않는 방식으로 제시함으로써 모델을 설명하는 방법을 제안한다. 텍스트(예: 랜덤 포레스트) 및 이미지 분류(예: 신경망)에 대한 다양한 모델을 설명하여 이러한 방법의 유연성을 보여준다.
Introduction
trust 의 두 가지 정의
(1) Trusting a prediction : 사용자가 모델의 예측을 참고하여 행동으로 옮길 만큼 충분히 신뢰하는지.
예를들어 모델이 의학적 진단, 테러 감지에 대한 판단을 할 때 blind faith 를 기반해서 내리면 안된다.
(2) Trusting a model: 모델이 배포될 경우 모델이 합리적인 방식으로 작동하는 지에 대해 신뢰하는지.
모델이 real word data 에서도 잘 작동하는지에 대해 사용자가 충분히 납득 할 수 있어야 한다.
보통 머신러닝 모델은 검증 데이터의 accuracy를 참고해 학습이 진행되는데 real world data는 이와는 괴리가 존재할 수 있고 accuracy를 정하는 방식이 우리의 목표와 맞지 않을 수도 있다.
위의 두 신뢰도는 인간이 모델의 예측방식에 대해 얼마나 이해하는 지에 따라 영향을 받는다.
이 논문에서 우리는 "예측 신뢰" 문제에 대한 솔루션으로 개별 예측에 대한 설명을 제공하고 "모델 신뢰" 문제에 대한 솔루션으로 이러한 예측(및 설명)을 여러 개 선택하는 것을 제안한다.
- LIME, an algorithm that can explain the predictions of any
classifier or regressor in a faithful way, by approximating
it locally with an interpretable model. - 어떤 분류기(classifier)나, 회귀기(regressor)의 예측에 대해 해석가능한 모델로 (지역적으로) 근사함으로써 설명할 수 있는 알고리즘(trusting a prediction).
- SP-LIME, a method that selects a set of representative
instances with explanations to address the “trusting the
model” problem, via submodular optimization. - 서브모듈러 최적화(submodular optimization)를 통해 설명 가능한 대표적인 예시들을 뽑아 모델을 신뢰할 수 있게끔 하는 방법(trusting the model).
‘Explaining a prediction’ 이란 문장 내 단어들 또는 이미지 내 패치 같은 구성요소들과 모델의 예측 사이의 관계를 이해할 수 있는 양질의 시각 정보를 제공하는 것으로 볼 수 있다. 인공지능 모델을 사용하는 사람은 해당 분야에 지식을 가지고 있기 때문에 모델로부터 설명을 받으면 그 설명이 타당한지, 아닌지를 판단 할 수 있다.
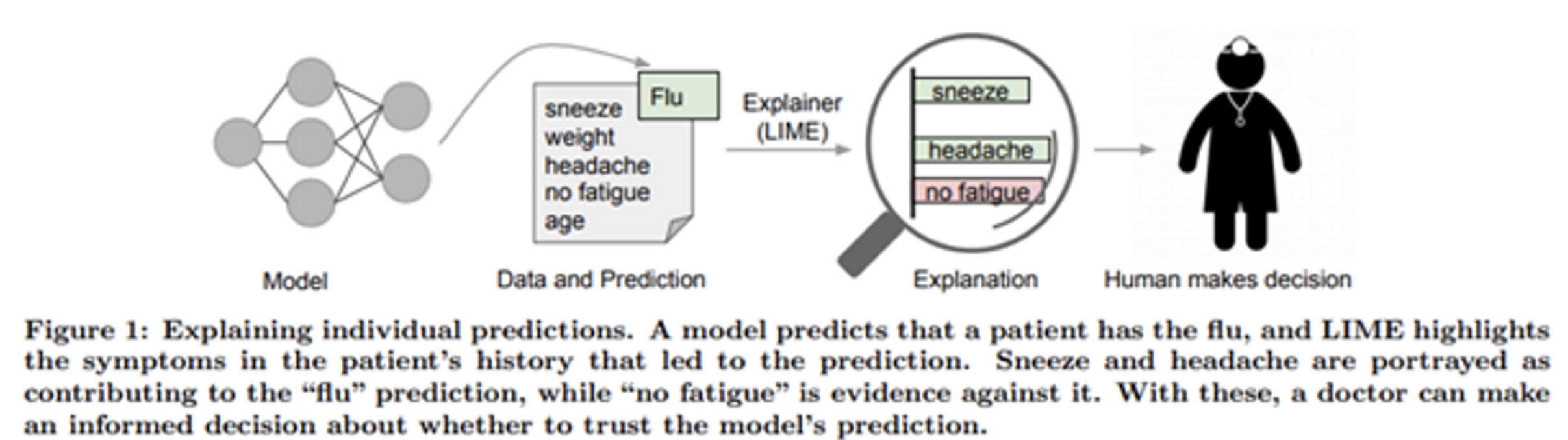
모델은 환자가 감기에 걸렸다고 판단하고 LIME 은 판단의 근거가 되는 증상을 보여준다.

특정 문서가 기독교에 관한 것인지, 무신론에 관한 것인지 예측하는 두개의 classifier. 막대 그래프는 그 판단에 가장 관련 있는 단어의 중요도를 보여준다.
현재 인공지능 모델은 검증 데이터를 통해 성능을 판단하는데 실제 데이터에 대해서는 이 성능이 발휘되지 않을 수도 있다. 또한 accuracy에 의존해서 신뢰도를 결정하는 것은 위험하다. 위에 그림에서 “Atheism”을 판단하는 근거로 Posting, Host, Re 와 같은 관련없는 단어들이 제공된 것을 보면 알 수 있듯이 단순히 accuracy에만 의존하는 모델은 신뢰할 수 없다.
Desired Characteristics for Explainers
-
Interpretable
입력과 결과에 대한 질 좋은 설명이 제공되어야 한다. 사용자의 수준에 맞게 설명이 제공되어야하며, 비전문가 또한 예측을 쉽게 이해할 수 있어야 한다.
-
Local fidelity
예측에 대한 설명은 적어도 지역적으로 신뢰되어야 한다. 즉 모델이 하나의 데이터에 내린 판단에 대해 설명할 수 있어야 한다.
-
Model-agnostic
어떠한 모델을 사용하든 설명 가능해야 한다.
-
Global-perspective
정확도만으로는 모델을 정확하게 평가할 수 없기 때문에, 어느 정도 전체적인 모델에 대한 설명 또한 제공되어야 한다.
Local Interpretable Model-Agnostic Explanations(LIME)
위와 같은 Explainer을 제공하기 위해 LIME 를 제안한다.
LIME의 전반적인 목표는 기존의 classifier 에 대해 지역적으로 신뢰를 보이는 해석가능한 표현들을 통해 해석 가능한 모델을 정의(식별)하는 것이다.
3.1 해석 가능한 데이터 표현
특성(features)과 해석 가능한 표현(interpretable data representations)의 차이를 구별하는 것은 중요하다. 해석가능한설명은 보통 모델에 쓰이는 feature 와 관계없이 사람이 이해할 만한 표현을 사용해야 한다.
classifier 가 단어 임베딩 같은 더 복잡하고 이해할 수 없는 기능을 사용할 수 있지만 텍스트 분류를 위한 해석 가능한 표현은 단어의 존재 여부를 나타내는 이진 벡터이다. 이미지 분류도 마찬가지로 해석 가능한 표현은 유사한 픽셀의 인접 패치의 존재 또는 부재를 나타내는 이진 벡터일 수 있지만 classifier는 이미지를 세가지 색상의 텐서로 나타낼 수 있다.
3.2 Fidelity-Interpretability Trade-off
공식적으로 우리는 설명을 모델 g ∈ G로 정의합니다. 여기서 G는 선형 모델, 의사 결정 트리 또는 떨어지는 규칙 목록 과 같은 잠재적으로 해석 가능한 모델의 클래스
g 의 영역은 {0,1}
g는 해석 가능한 구성 요소의 부재/존재에 대해 작동
충분히 단순하지 않을 수 있으므로 Ω(g)를 설명 g ∈ G의 복잡성(해석 가능성과
반대되는)의 척도로 설정
