파이썬을 처음 접해서 그런지 많이 어렵습니다
요즘엔 파이썬을 구글 colab에서 많이 접한다고 한다.
1주차
파이썬이란? 가장 직관적인 문법을 가진 언어다.
Google Colab을 사용할 것이다.
주의
Google Colab은 무료로 제공되는 만큼 사용제한이 있다. 연속 연결 시간 최대 90분, 하루 이용 제한 12시간
파이썬 기초 1
1) 변수와 기본연산
변수는 마음대로 이름을 지을 수 있다.
기본연산은
a = 3 -> 3을 a에 넣는다
b = a -> a를 b에 넣는다
a = a + 1 -> a+1을 다시 a에 넣는다
2) 리스트, 딕셔너리 형
리스트는 순서가 중요하다
a_list = ['사과','배','감','수박']
a_list[0]
a_list.append('귤')
a_list[4]딕셔너리는 {key : value}가 중요하다
a_dict = {'name':'bob','age':21}
a_dict['age']
a_dict['height'] = 178
a_dict
3) Dictionary 형과 List 형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}]
people[0]['name']의 값은? 'bob'
people[1]['name']의 값은? 'carry'
person = {'name':'john','age':7}
people.append(person)people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}]
people[2]['name']의 값은? 'john'
4) 함수
def sum(a,b):
return a+bdef mul(a,b):
return a*bresult = sum(1,2) + mul(10,10)
result라는 변수의 값은?
파이썬 기초 2
1) 조건문
if age > 20:
print('성인입니다') -> 조건이 참이면 성인입니다를 출력
else:
print('청소년이에요') -> 조건이 거짓이면 청소년이에요를 출력is_adult(30)
2) 반복문
ages = [20,30,15,5,10]
for age in ages:
print(age)
for age in ages:
if age > 20:
print('성인입니다')
else:
print('청소년이에요')
3) 조건문 + 함수 + 반복문
def check_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년이에요')ages = [20,30,15,5,10]
for age in ages:
check_adult(age)
웹스크래핑연습
먼저 라이브러리 설치
!pip install bs4 requests
크롤링 기본코드 가져오기
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
a = soup.select_one('#sp_nws1 > div.news_wrap.api_ani_send > div > a')
a['href']
a.text
업무자동화 엑셀다루기
라이브러리 설치
!pip install openpyxl
from openpyxl import Workbook
wb= Workbook()
sheet = wb.activesheet['A1'] = '안녕하세요!'
wb.save("샘플파일.xlsx")
wb.close()-> 이러면 샘플파일이 만들어지면서 A1시트에 안녕하세요! 가 적혀있다.
여러 데이터를 써보면
from openpyxl import Workbook
wb = Workbook()
sheet = wb.activerow = [1,'사과',300]
sheet.append(row)
sheet.append(row)
sheet.append(row)
sheet.append(row)wb.save("샘플파일.xlsx")
wb.close()
엑셀을 읽어올려면
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']sheet['A1'].value
전체 데이터를 읽고 싶다면, 아래 처럼 읽을 수도 있겠죠!
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']for row in sheet.rows:
print(row[0].value, row[1].value, row[2].value)
첫 줄을 빼고 읽고 싶다면?
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')sheet = wb['Sheet']
new_rows = list(sheet.rows)[1:]for row in new_rows:
print(row[0].value, row[1].value, row[2].value)
500원 보다 작은 항목만 출력하고 싶다면?
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']new_rows = list(sheet.rows)[1:]
for row in new_rows:
if row[2].value < 500:
print(row[0].value, row[1].value, row[2].value)
스크래핑 결과를 엑셀에 넣을 수도 있다. (sheet.append(row)활용)
import requests
from bs4 import BeautifulSoupfrom openpyxl import Workbook
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']]
sheet.append(row)wb.save("샘플파일.xlsx")
wb.close()
이것을 함수로 만들면
def make_news_excel(keyword):
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']][스파르타코딩클럽] 1주차 : 킹 받을 땐 파이썬 – 파이썬기초, 업무자동화 13
sheet.append(row)wb.save(f"{keyword}.xlsx")
wb.close()
반복문으로 여러파일을 만들어보면
keywords = ['삼성전자','LG전자','현대자동차','SK']
for keyword in keywords:
make_news_excel(keyword)
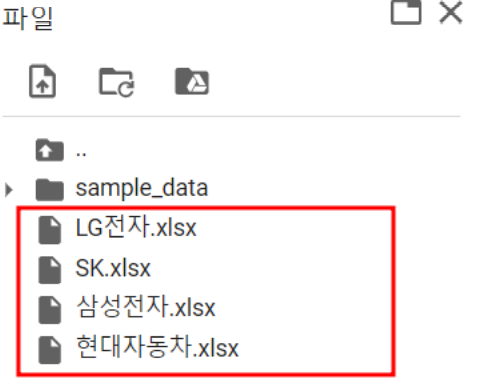
여기 엑셀파일에 날짜를 달아보면
from datetime import datetime
datetime.today().strftime("%Y-%m-%d")
def make_news_excel(keyword):
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']]
sheet.append(row)today = datetime.today().strftime("%Y-%m-%d")
wb.save(f"{today}_{keyword}.xlsx")
wb.close()
특정 폴더에 쌓이게 하기
def make_news_excel(keyword):
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']]
sheet.append(row)today = datetime.today().strftime("%Y-%m-%d")
wb.save(f"news/{today}_{keyword}.xlsx")
wb.close()

업무자동화 파일 다운로드

압축하기
!zip -r /content/files.zip /content/news
업무자동화 파일명 바꾸기
먼저 파일명 체크
import os
path = '/content/news'
names = os.listdir(path)for name in files:
print(name)
변경할 파일명 테스트
name = '2022-04-04_삼성SDI.xlsx'
name.split('.')[0] + '(뉴스).xlsx'
파일명 변경
import os
path = '/content/news'
names = os.listdir(path)for name in names:
new_file = name.split('.')[0] + '(뉴스).xlsx'
os.rename(path+'/'+name,path+'/'+new_file)
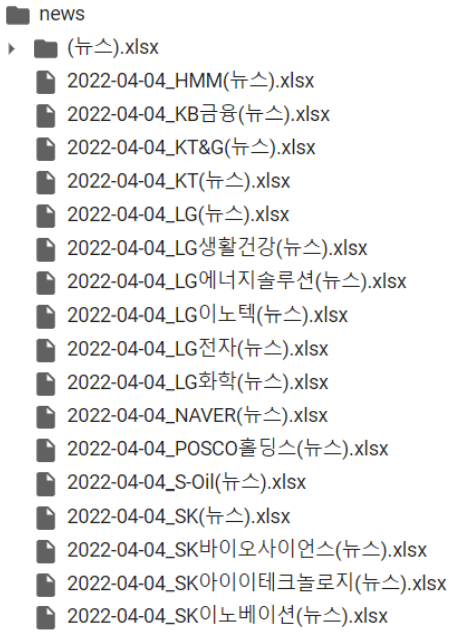
업무자동화 이미지 다운로드
import urllib.request
url = '여기에 URL을 입력하기'
urllib.request.urlretrieve(url, "test.jpg")
import urllib.request
url = 'https://ssl.pstatic.net/imgfinance/chart/item/area/year3/005930.png'
urllib.request.urlretrieve(url, "samsung.jpg")
{kind=link}
