1주차
파이썬이란? 가장 직관적인 문법을 가진 언어다.
Google Colab을 사용할 것이다.
주의
Google Colab은 무료로 제공되는 만큼 사용제한이 있다. 연속 연결 시간 최대 90분, 하루 이용 제한 12시간
파이썬 기초 1
1) 변수와 기본연산
변수는 마음대로 이름을 지을 수 있다.
기본연산은
a = 3 -> 3을 a에 넣는다
b = a -> a를 b에 넣는다
a = a + 1 -> a+1을 다시 a에 넣는다
2) 리스트, 딕셔너리 형
리스트는 순서가 중요하다
a_list = ['사과','배','감','수박']
a_list[0]
a_list.append('귤')
a_list[4]딕셔너리는 {key : value}가 중요하다
a_dict = {'name':'bob','age':21}
a_dict['age']
a_dict['height'] = 178
a_dict
3) Dictionary 형과 List 형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}]
people[0]['name']의 값은? 'bob'
people[1]['name']의 값은? 'carry'
person = {'name':'john','age':7}
people.append(person)people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}]
people[2]['name']의 값은? 'john'
4) 함수
def sum(a,b):
return a+bdef mul(a,b):
return a*bresult = sum(1,2) + mul(10,10)
result라는 변수의 값은?
파이썬 기초 2
1) 조건문
if age > 20:
print('성인입니다') -> 조건이 참이면 성인입니다를 출력
else:
print('청소년이에요') -> 조건이 거짓이면 청소년이에요를 출력is_adult(30)
2) 반복문
ages = [20,30,15,5,10]
for age in ages:
print(age)
for age in ages:
if age > 20:
print('성인입니다')
else:
print('청소년이에요')
3) 조건문 + 함수 + 반복문
def check_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년이에요')ages = [20,30,15,5,10]
for age in ages:
check_adult(age)
웹스크래핑연습
먼저 라이브러리 설치
!pip install bs4 requests
크롤링 기본코드 가져오기
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
a = soup.select_one('#sp_nws1 > div.news_wrap.api_ani_send > div > a')
a['href']
a.text
업무자동화 엑셀다루기
라이브러리 설치
!pip install openpyxl
from openpyxl import Workbook
wb= Workbook()
sheet = wb.activesheet['A1'] = '안녕하세요!'
wb.save("샘플파일.xlsx")
wb.close()-> 이러면 샘플파일이 만들어지면서 A1시트에 안녕하세요! 가 적혀있다.
여러 데이터를 써보면
from openpyxl import Workbook
wb = Workbook()
sheet = wb.activerow = [1,'사과',300]
sheet.append(row)
sheet.append(row)
sheet.append(row)
sheet.append(row)wb.save("샘플파일.xlsx")
wb.close()
엑셀을 읽어올려면
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']sheet['A1'].value
전체 데이터를 읽고 싶다면, 아래 처럼 읽을 수도 있겠죠!
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']for row in sheet.rows:
print(row[0].value, row[1].value, row[2].value)
첫 줄을 빼고 읽고 싶다면?
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')sheet = wb['Sheet']
new_rows = list(sheet.rows)[1:]for row in new_rows:
print(row[0].value, row[1].value, row[2].value)
500원 보다 작은 항목만 출력하고 싶다면?
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']new_rows = list(sheet.rows)[1:]
for row in new_rows:
if row[2].value < 500:
print(row[0].value, row[1].value, row[2].value)
스크래핑 결과를 엑셀에 넣을 수도 있다. (sheet.append(row)활용)
import requests
from bs4 import BeautifulSoupfrom openpyxl import Workbook
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']]
sheet.append(row)wb.save("샘플파일.xlsx")
wb.close()
이것을 함수로 만들면
def make_news_excel(keyword):
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']][스파르타코딩클럽] 1주차 : 킹 받을 땐 파이썬 – 파이썬기초, 업무자동화 13
sheet.append(row)wb.save(f"{keyword}.xlsx")
wb.close()
반복문으로 여러파일을 만들어보면
keywords = ['삼성전자','LG전자','현대자동차','SK']
for keyword in keywords:
make_news_excel(keyword)
여기 엑셀파일에 날짜를 달아보면
from datetime import datetime
datetime.today().strftime("%Y-%m-%d")
def make_news_excel(keyword):
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']]
sheet.append(row)today = datetime.today().strftime("%Y-%m-%d")
wb.save(f"{today}_{keyword}.xlsx")
wb.close()
특정 폴더에 쌓이게 하기
def make_news_excel(keyword):
wb = Workbook()
sheet = wb.activeheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')for li in lis:
a = li.select_one('a.news_tit')
row = [a.text, a['href']]
sheet.append(row)today = datetime.today().strftime("%Y-%m-%d")
wb.save(f"news/{today}_{keyword}.xlsx")
wb.close()

업무자동화 파일 다운로드

압축하기
!zip -r /content/files.zip /content/news
업무자동화 파일명 바꾸기
먼저 파일명 체크
import os
path = '/content/news'
names = os.listdir(path)for name in files:
print(name)
변경할 파일명 테스트
name = '2022-04-04_삼성SDI.xlsx'
name.split('.')[0] + '(뉴스).xlsx'
파일명 변경
import os
path = '/content/news'
names = os.listdir(path)for name in names:
new_file = name.split('.')[0] + '(뉴스).xlsx'
os.rename(path+'/'+name,path+'/'+new_file)
업무자동화 이미지 다운로드
import urllib.request
url = '여기에 URL을 입력하기'
urllib.request.urlretrieve(url, "test.jpg")
import urllib.request
url = 'https://ssl.pstatic.net/imgfinance/chart/item/area/year3/005930.png'
urllib.request.urlretrieve(url, "samsung.jpg")
2주차
- pandas와 numpy 설치 후 import
!pip install pandas numpy
import pandas as pd
import numpy as np
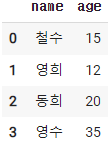
- DataFrame 기초 만들기
data = {
'name':['철수','영희','동희','영수'],
'age' : [15,12,20,35]
}
df = pd.DataFrame(data)
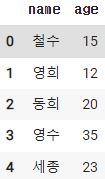
2-1. row 추가하기
doc = {
'name' : '세종',
'age' : 23
}
df.append(doc, ignore_index=True)
※ignore_index란 인덱스를 만들지 않고 그냥 추가로 붙이겠다는 뜻이다
2-2. column 추가하기
df['city'] = ['서울','부산','서울','부산','부산']
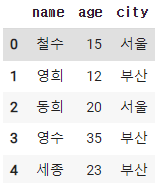
2-3. 특정 column 만 출력하기(대괄호 2번하기)
df[['name','city']]
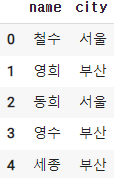
2-4. 특정 조건으로 출력하기 (나이 20 미만)
cond = df['age'] < 20
df[cond]
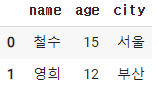
2-5. 마지막줄의 정보
1) df.iloc[-1]
2) df.iloc[-1,0]

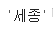
2-6. 정렬
1)나이순으로 내림차순
df.sort_values(by='age', ascending=False)
2) 첫번째의 나이를 구해라
df.sort_values(by='age',ascending=False).iloc[0,1]

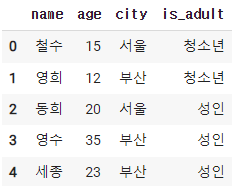
2-7. 조건추가하기
1) 20미만 청소년 나머지 성인
df['is_adult']= np.where(df['age'] < 20, '청소년','성인')
2-8. 계산하기
df['age'].describe()

퀴즈
서울에서 사는 사람들 나이의 평균 구하기
1) df[df['city']=='서울']
2) df[df['city']=='서울']['age']
3)df[df['city']=='서울']['age'].mean()


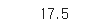
-
엑셀 import 하기
1) 파일에 종목데이터 추가
2) df=pd.read_excel('종목데이터.xlsx')
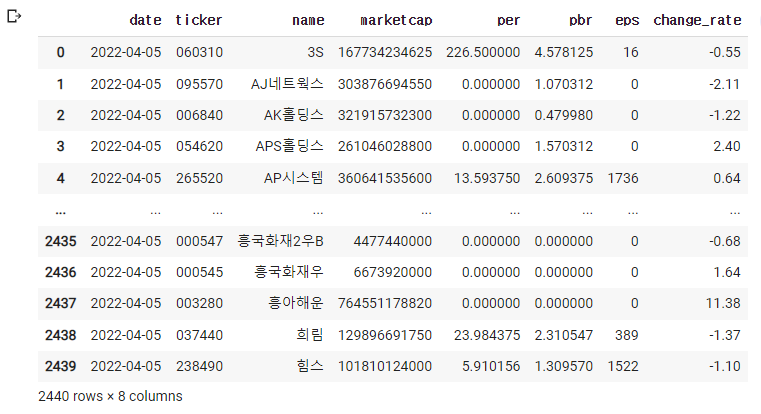
3) 앞에 5개만 가져오기(기본이 5개)
df=pd.read_excel('종목데이터.xlsx')
df.head()
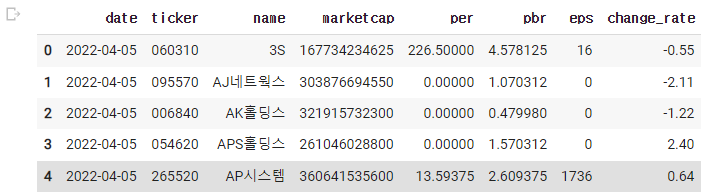
4) 소수점 둘째자리 (한번만 실행하면 됨)
pd.options.display.float_format = '{:.2f}'.format
실행 후 3)것을 실행해보면 된다.
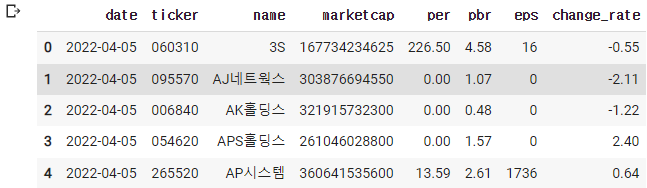
-
pandas 실전
1) 어제 오른 종목들만 골라보기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df[cond]
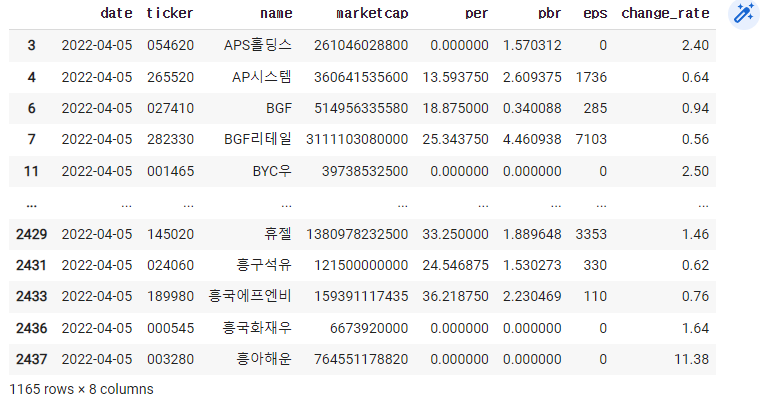
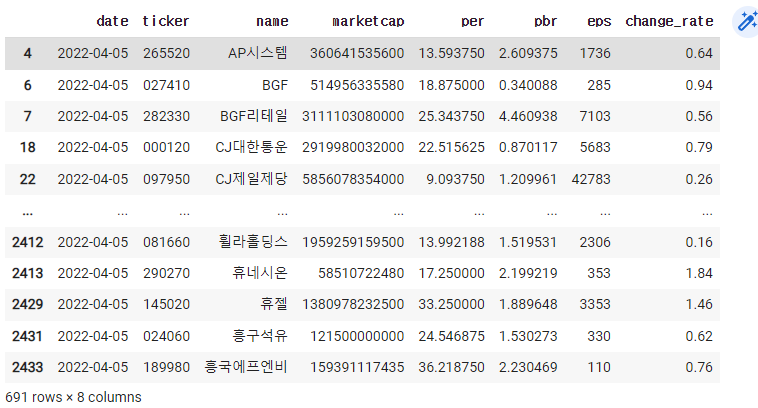
2) per가 0인 종목들을 제거하기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df
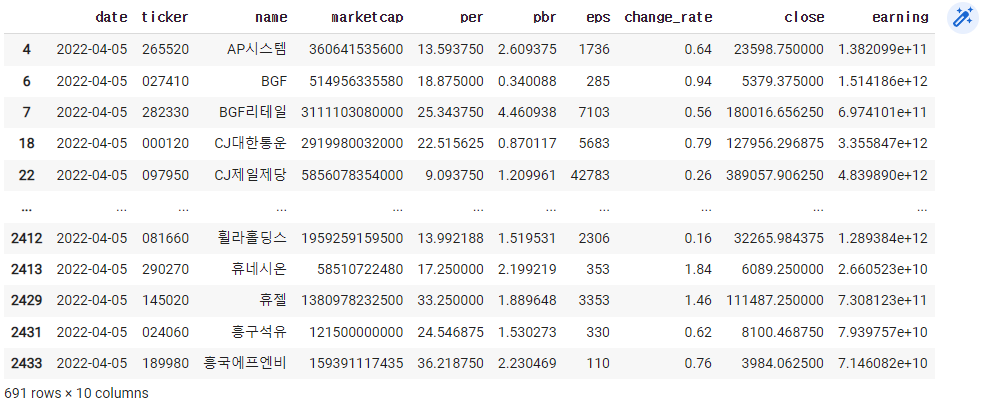
3) 순이익, 종가를 추가하기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df['close'] = df['per'] df['eps']
df['earning'] = df['marketcap'] / df['pbr']
df
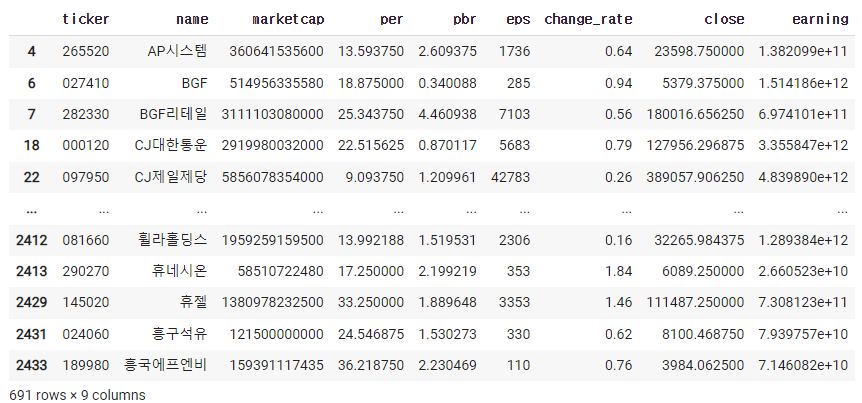
4) date 컬럼을 없애기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df['close'] = df['per'] df['eps']
df['earning'] = df['marketcap'] / df['pbr']
del df['date']
df
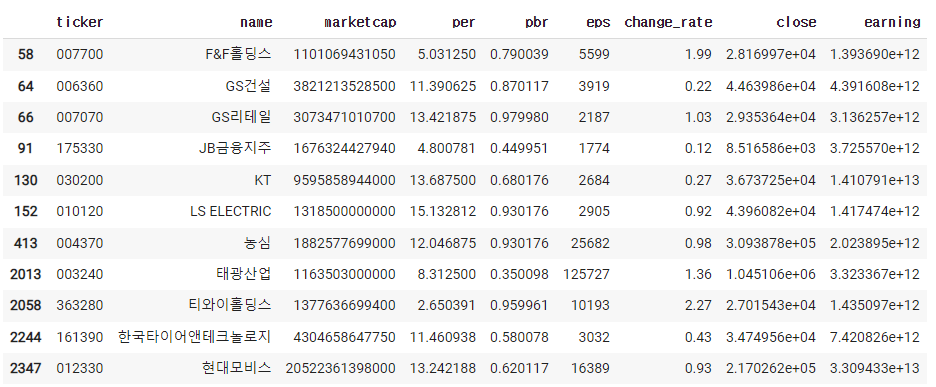
5) pbr < 1 & 시총 1조 이상 & per < 20 을 추려보기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df['close'] = df['per'] * df['eps']
df['earning'] = df['marketcap'] / df['pbr']
del df['date']
cond = (df['pbr'] < 1) & (df['marketcap'] > 1000000000000) & (df['per'] < 20)
df = df[cond]
df
6) 정렬해서 보기
df.sort_values(by='marketcap',ascending = False)
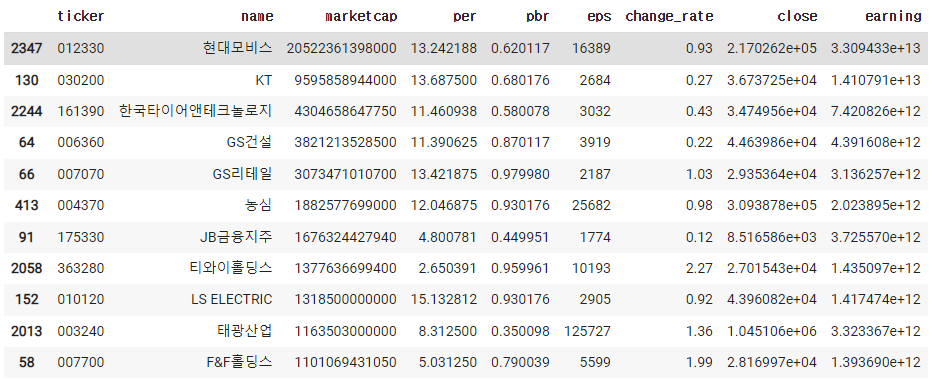
7) 숫자들의 정보만 보기
df.describe()
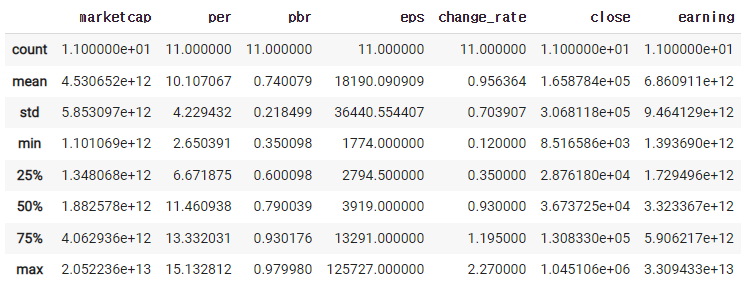
-
해외주식 다루기 - yfinance
1)!pip install yfinance
2)import pandas as pd
import numpy as np
import yfinance as yf
3)company = yf.Ticker('TSLA')
company
3)-1 company.info
3)의 밑줄에 .info넣어보면 정보가 나온다
※원래 홈페이지의 용어와 코드에서 나온 값의 이름이 다를수도 있다.

5-2.
1) 기본 정보 얻기 (예 회사명, 산업, 시가총액, 매출)
(위의 .info에서 ''안의 내용 복사 붙여넣기 하자)
name = company.info['shortName']
industry = company.info['industry']
marketcap = company.info['marketCap']
revenue = company.info['totalRevenue']
print(name, industry, marketcap, revenue)
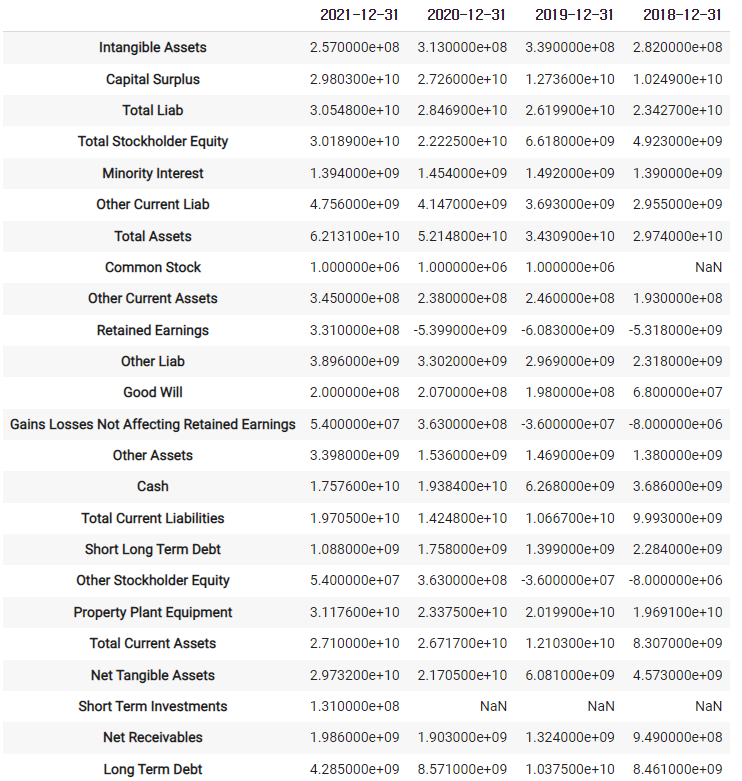
2) 재무제표에서 3년치 데이터 얻기 (대차대조표, 현금흐름표, 기업 실적)
2)-1 company.balance_sheet
2)-2 특정 목록만 보기
company.balance_sheet.loc[['Cash']]
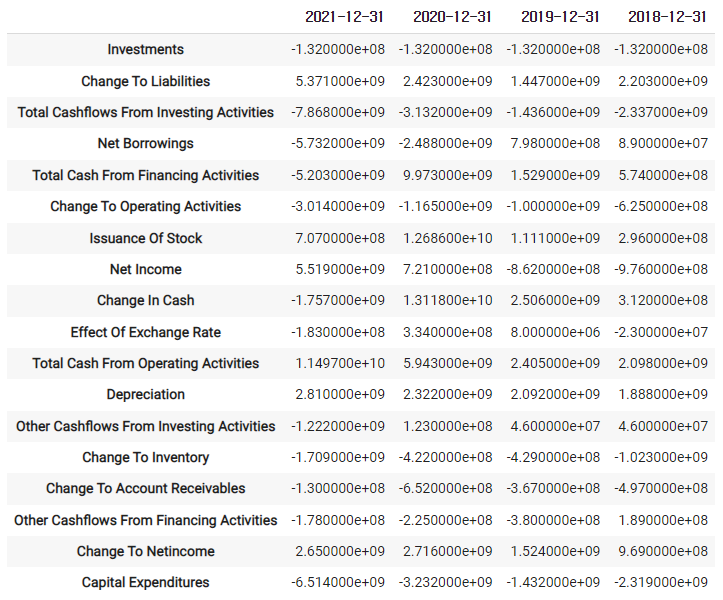
2)-3 company.cashflow
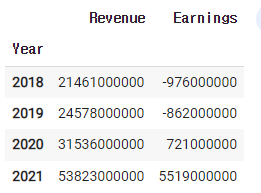
2)-4 매출하고 이익만 보여주기
company.earnings
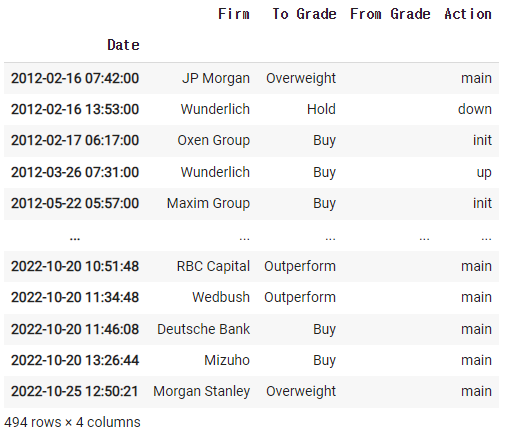
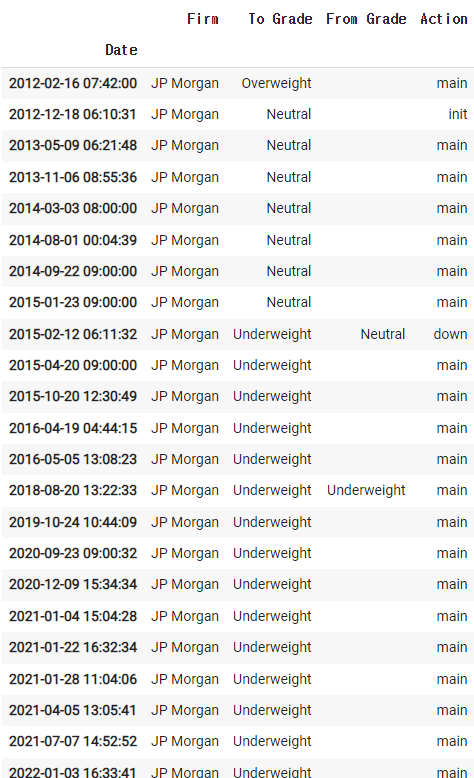
2)-5 company.recommendations
2)-6 JP Morgan의 자료만 가져오기
df = company.recommendations
cond = df['Firm'] == 'JP Morgan'
df[cond]
2)-7 company.news
news = company.news
news[0]
news = company.news
news[0]['title']




- 분석하기(1) : 전략 세우기, 데이터 모으기
1)-1 company = yf.Ticker('TSLA')
code = 'TSLA'
name = company.info['shortName']
industry = company.info['industry']
marketcap = company.info['marketCap']
summary = company.info['longBusinessSummary']
currentprice = company.info['currentPrice']
targetprice = company.info['targetMeanPrice']
per = company.info['trailingPE']
eps = company.info['trailingEps']
pbr = company.info['priceToBook']
print(code,name, company,industry,marketcap,summary,currentprice,targetprice,per,eps,pbr)
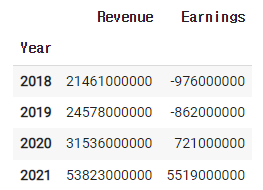
1)-2 company.earnings
1)-3 rev2021 = company.earnings.iloc[-1,0]
rev2021
1)-4 rev2021 = company.earnings.iloc[-1,0]
rev2020 = company.earnings.iloc[-2,0]
rev2019 = company.earnings.iloc[-3,0]
ear2021 = company.earnings.iloc[-1,1]
ear2020 = company.earnings.iloc[-2,1]
ear2019 = company.earnings.iloc[-3,1]

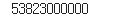
조금 복습하기
2)-1 빈 데이터프레임만들기
df = pd.DataFrame()
df

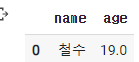
2)-2 df = pd.DataFrame()
doc = {
'name' : '철수',
'age' : 19
}
df.append(doc, ignore_index = True)
2)-3 ※doc 안에 들어갈때 ,꼭 넣기!!
def add_company(code):
company = yf.Ticker(code)
name = company.info['shortName']
industry = company.info['industry']
marketcap = company.info['marketCap']
summary = company.info['longBusinessSummary']
currentprice = company.info['currentPrice']
targetprice = company.info['targetMeanPrice']
per = company.info['trailingPE']
eps = company.info['trailingEps']
pbr = company.info['priceToBook']
rev2021 = company.earnings.iloc[-1,0]
rev2020 = company.earnings.iloc[-2,0]
rev2019 = company.earnings.iloc[-3,0]
ear2021 = company.earnings.iloc[-1,1]
ear2020 = company.earnings.iloc[-2,1]
ear2019 = company.earnings.iloc[-3,1]
doc = {
'name' : name,
'industry' : industry,
'marketcap' : marketcap,
'summary' : summary,
'currentprice' : currentprice,
'targetprice' : targetprice,
'per' : per,
'eps' : eps,
'pbr' : pbr,
'rev2021' : rev2021,
'rev2020' : rev2020,
'rev2019' : rev2019,
'ear2021' : ear2021,
'ear2020' : ear2020,
'ear2019' : ear2019
}
return doc
실행한번 시킨 후
2)-4 df = pd.DataFrame()
row = add_company('TSLA')
df.append(row, ignore_index = True)

2)-5 소수점둘째자리
새로 코드만들기에서 이것만 넣고 실행(후 삭제 해도됨)
pd.options.display.float_format = '{:.2f}'.format
그 후 2)-4 다시 실행시키면 깔끔하게 보인다

2)-6 for문으로 돌려보기
df = pd.DataFrame()
codes = ['AAPL','ABNB','BIDU','FB','GOOG','MSFT','TSLA','PYPL','NFLX','NVDA']
for code in codes:
print(code)
row = add_company(code)
df = df.append(row, ignore_index = True)
df
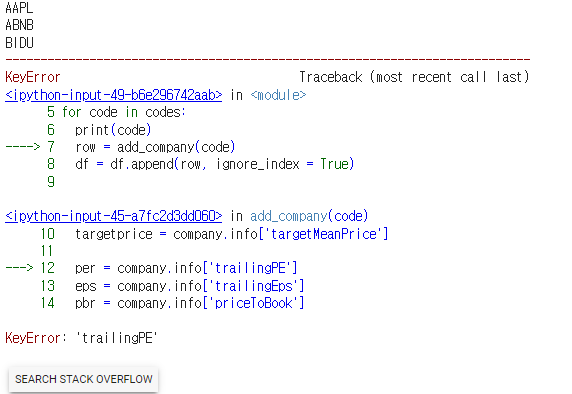
이러면 에러가 뜰것이다.
실제로 yahoofinance에 검색해보면 자료가 없을때가 있다. 이렇게 에러가 뜨면
☆ : try: ...... except: 를 넣어보자
(try해서 없으면 except의 문장을 넣어라)
df = pd.DataFrame()
codes = ['AAPL','ABNB','BIDU','FB','GOOG','MSFT','TSLA','PYPL','NFLX','NVDA']
for code in codes:
print(code)
try:
row = add_company(code)
df = df.append(row, ignore_index = True)
except:
print(f'error - {code}')
df
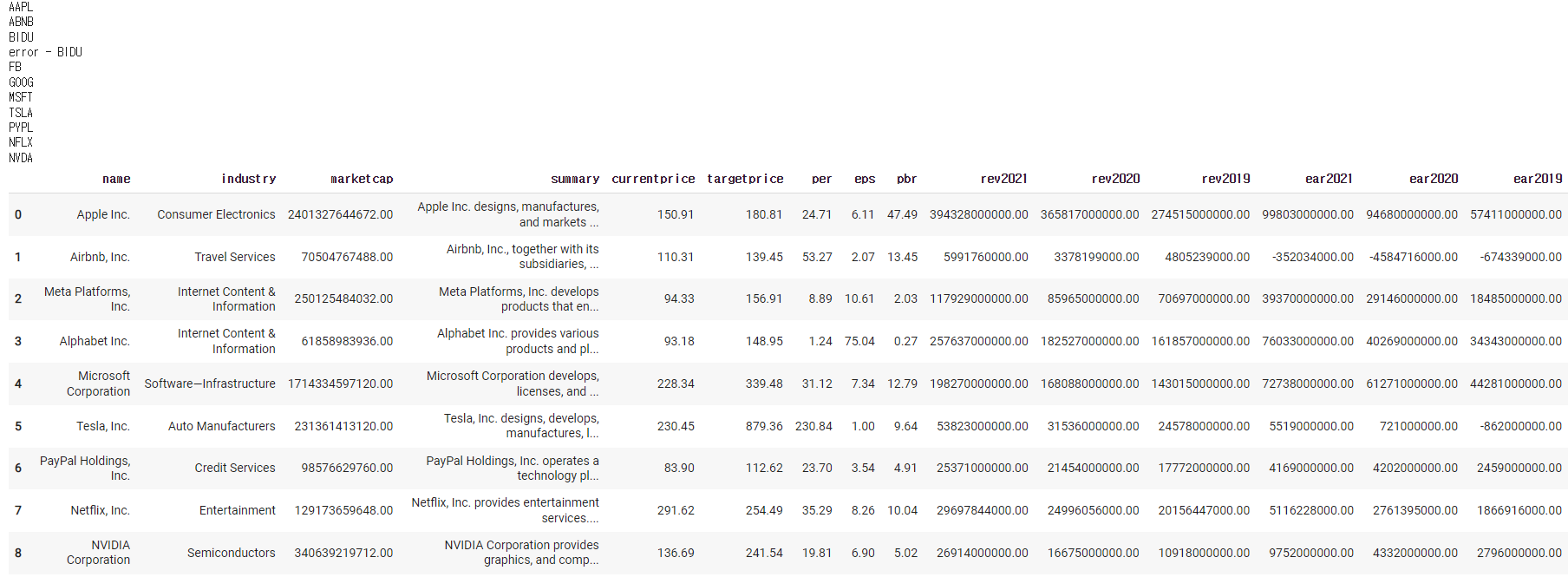
- 분석하기(2) : 분석하기
1)-1 먼저 (head() = 위에서 5개만 보기)
df.head()

1)-2
df.sort_values(by='eps',ascending=False)
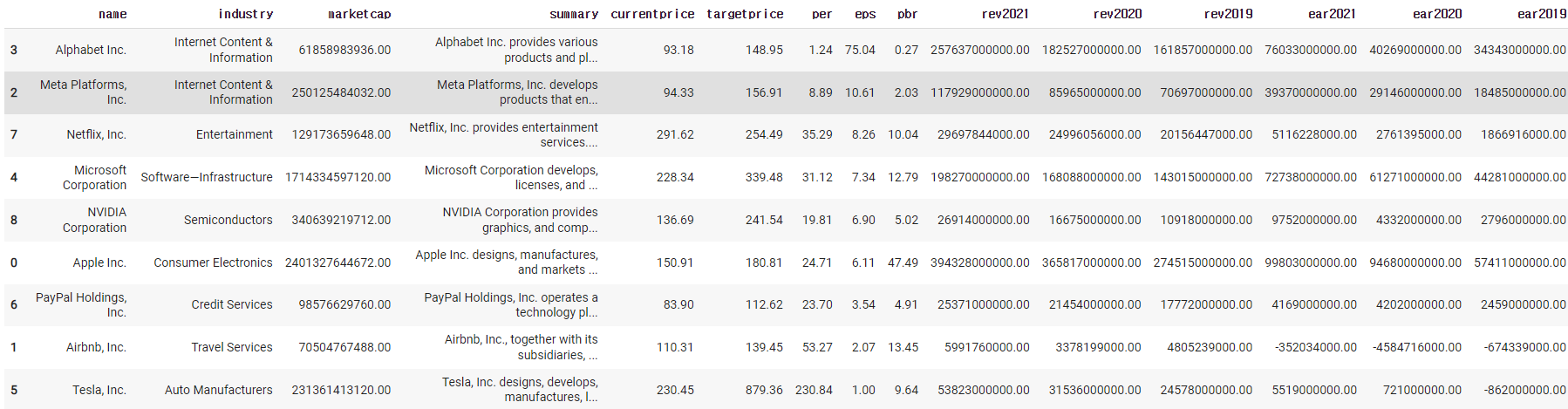
1)-3
df.sort_values(by='eps',ascending=False).head()

2) 특정 per 이하만 보기(+내림차순)
cond = df['per'] > 30
df[cond].sort_values(by='per', ascending = False)

3)-1 현재가격 - 1년 후 가격의 비율 차이가 큰 종목들을 추려내기
일단 보기좋게 만들기
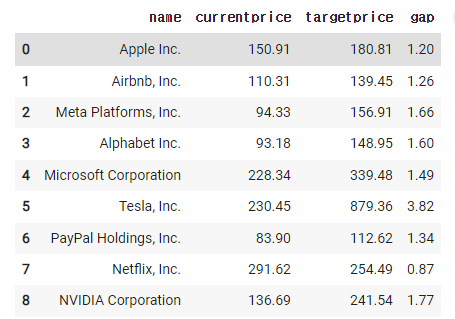
new_df = df[['name','currentprice','targetprice']]
new_df
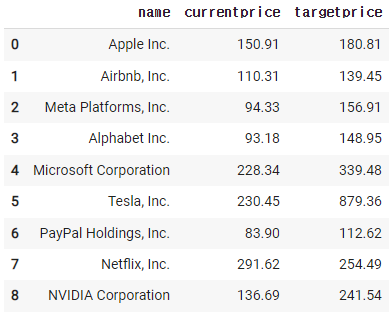
3)-2
new_df = df[['name','currentprice','targetprice']]
new_df['gap'] = new_df['targetprice'] / new_df['currentprice']
new_df
그냥 이렇게 만들면 원본이 훼손된다.
그러므로 1줄을
new_df = df[['name','currentprice','targetprice']].copy()
만들면 된다.
대개의 경우 맨 윗줄에 .copy()를 안한경우가 많다.
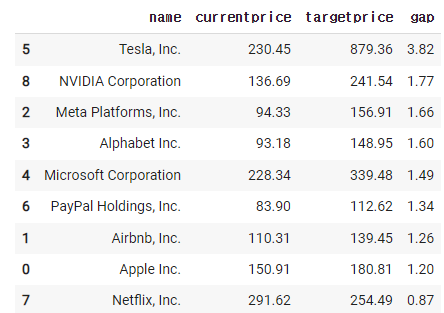
그 후 내림차순으로 정렬
new_df = df[['name','currentprice','targetprice']].copy()
new_df['gap'] = new_df['targetprice'] / new_df['currentprice']
new_df.sort_values(by='gap', ascending = False)
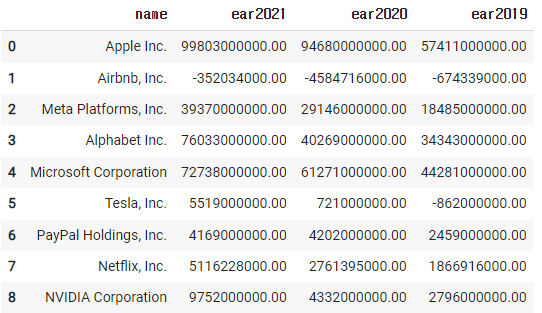
4)-1 3년 연속 순수익이 오른 기업을 표기하기
일단 필요한 자료만 뽑아보자
new_df = df[['name','ear2021','ear2020','ear2019']].copy()
new_df
4)-2
new_df = df[['name','ear2021','ear2020','ear2019']].copy()
cond = (new_df['ear2021'] > new_df['ear2020']) & (new_df['ear2020'] > new_df['ear2019'])
new_df[cond]
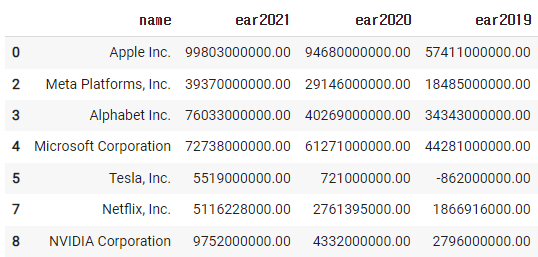
4)-3 이 자료를 표기하기
new_df = df[['name','ear2021','ear2020','ear2019']].copy()
cond = (new_df['ear2021'] > new_df['ear2020']) & (new_df['ear2020'] > new_df['ear2019'])
new_df['is_target'] = np.where(cond, 'O','X')
new_df
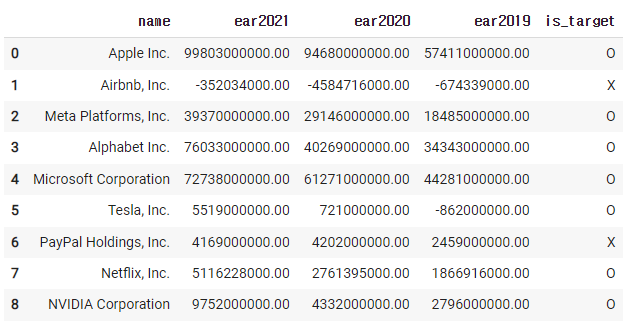
3주차
Dart OpenAPI
1) 먼저 키 발급받기
API란? - 서버에 접근하는 ‘창구’와 같은 것
https://opendart.fss.or.kr/uat/uia/egovLoginUsr.do
2) 라이브러리 설치
!pip install dart-fss
인터넷창에 'dart fss 라이브러리' 검색하기
이 홈페이지가 라이브러리에서 제공하는 공식문서다.

3)
dart_fss를 사용하겠다 판다스도 사용하겠다 전체 회사리스트를 받아서 출력해주겠다 - 는 내용이다.

4)
저 부분의 코드를 복사해서 colab에 넣어준다.

5) 위 사진의 아랫부분만 따로 코드로 분류하면 절차가 간단해진다.
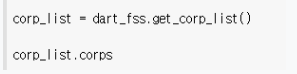

양이 많고 반복되는 형태이므로 0번째꺼만 불러와도 된다.(확인용)
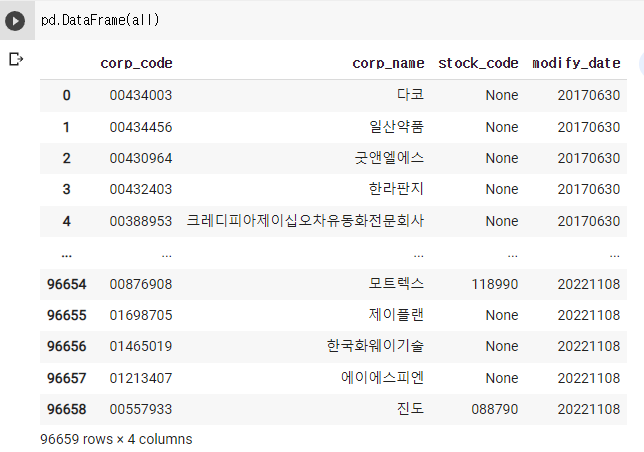
그러면 데이터프레임으로 만들어주자
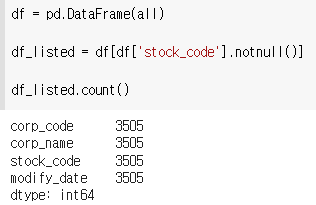
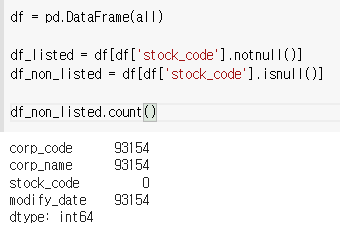
목록중 stock_code가 있는 애들과 없는 애들을 구분해보자
1) stock_code가 있는 회사
여기서 없는애들은 아니다 해서 != 'null' 이렇게 쓰면 안먹힌다.

2) stock_code가 없는 회사
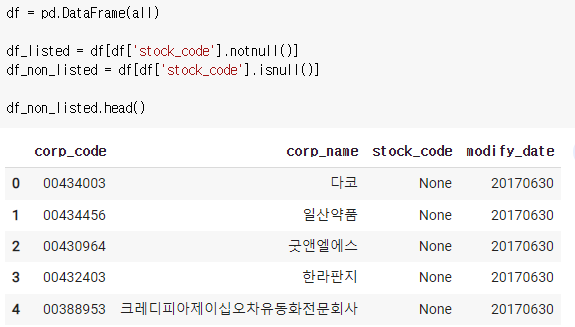
6) 엑셀파일로 만들어보기

1. dart API 사용해보기
1) 회사 코드(corp_code) 찾아오기
먼저
로 어떻게 생겼나 보고
회사 이름으로 목록을 불러온 후에 iloc로 특정 값을 불러온다.



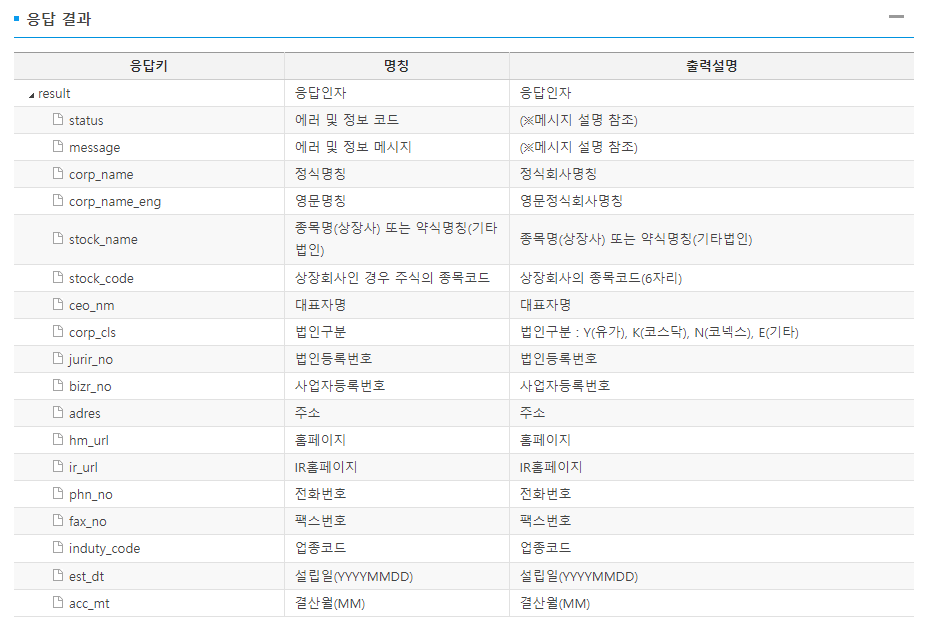
2) 사업보고서 주요정보


[참고사항]
우리가 모르는 것들은
개발가이드 -> 공시정보 -> 기업개황
모르는 것을 맞춰보면 된다.
3) 미등기임원 보수 총액
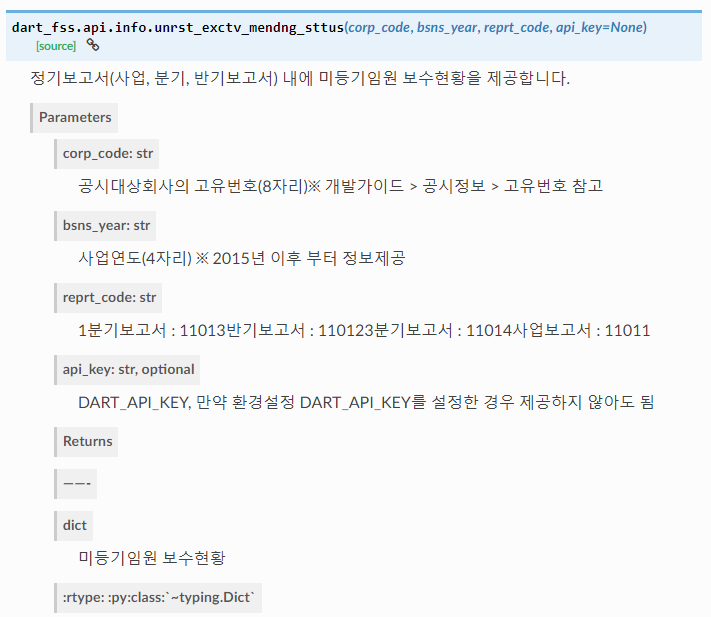
list안에 들어가있으므로 pandas로 표로 만들수있다.
여기서 data = 뒤의 내용만 갈이끼우면 깔끔하게 볼 수 있다.


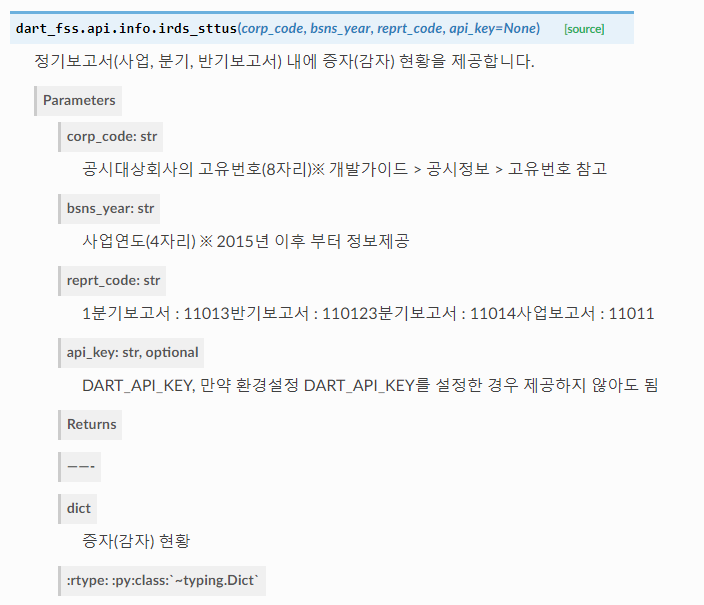
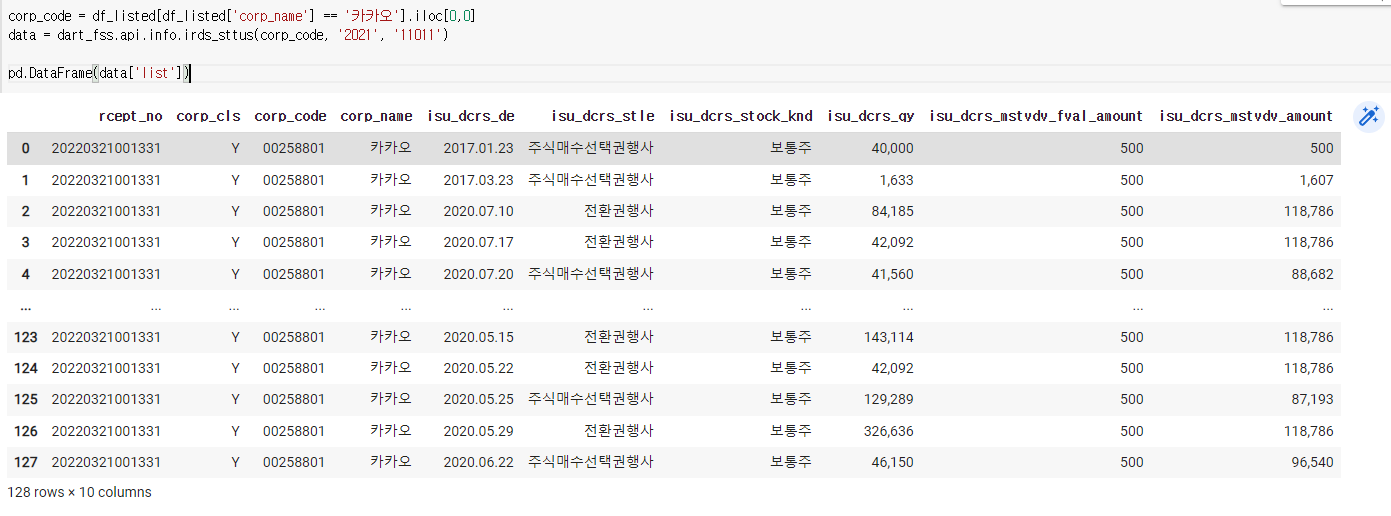
4) 증자(감자)현황
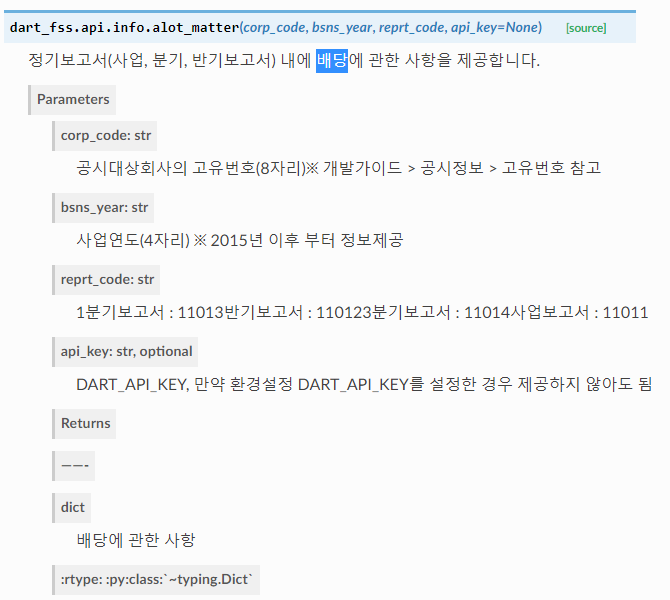
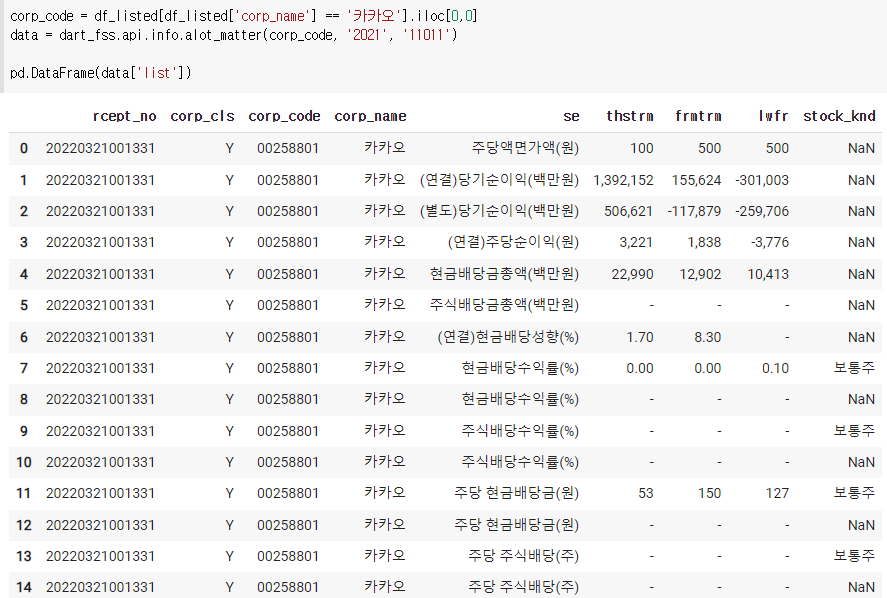
5) 배당 현황
6) 최대주주 현황
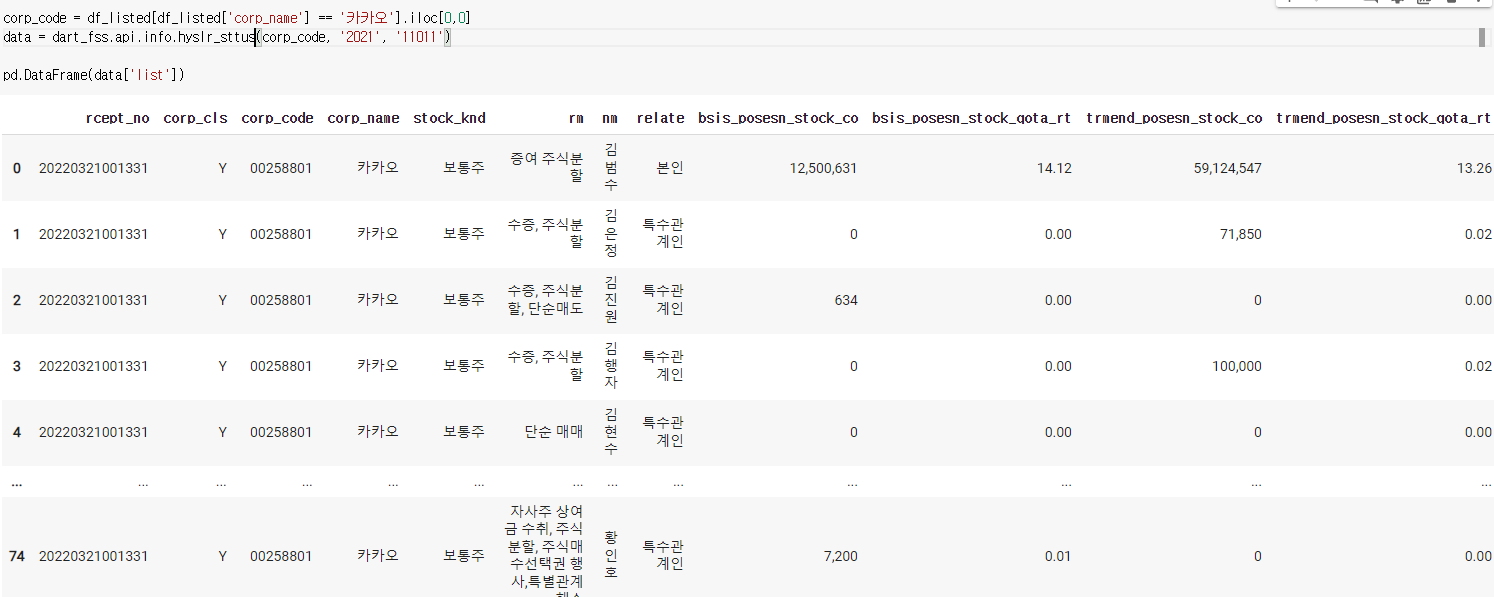
-나중에 볼때는 필요한 열만 가져와서 사용하면 된다.
7) 직원 현황

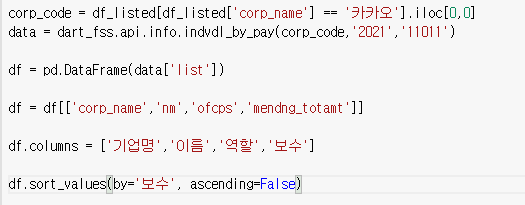
8) 연봉 top 5
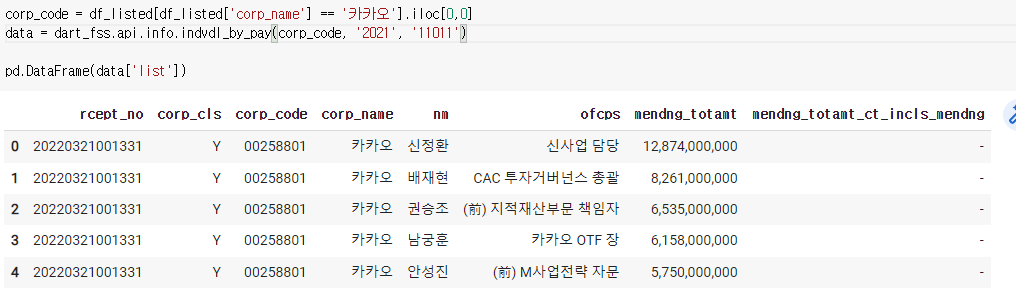
9) 상장기업 재무정보
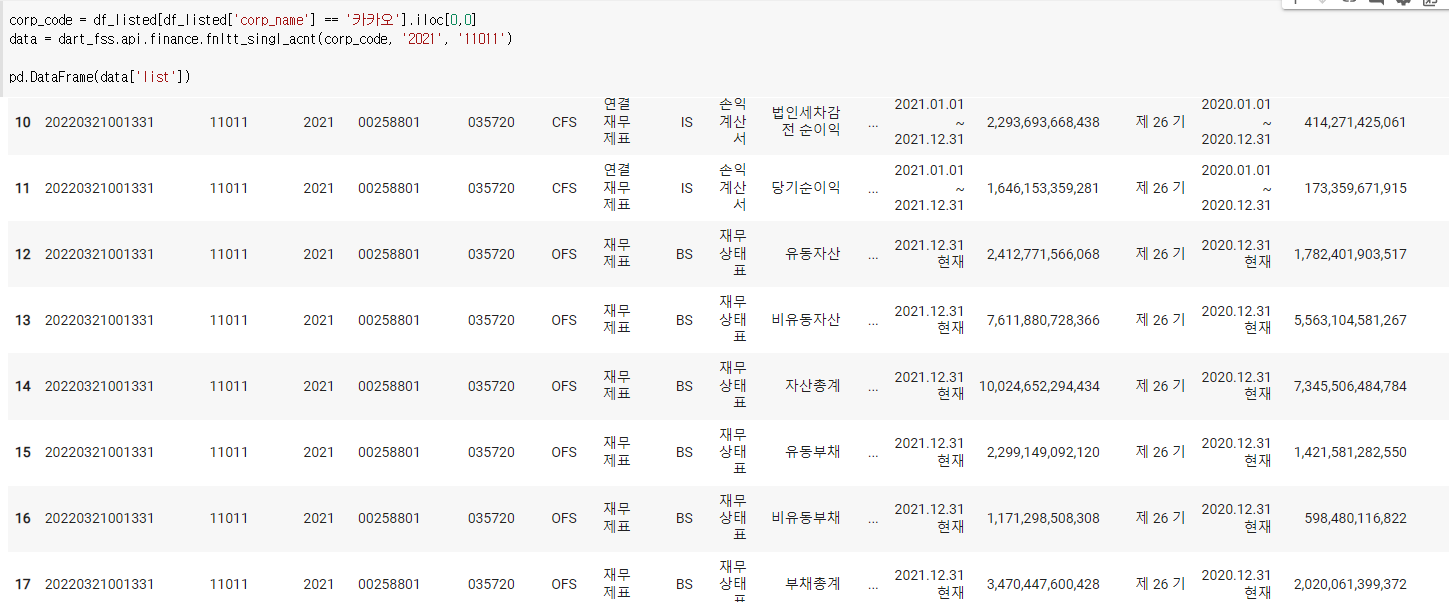
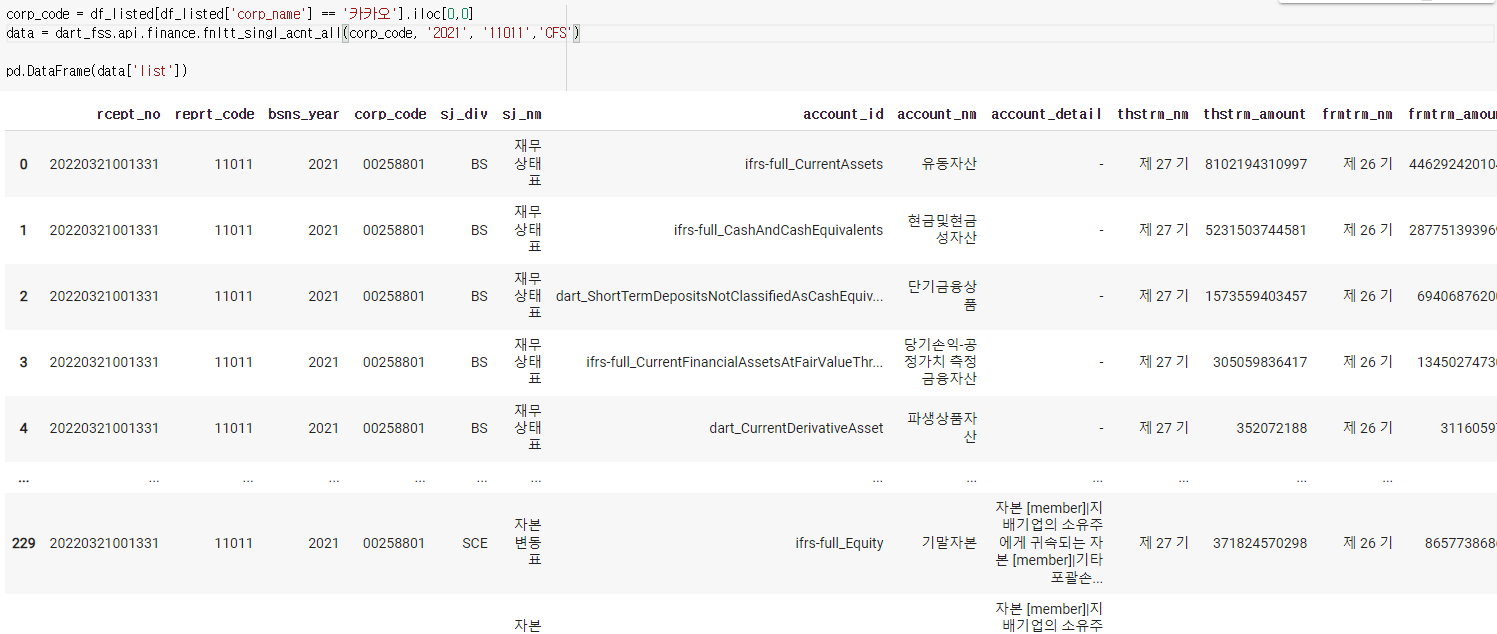
10) 상장기업 모든계정과목보기
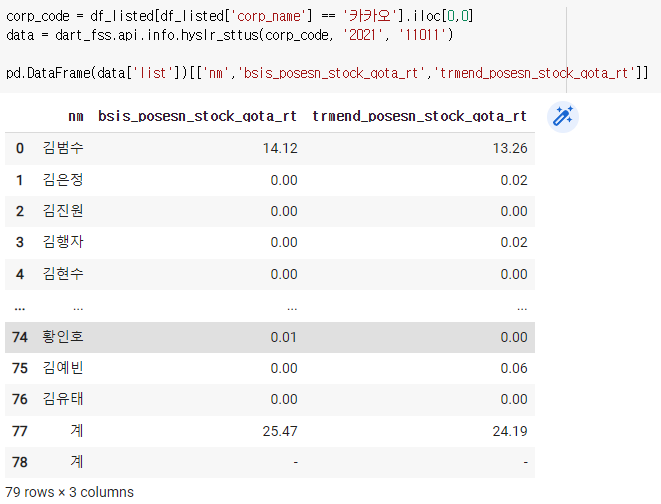
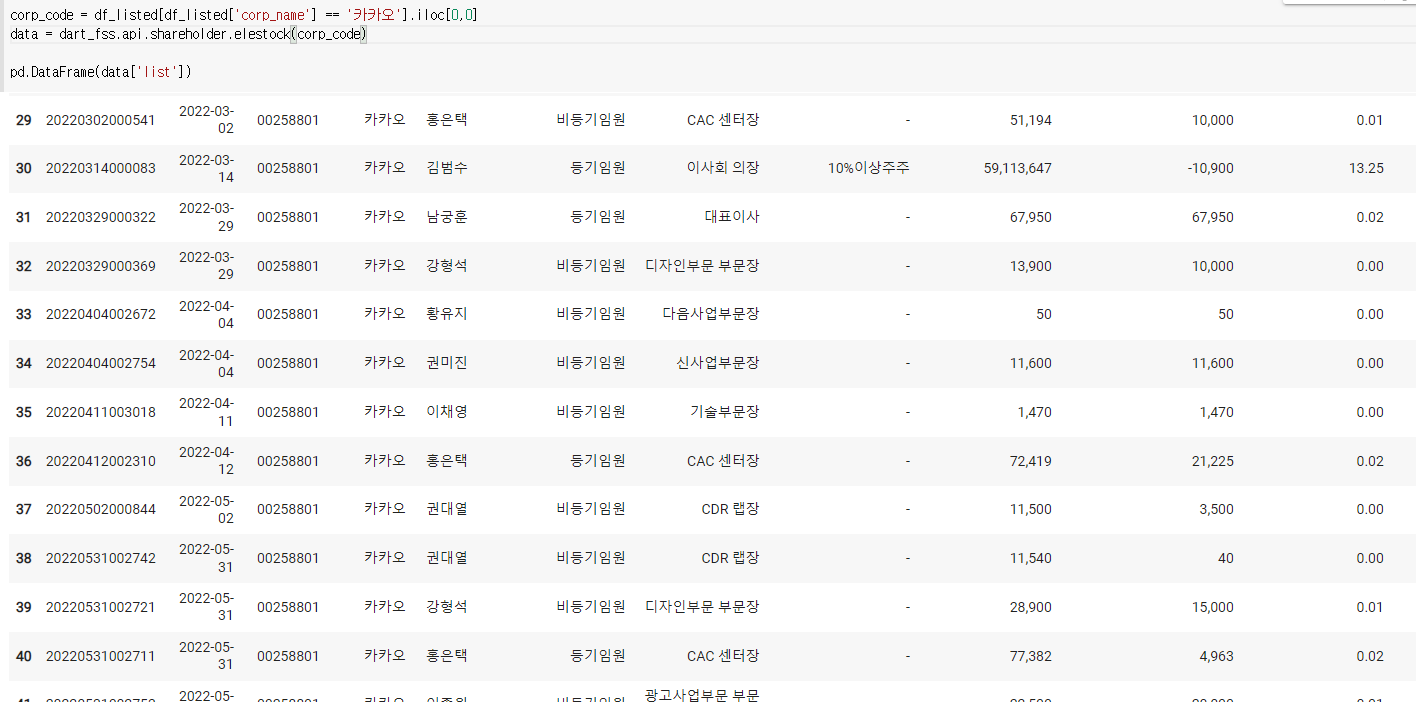
11) 지분공시 종합정보 내에 임원, 주요주주 소유 보고
-이중에서 한사람것만 보고싶으면?
2. dart API 활용해보기
- 각 회사마다 연봉상위 5명 표시하기
1) 한 회사
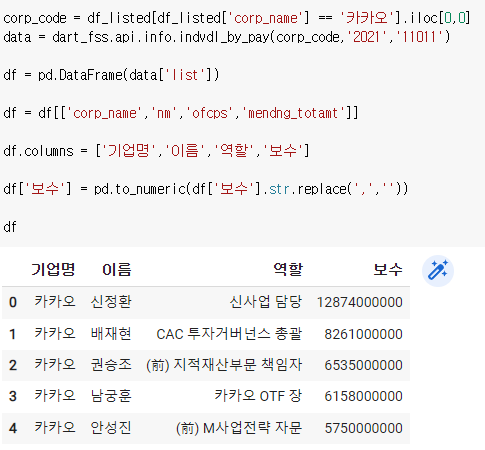
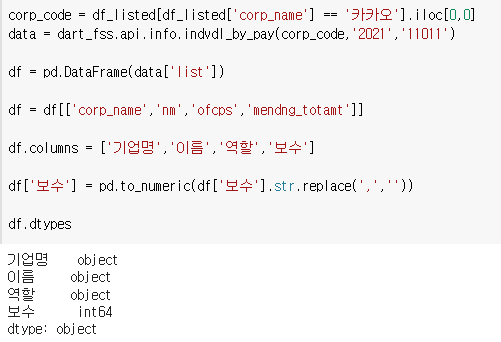
2) 보수 숫자열로 바꾸기
그냥 보기에는 숫자지만 문자열로 되어있다.
그냥 보면 모르기때문에
이렇게 해주면 된다.
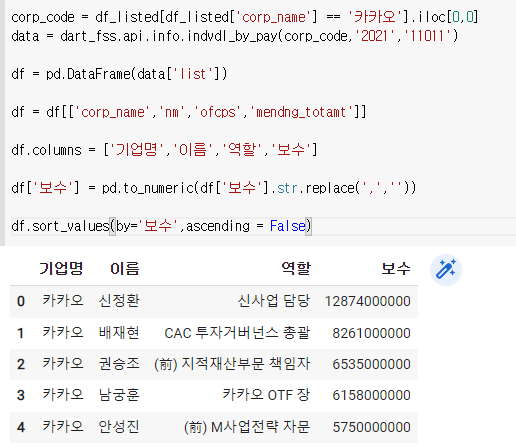
3) 여러회사에 적용시키기
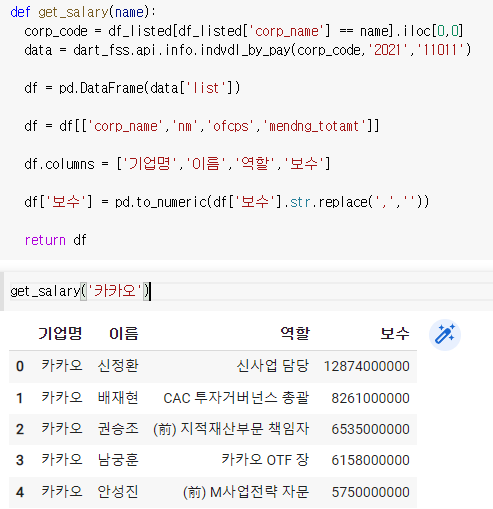
여기에서


위 사진대로 하면 계속 출력해야되는 시간이 걸리니 따로 만들어주면 편리하다
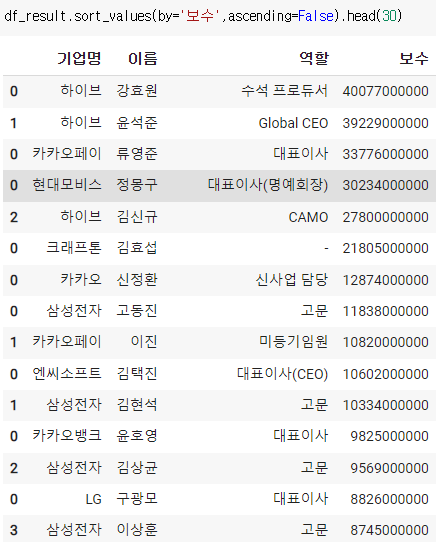
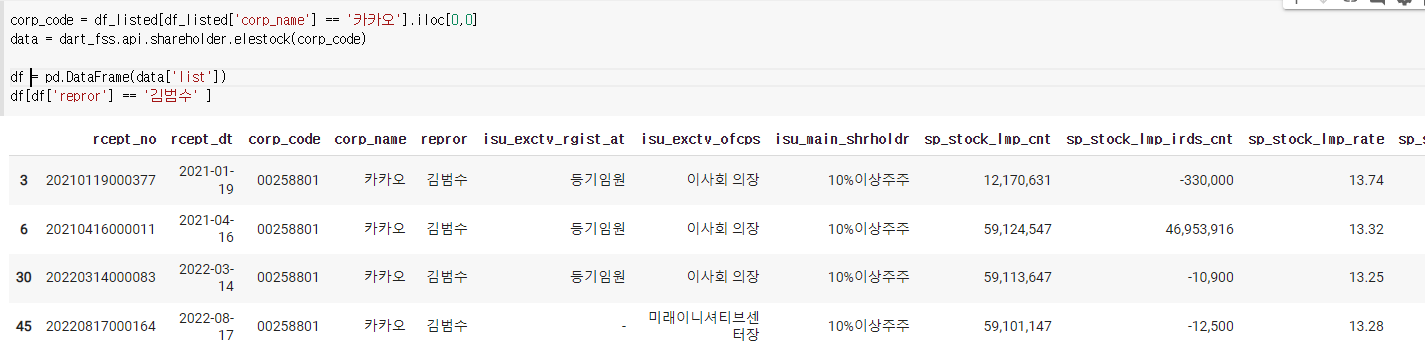
4) 최대주주의 주식변동
먼저
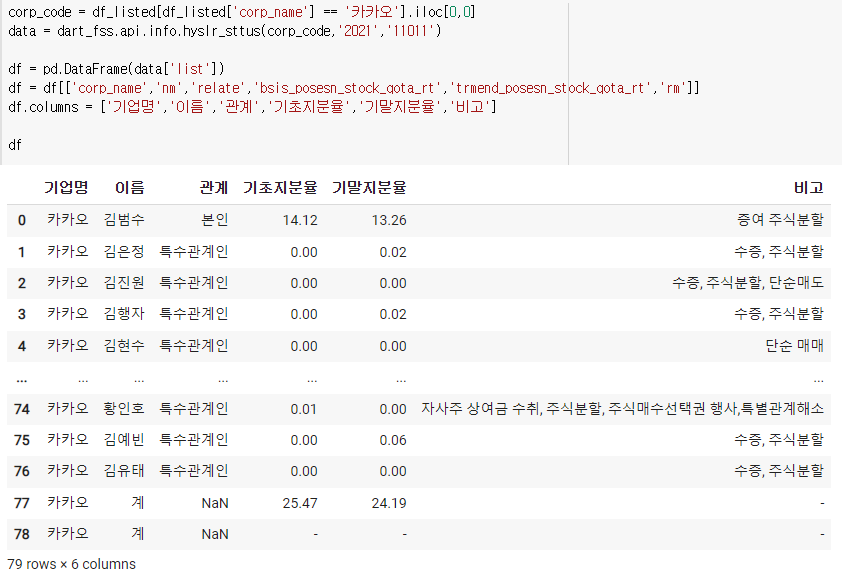
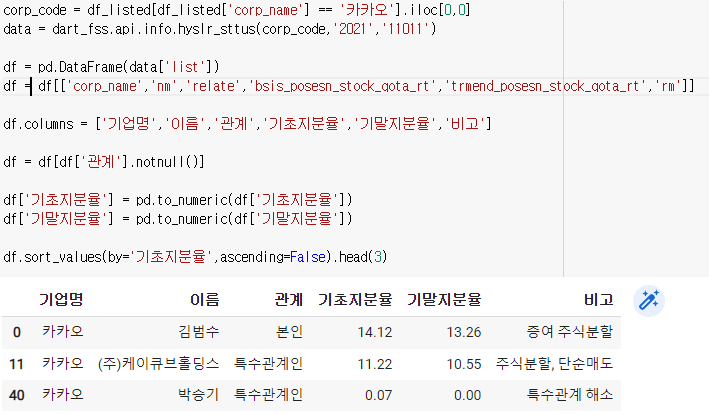
여기서 기초지분율이 문자열로 되어있으므로 바꿔줘야된다.
df.sort_values(by='기초지분율',ascending=False).head(3)
그리고 관계가 없는 부분으로인해 오류가 발생할 수 있으니 그 부분을 없애주자.
df = df[df['관계'].notnull()]
당연히 카카오로만 할게 아니므로 함수로 만들어주자
def get_shareholders(corp_code):

여러회사를 봐야하므로 회사 코드를 불러오자
'하루에 불러올 수 있는 양이 한정되 있으므로 샘플 10개로 줄여서 불러오자'
corp_codes = list(df_listed.sample(10)['corp_code'])
corp_codes
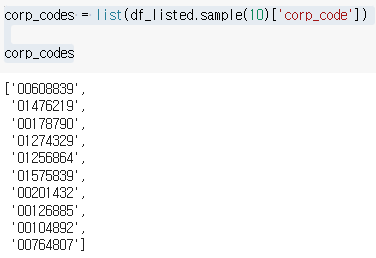
리스트가 있다? = for반복문
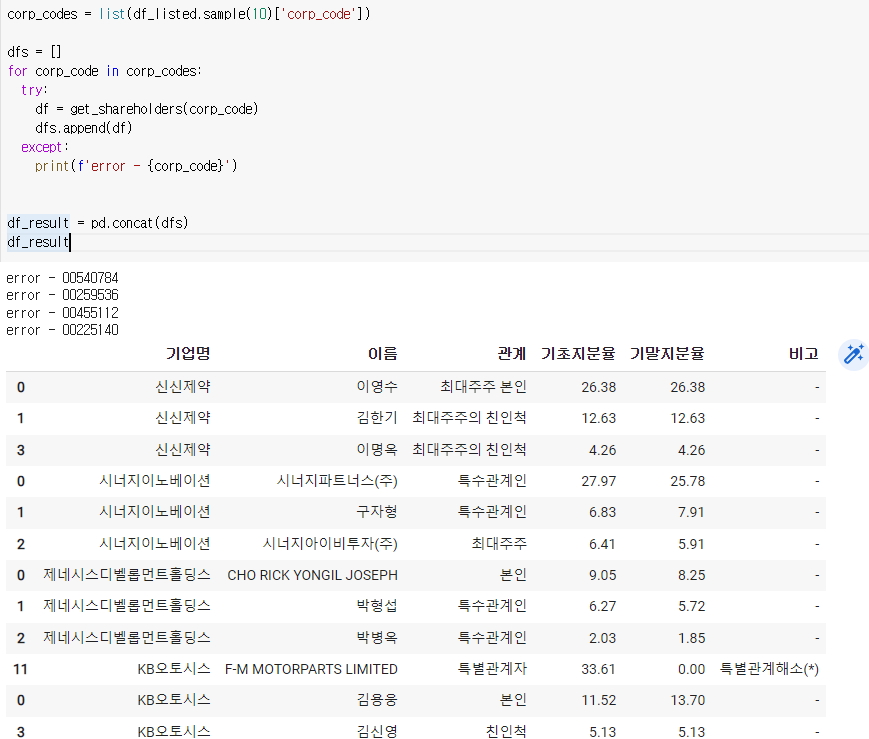
df_result = pd.concat(dfs)
df_result
이 부분이 들여쓰기가 되어있으면 반복문만 출력된다. 주의하자
증감(기말지분율 - 기초지분율)로 내림차순으로 정렬해보자
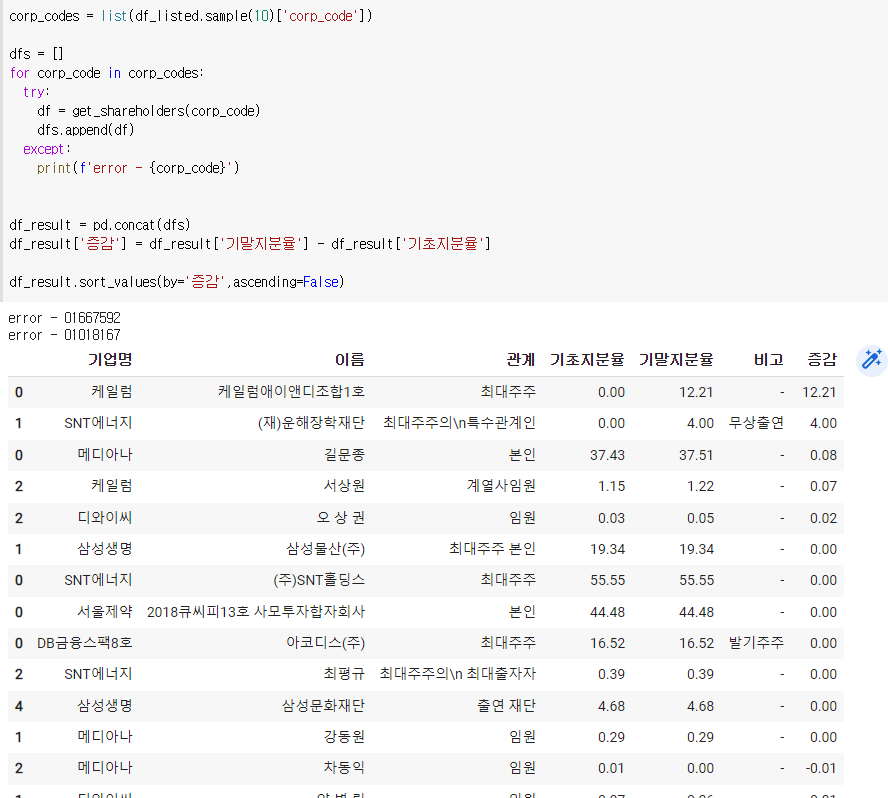
5) ‘돈 많이 번 회사’를 찾기
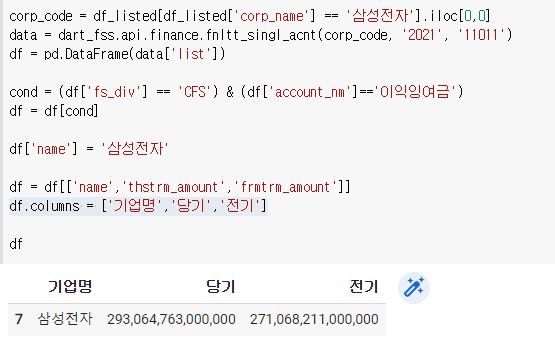
먼저 fs_div가 CFS이고 account_nm가 이익잉여금인 자료를 찾아보자
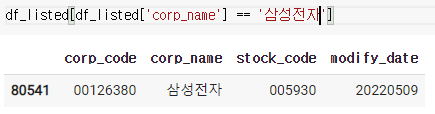
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])cond = (df['fs_div'] == 'CFS') & (df['account_nm']=='이익잉여금')
df = df[cond]df

이 중에 우리가 필요한 것만 골라보자.
df.columns = ['기업명','당기','전기']
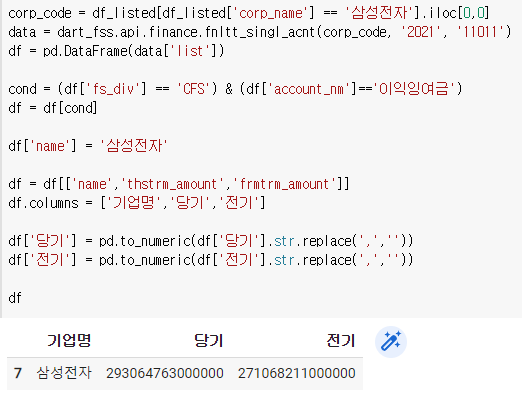
여기서 당기 전기를 숫자로 바꿔주자
df['당기'] = pd.to_numeric(df['당기'].str.replace(',',''))
df['전기'] = pd.to_numeric(df['전기'].str.replace(',',''))
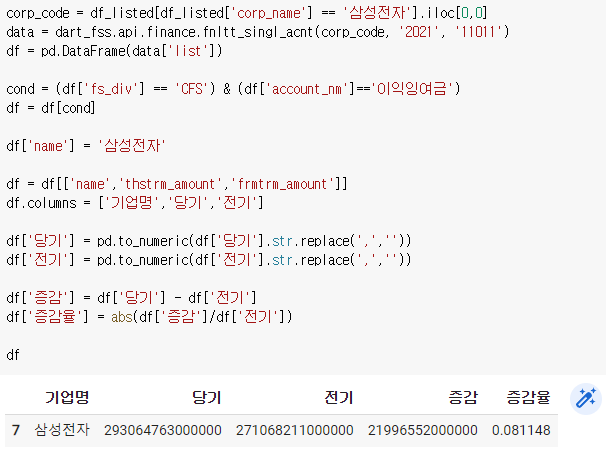
증감(단기-전기), 증감율(증감/전기)을 만들자.
참고 : 함수로 만들고나서 해도 되고 함수 들어가기 전에 미리 만들어도 된다.
함수로 만들어서 여러 기업에 돌려보자
먼저 함수로 만들어서 잘 돌아가는지 보면

잘 돌아간다.
이제 리스트를 가져오면 된다.
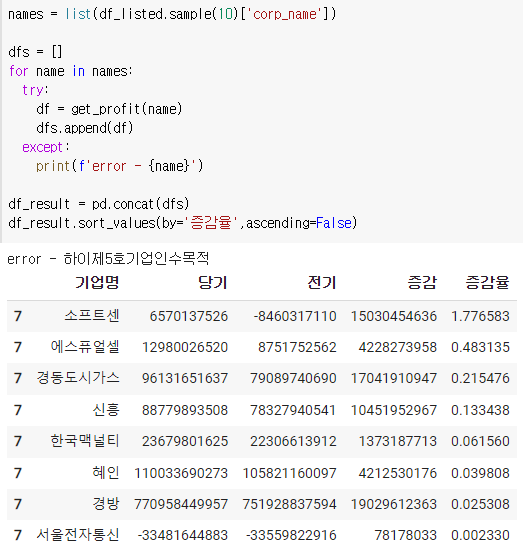
참고 : 함수를 만들고 나서 증감, 증감율의 위치

6)비상장 종목 분석하기
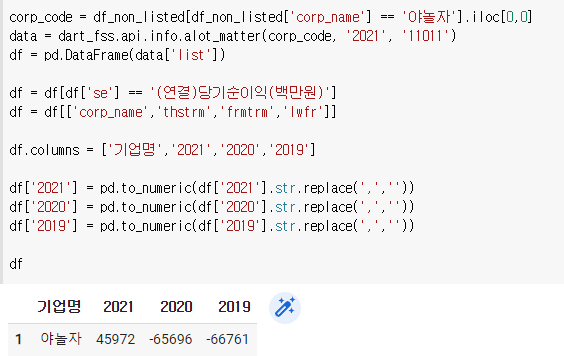
함수로 만들기
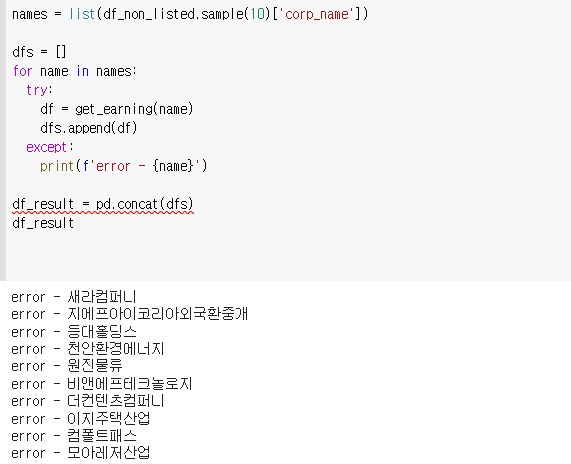
숙제
남녀 평균 급여 차이가 가장 ‘안’ 나는 회사를 찾아보기
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.emp_sttus(corp_code, '2021', '11011')pd.DataFrame(data['list'])
def get_salary(name):
corp_code = df_listed[df_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.info.emp_sttus(corp_code, '2021', '11011')df = pd.DataFrame(data['list'])
df= df[['corp_name','sexdstn','jan_salary_am']]df_result = pd.DataFrame()
doc = {
'기업명' : name,
'연봉(남)' : df[df["sexdstn"]== '남'].iloc[-1,-1],
'연봉(여)' : df[df["sexdstn"]== '여'].iloc[-1,-1]
}
df_result = df_result.append(doc, ignore_index = True)df_result['연봉(남)'] = pd.to_numeric(df_result['연봉(남)'].str.replace(',',''))
df_result['연봉(여)'] = pd.to_numeric(df_result['연봉(여)'].str.replace(',',''))return df_result
names = list(df_listed.sample(10)['corp_name'])
dfs = []
for name in names:
try:
df = get_salary(name)
dfs.append(df)
except:
print(f'error - {name}')df_result = pd.concat(dfs)
df_result['차이(남-여)'] = df_result['연봉(남)'] - df_result['연봉(여)']
df_result['평균'] = (df_result['연봉(남)']+df_result['연봉(여)'])/2df_result.sort_values(by='차이(남-여)',ascending=True)
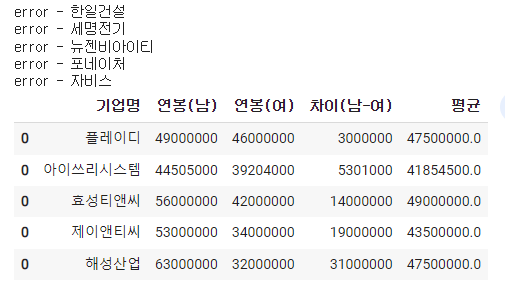
df_result = pd.concat(dfs)
df_result['차이(남-여)'] = df_result['연봉(남)'] - df_result['연봉(여)']
df_result['평균'] = (df_result['연봉(남)']+df_result['연봉(여)'])/2df_result.sort_values(by='차이(남-여)',ascending=True)
이부분에서 헤맸다.
4주차
초반에 3가지 설치해야 한다.
!pip install yfinance pandas-datareader finance-datareader
설치 후 코드 스니팻 복사 후 붙여넣기
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()import numpy as np
import pandas as pdimport FinanceDataReader as fdr
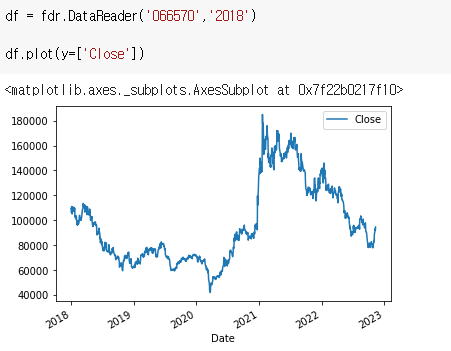
df = fdr.DataReader('005930','2018')
df.head()
그래프
df.plot(y=['Close'])
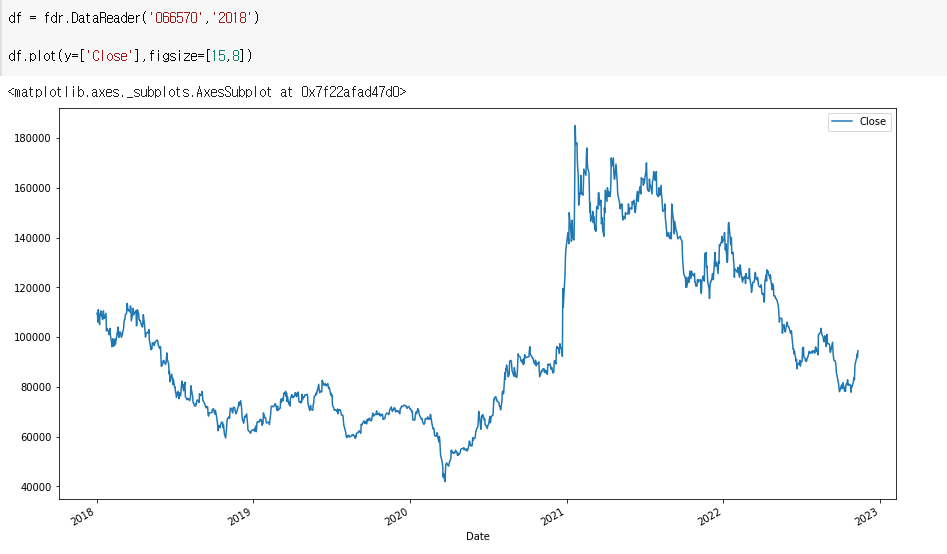
df.plot(y=['Close'],figsize=[15,8])
좀 더 크게 나온다
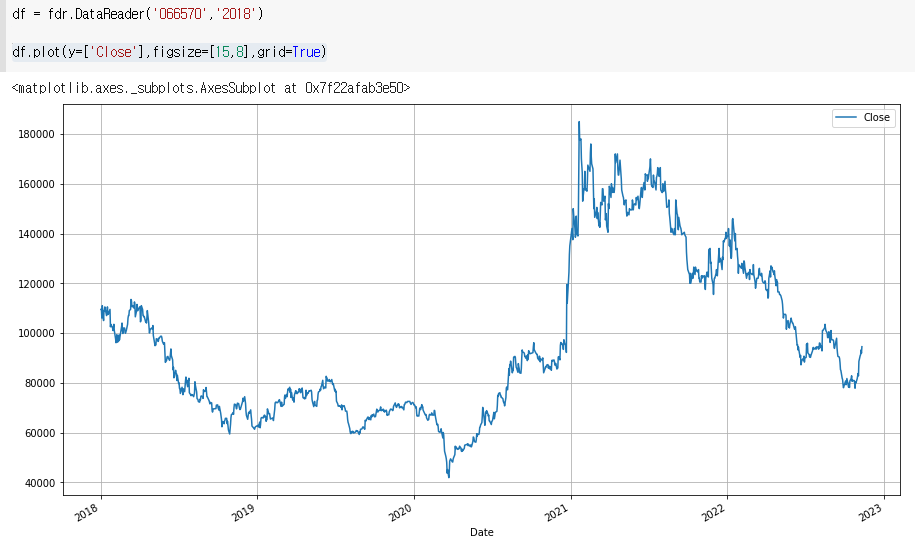
df.plot(y=['Close'],figsize=[15,8],grid=True)
좀더 크게 격자선넣기
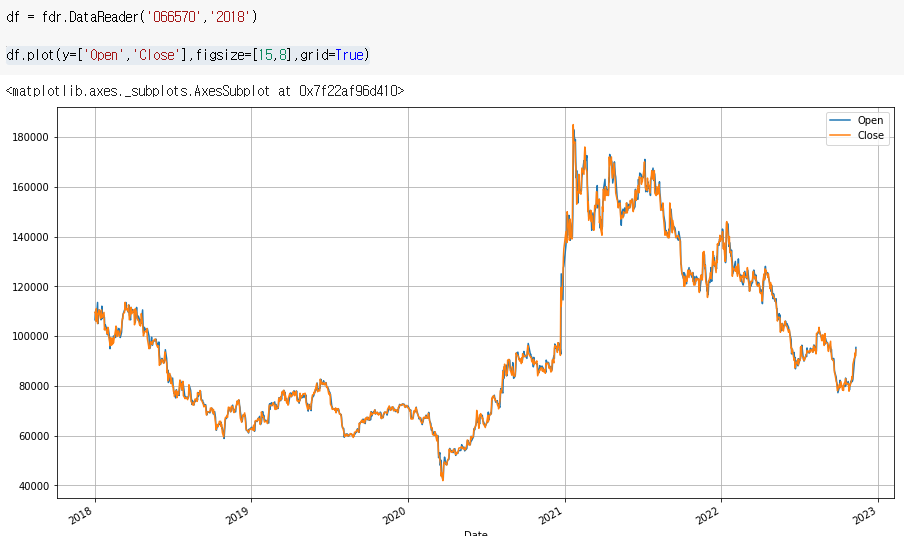
df.plot(y=['Open','Close'],figsize=[15,8],grid=True)
Open, Close가 같이 나온다.
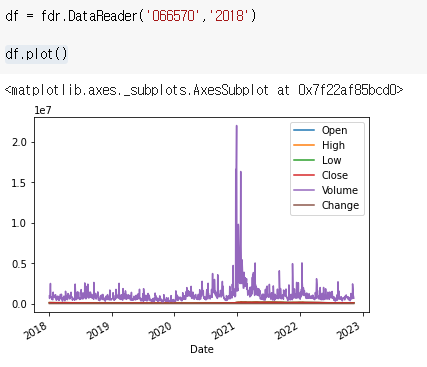
df.plot()
df에 있는걸 다 그러준다
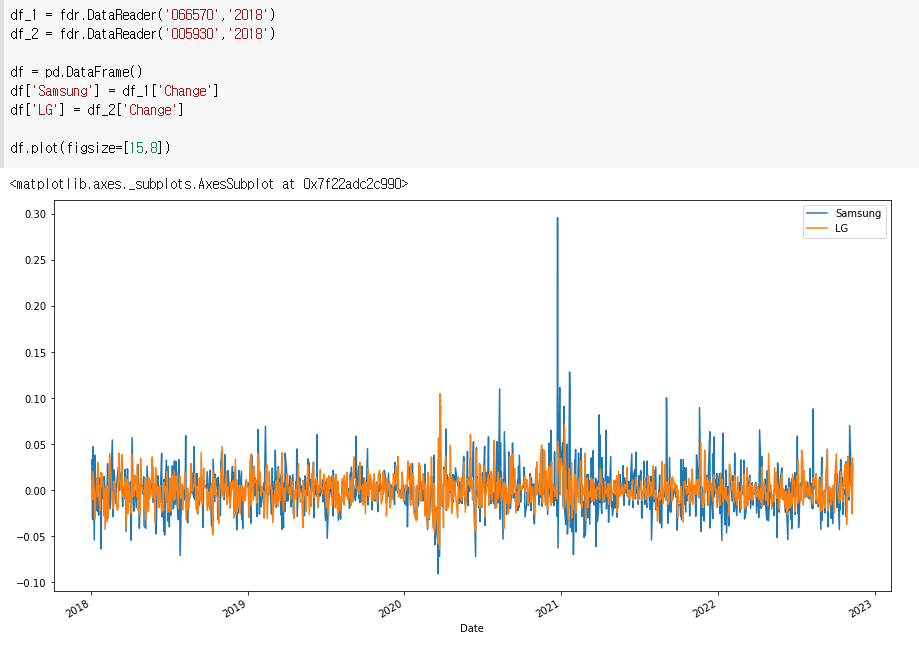
1) 두 회사를 같이 보고싶을때
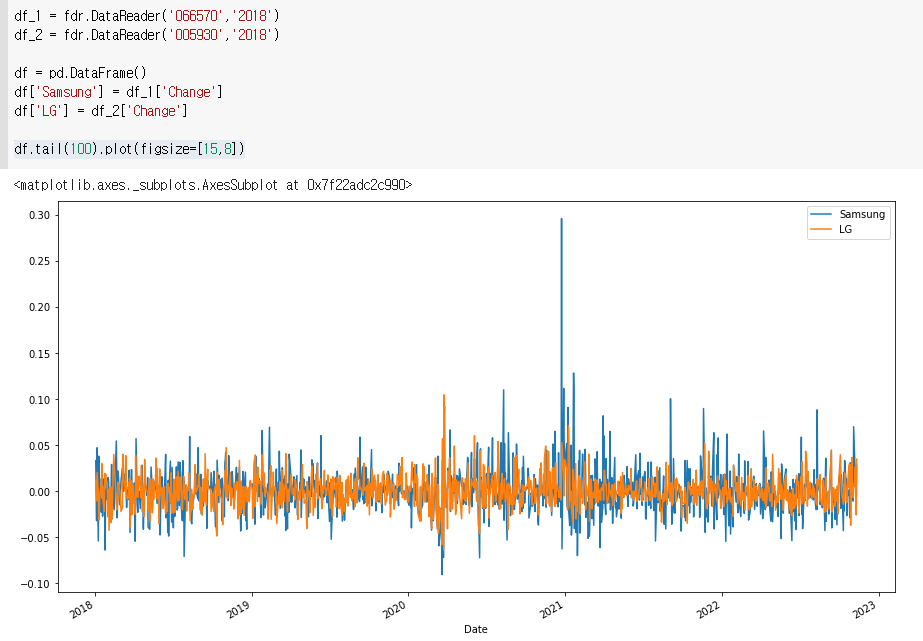
최근 100일을 그래프로 그려라
df.tail(100).plot(figsize=[15,8])
2) 이동평균 값만들기
먼저
참고 : 여기서 rolling(3)은 위에서부터 3개씩 묶는다. 예시) 0,1,2 / 1,2,3, / 2,3,4 이런순으로 묶는다고 생각하면 된다.
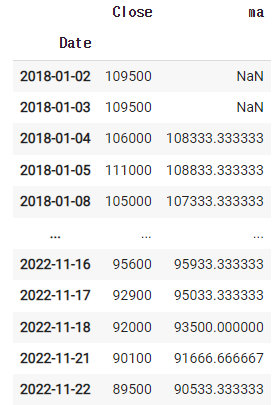
그런다음 ma값을 한칸씩 내려야 비교대상이 되므로
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df
shift를 넣어 내려준다.
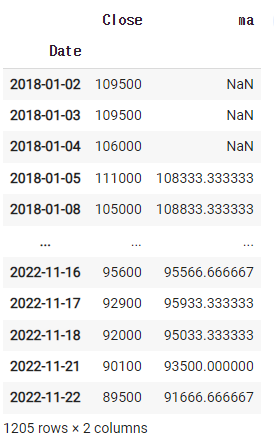
그 후 비교대상과 비교 후 구매할지 판매할지 표시
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df
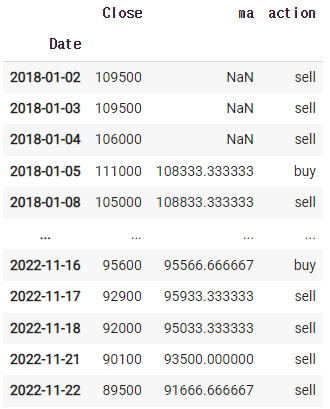
2. 수익률구하기
buy → buy → buy 이면, 사는 게 아니다.
즉, buy와 sell이 바뀌는 순간이 중요하다.
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df['action_temp'] = df['action'].shift(1)df
즉 action_temp는 shift가 1인것과 나 자신을 비교하는 것이다.
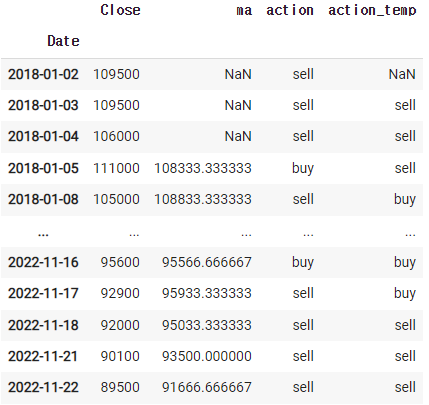
1) 사는 시점, 파는시점
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
cond = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
df['real_buy'] = np.where(cond,'buy','')
df
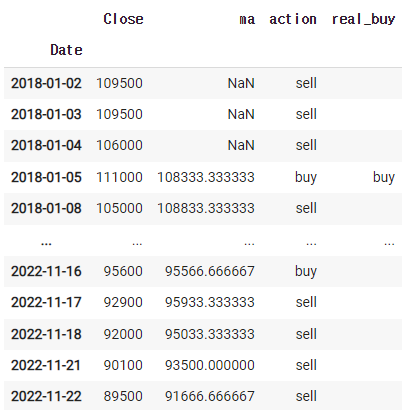
real_buy에 표기된 'buy'시기를 모으면 사는 시점이 될것이다.
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df[cond1]
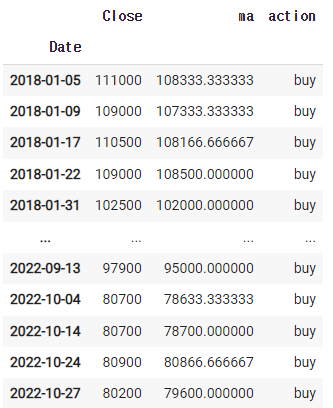
반대로 'sell'시기를 모으면 파는 시점이 될것이다.
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df[cond2]
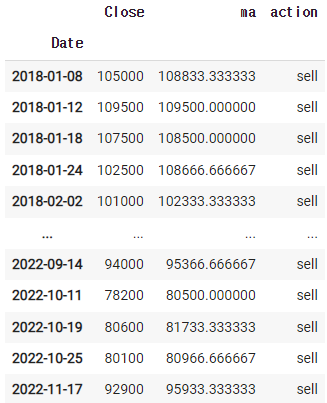
이 것을 한데 모으면

마지막에 df_buy 또는 df_sell을 넣으면 입력값이 나온다.
또한 수익률이기때문에 맨 마지막은 무조건 판매(sell)이 나와야 되므로
df.iloc[-1,-1] = 'sell'
이것을 넣어줘야된다.
여기서 concat을 옆으로 붙여줄려면
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1]
df_sell = df[cond2]df_result = pd.concat([df_buy, df_sell],axis=1)
df_result.head(30)
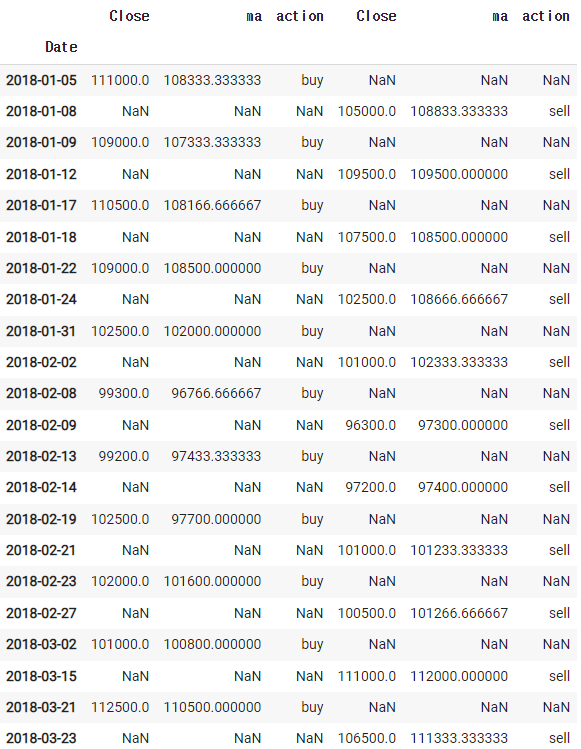
그렇지만 한줄이 밑에 있기 때문에 이걸 합쳐줄려면
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_sell = df[cond2].reset_index()df_result = pd.concat([df_buy, df_sell],axis=1)
df_result.head(30)
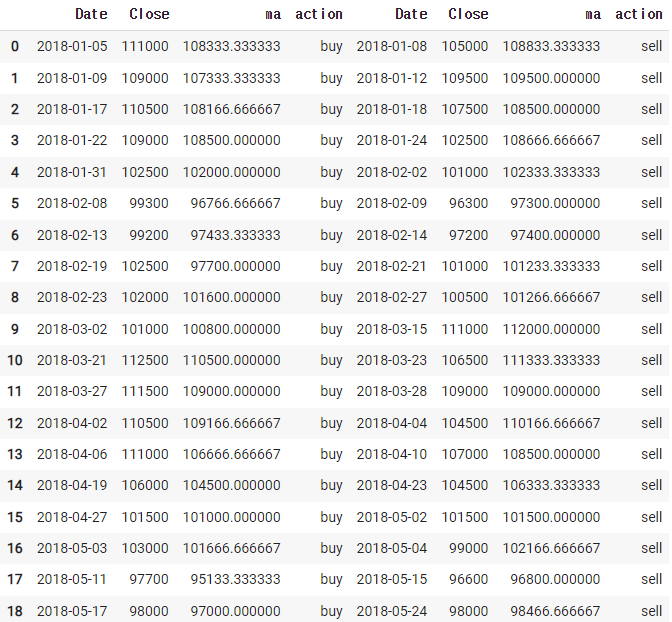
이렇게 하면 깔끔하게 볼 수 있다. 여기서 중요한 부분은 close 인데 두개가 있으므로 이름을 바꿔주자
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값','액션']
df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result.head(30)
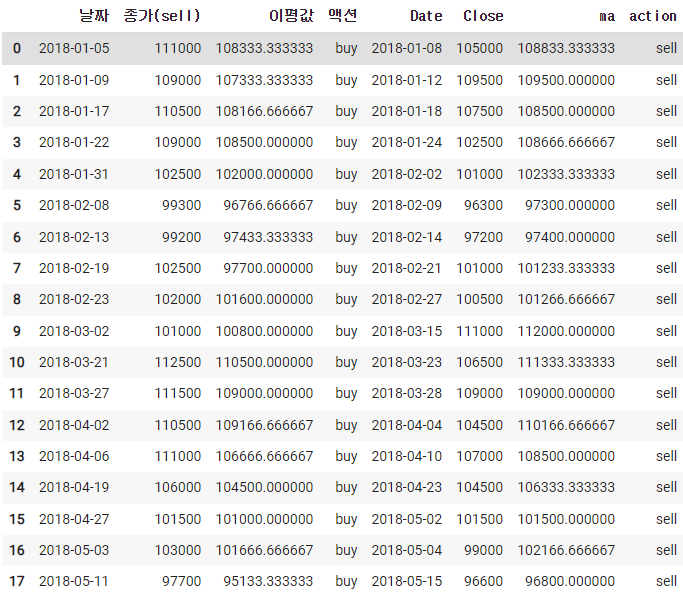
수익률은 종가(sell)/종가(buy)로 하면 된다.
df = fdr.DataReader('066570','2018')
df = df[['Close']]
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값','액션']df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
df_result
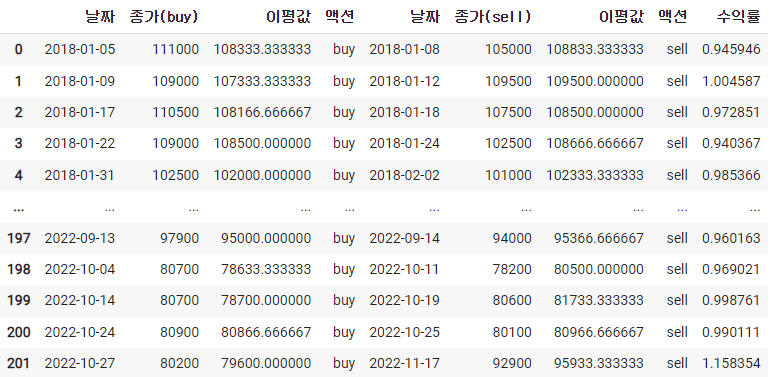
수익률자료만 가져오자 (오류가 뜰텐데 그 뒤에 자료가 중복되어서 위험하다고 알려주는것이므로 copy를 넣어주자)
df = fdr.DataReader('066570','2018')
df = df[['Close']].copy()
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값','액션']df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
df_result[['수익률']]
그 후 전체를 곱해주면된다.
df = fdr.DataReader('066570','2018')
df = df[['Close']].copy()
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값','액션']df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
df_result['수익률cumprod'] = df_result[['수익률']].cumprod()
df_result
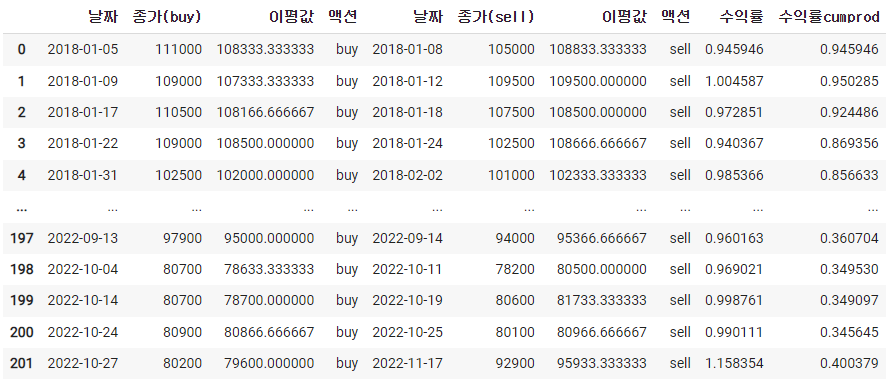
수익률cumprod는 그 라인부터 위쪽으로 전부 곱하게 된것이다.
거기서 맨 마지막것을 가져와서 -1을 해주면 수익률이 나온다.
df = fdr.DataReader('066570','2018')
df = df[['Close']].copy()
df['ma'] = df.rolling(3).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값','액션']df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
df_result[['수익률']].cumprod().iloc[-1,-1]-1
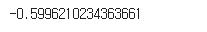
이것을 함수로 나타낼려면?
def get_return(code,n):
df = fdr.DataReader(code,'2018')df = df[['Close']].copy()
df['ma'] = df.rolling(n).mean().shift(1)
df['action'] = np.where(df['Close'] > df['ma'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값','액션']df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
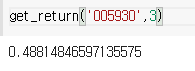
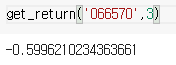
return df_result[['수익률']].cumprod().iloc[-1,-1]-1

code는 회사주식코드이고 n은 날짜이다.
예시) 삼성전자 005930
예시) LG전자 066570
3. 단기 이평선, 장기 이평선
먼저 사용했던 곳에서 코드를 뽑아오면
df = fdr.DataReader('005930','2018')
df = df[['Close']].copy()
df.iloc[-1,-1] = 'sell'
df['ma1'] = df.rolling(3).mean().shift(1)
df['ma2'] = df.rolling(30).mean().shift(1)df['action'] = np.where(df['ma1'] > df['ma2'], 'buy','sell')
df
이렇게 하면 오류가 뜨는데 위에 함수가 없는 곳이 있기 때문이다.
df = fdr.DataReader('005930','2018')df = df[['Close']].copy()
df['ma1'] = df['Close'].rolling(3).mean().shift(1)
df['ma2'] = df['Close'].rolling(30).mean().shift(1)df['action'] = np.where(df['ma1'] > df['ma2'], 'buy','sell')
df
이렇게 해야 오류가 안뜬다.
그 후 하나씩 가져오면서 검토해보면
df = fdr.DataReader('005930','2018')
df = df[['Close']].copy()
df['ma1'] = df['Close'].rolling(3).mean().shift(1)
df['ma2'] = df['Close'].rolling(30).mean().shift(1)df['action'] = np.where(df['ma1'] > df['ma2'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값1','이평값2','액션']
df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값1','이평값2','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
df_result[['수익률']].cumprod().iloc[-1,-1]-1

단기는 며칠이고 장기는 며칠이고 수익률은 나는지를 만들어보자
df = fdr.DataReader('005930','2018')
df = df[['Close']].copy()
df['ma1'] = df['Close'].rolling(3).mean().shift(1)
df['ma2'] = df['Close'].rolling(30).mean().shift(1)df['action'] = np.where(df['ma1'] > df['ma2'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값1','이평값2','액션']
df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값1','이평값2','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
df_final = (df_result[['수익률']].cumprod().tail(1)-1)*100
df_final['단기'] = 3
df_final['장기'] = 30df_final

이것을 가지고 함수로 만들어보자.(def get_return_sl(code,short,long)
def get_return_sl(code, short, long):
df = fdr.DataReader(code,'2018')
df = df[['Close']].copy()
df['ma1'] = df['Close'].rolling(short).mean().shift(1)
df['ma2'] = df['Close'].rolling(long).mean().shift(1)df['action'] = np.where(df['ma1'] > df['ma2'], 'buy','sell')
df.iloc[-1,-1] = 'sell'
cond1 = (df['action'] == 'buy') & (df['action'].shift(1) == 'sell')
cond2 = (df['action'] == 'sell') & (df['action'].shift(1) == 'buy')df_buy = df[cond1].reset_index()
df_buy.columns = ['날짜','종가(buy)','이평값1','이평값2','액션']
df_sell = df[cond2].reset_index()
df_sell.columns = ['날짜','종가(sell)','이평값1','이평값2','액션']df_result = pd.concat([df_buy, df_sell],axis=1)
df_result['수익률'] = df_result['종가(sell)'] / df_result['종가(buy)']
df_final = (df_result[['수익률']].cumprod().tail(1)-1)*100
df_final['단기'] = short
df_final['장기'] = longreturn df_final

이렇게 하면 한 종목에서 최적의 단기종목과 최적의 장기종목을 알 수 있다.
숙제
한 종목에 대해 최적의 단기/장기이평선
단기 : 3일~10일
장기 : 30일~60일
dfs = []
for short in range(3,11):
for long in range(30,61):
df = get_return_sl('005930',short, long)
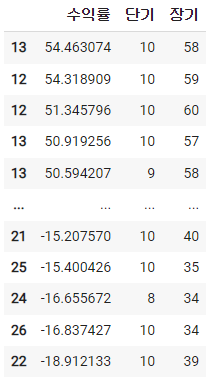
dfs.append(df)df_result = pd.concat(dfs)
df_result.sort_values(by='수익률', ascending = False)
처음 dfs.append(df)로 데이터를 축적해야되는데 그걸 까먹었다.
최적의 이평선을 구해야 되므로 수익률로 내림차순하면 볼 수 있다.
5주차
라이브러리 설치하기
!pip install yfinance pandas-datareader finance-datareader
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()import numpy as np
import pandas as pdimport FinanceDataReader as fdr
df = fdr.DataReader('005930','2018')
df.head()
이러한 코드는 내가 외워서 사용하는게 아니라 따로 저장해뒀다가 가져와서 사용하는 것이다.
데이터를 가져왔으면 원하는 형태로 만들어야된다.
백테스팅 첫번째
1. 사야하는 날 & 파는 가격 구하기
1) 사야하는 가격을 구하기
사야하는 가격 = (어제 최고가 - 어제 최저가)*K + 오늘 최저가
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df.head()
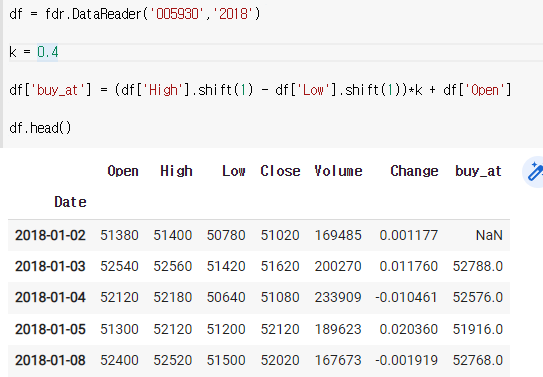
2) 사야하는 날을 구하기
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df.head()
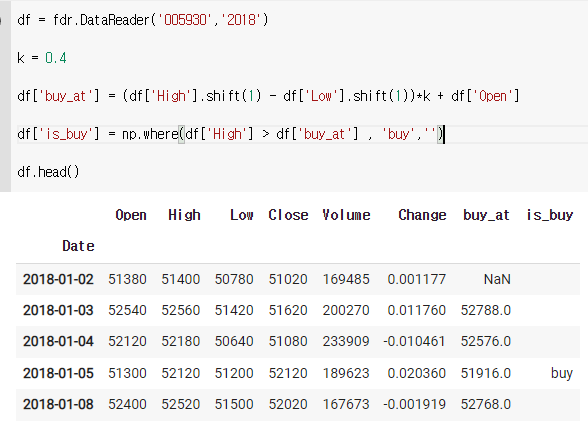
3) 팔아야하는 가격 구하기
buy가 있으면 sell도 있어야되므로
buy에서 한칸 당기면 된다.(-1)
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df.head()
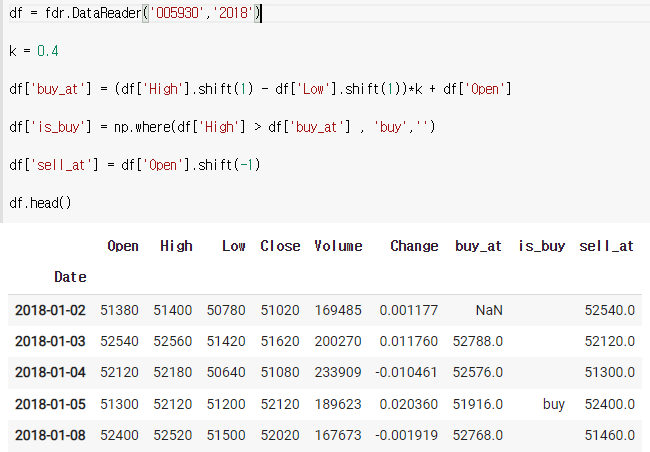
2. 수익률구하기
is_buy 가 있는 행들만 추린 후 buy_at , sell_at 으로 수익률 구하기
1) is_buy가 있는 해들만 추리기
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df.head()
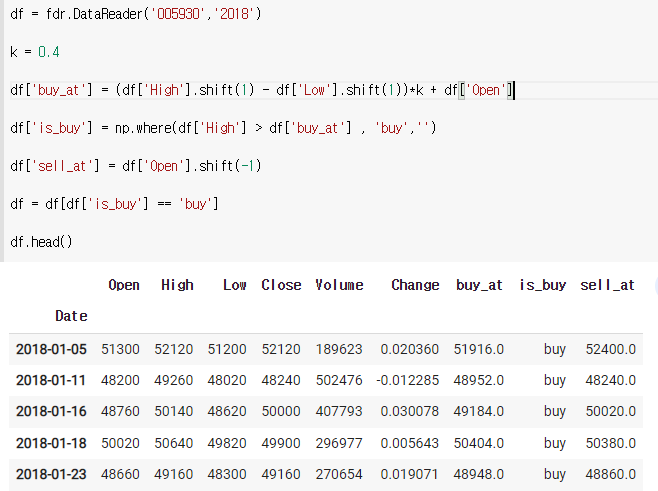
2) buy_at , sell_at 으로 수익률 구하기
먼저 return으로 sell_at/buy_at을 구한다.
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']
df.head()

그 후 return만을 사용해 누적곱을 한 후 맨 마지막 값의 마지막 데이터를 가져오면 수익률이 나온다. 그 후 여기서 1을 빼주면 된다.
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']
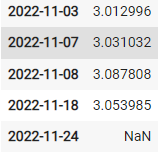
df[['return']].cumprod().iloc[-2,-1] -1

여기서 iloc[-2,-1]의 값이 -2인 이유는 맨 마지막값이 없기 때문에 그 전날의 값을 불러온것이다.
3. 최적의 K 구하기
1) 함수로 만들기
def get_return(code, k):
df = fdr.DataReader(code,'2018')
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']
return df[['return']].cumprod().iloc[-1,-1] -1
실행해줍니다.
잘 돌아가는지 테스트를 해본다.
2) 잘 돌아가는지 확인되면 반복문으로 계속 돌리면서 뭐가 최적인지 확인한다.
먼저
np.arange(0.4 , 0.6 , 0.01)

0.4에서 0.6까지 0.01씩 증가하는 것을 리스트로 뽑아준다.
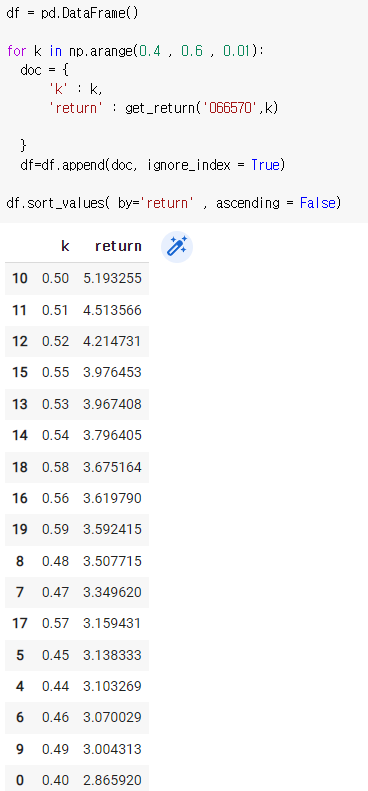
반복문으로 만들어주면

삼성은 값이 없었으므로 LG전자로 해본 결과

일일이 확인하기 어려우므로 데이터프레임으로 만들어서 수익률 순서대로 정렬을 시켜서 맨 위에것을 뽑으면 된다.
df = pd.DataFrame()
for k in np.arange(0.4 , 0.6 , 0.01):
doc = {
'k' : k,
'return' : get_return('066570',k)
}
df=df.append(doc, ignore_index = True)df.sort_values( by='return' , ascending = False)
백테스팅 두번째
1. 요일 표기와 주별 가격 붙이기
df = fdr.DataReader('005930','2018')
df
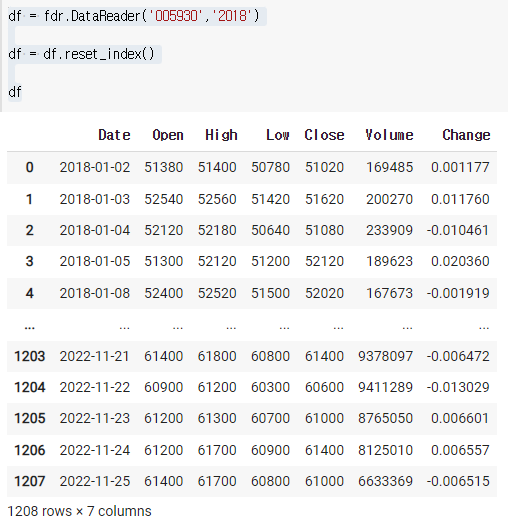
여기서 df['Date'] 하면 값을 불러올 수 없다. index으로 들어가있고 유일한 값이기도 하기때문이다. 그러므로 이 index를 그냥 reset해주면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df
이렇게 초기화해주고 우리는 여기서 Date와 Open만 필요하기 때문에
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df
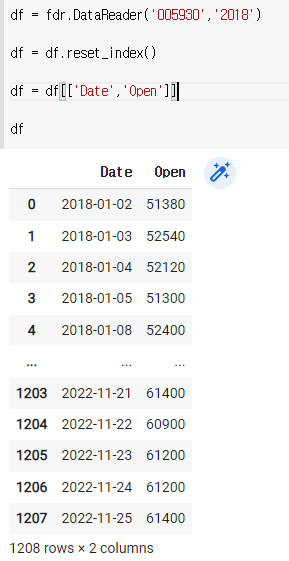
날짜를 넣어준다.
먼저 판다스의 기능을 이용해서 날짜를 숫자로 바꿔준다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Date'] = pd.to_datetime(df['Date'])
df
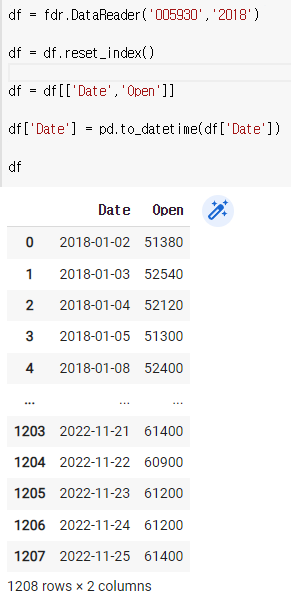
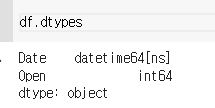
dtypes로 확인해보자
다음으로
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
df
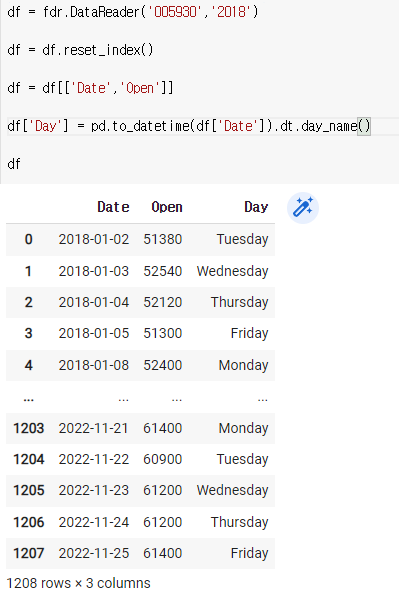
저걸 넣음으로써 뒤에 이렇게 요일이 붙게된다.
이런것은 어떻게 찾냐하면 인터넷에 검색해서 찾으면 된다고 한다.
월요일하고 금요일만 남겨보자
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
df
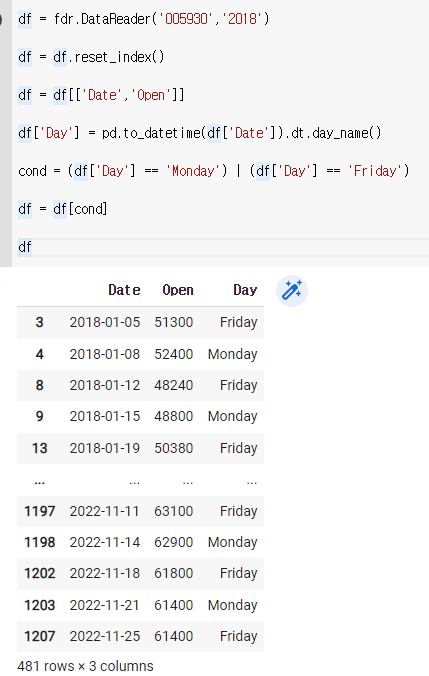
*여기서 또는 대신에 사용된 |는 shift + (역슬레이스)를 치면 나온다.
여기서는 월요일로 시작해서 금요일로 끝나야만 하기 때문에
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])df
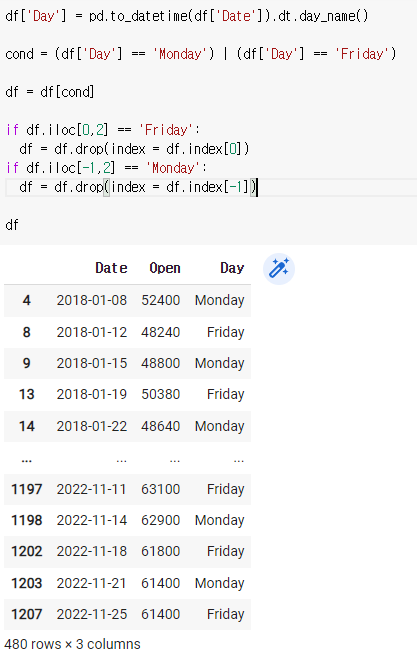
'0번째 줄의 2번째 칸이 Friday면 drop해줘라 index의 0번째줄 전체를' 이라는 뜻이다.
마지막으로 휴일을 고려해보면 Monday나 Friday가 두번연속 나오면 Monday는 앞에줄을 Friday는 뒤에줄을 없애면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df[cond]
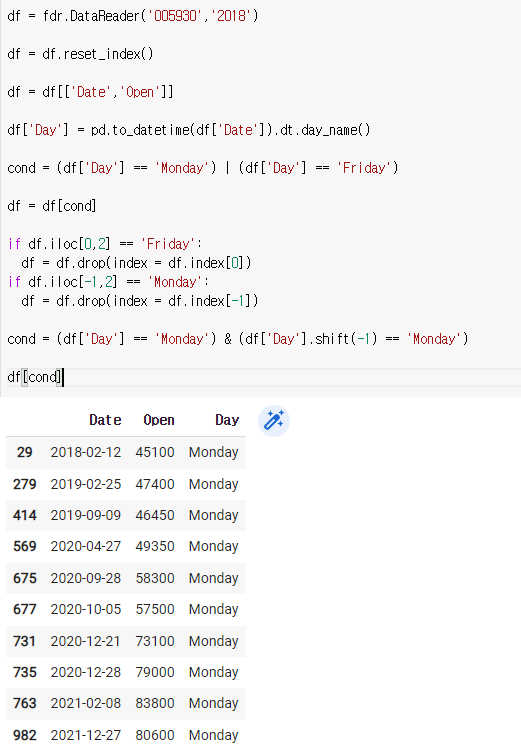
여기 표시된 애들을 싹다 지워줘야 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df
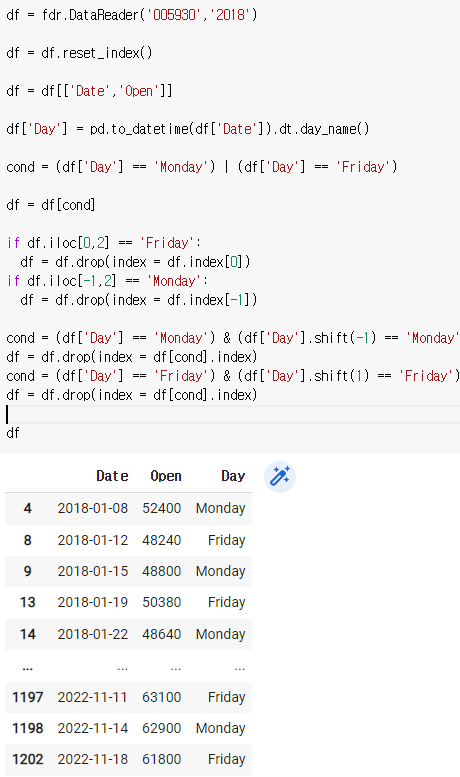
df = df.drop(index = df[cond].index)는 df[cond]자체를 없앤다.
그 다음 수익률을 계산해보자
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df

df['Open_fri'] = df['Open'].shift(-1) 는 오픈의 금요값을 이동시켜서 옆에다 만든 후에
df = df[df['Day']=='Monday']이걸로 월요일 값만 표기를 하면 된다.
그리고 우리한테 필요한 open값과 open_fri값만 가져온 후 이름을 바꿔주면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df
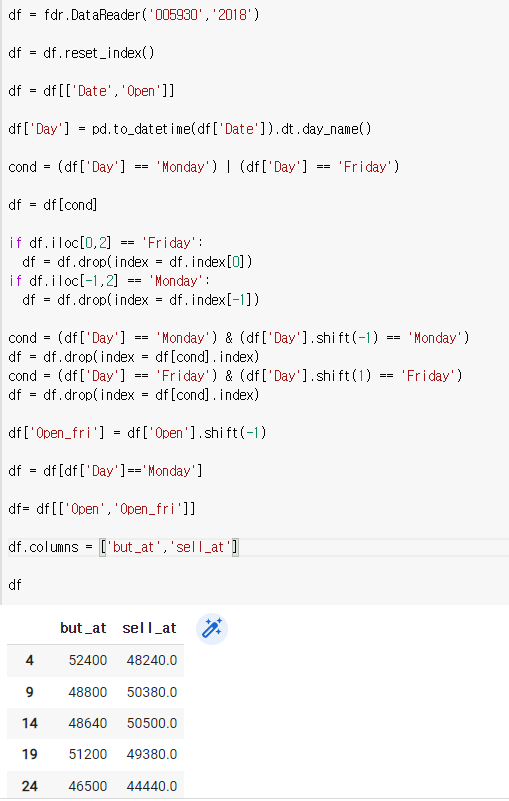
수익률(sell_at/buy_at)로 return값을 만든후에 그 값을 cumprod하면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
df[['return']].cumprod()
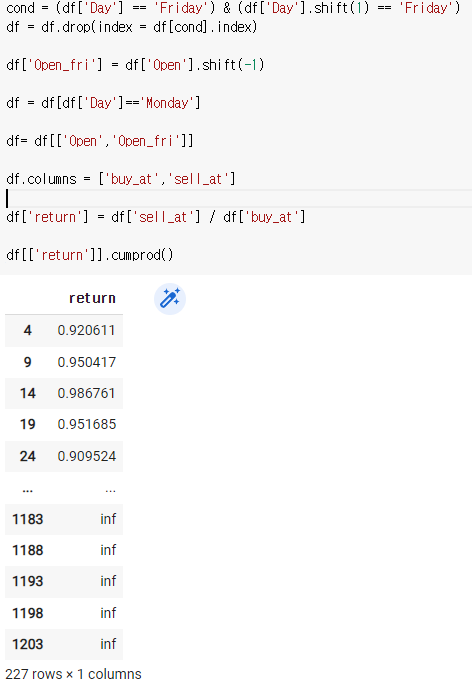
밑에 inf라는 오류가 발생했는데 이는 나누는 값에 0이 들어간 것이다. 이런것들을 싹 없애줘야 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]df[['return']].cumprod()
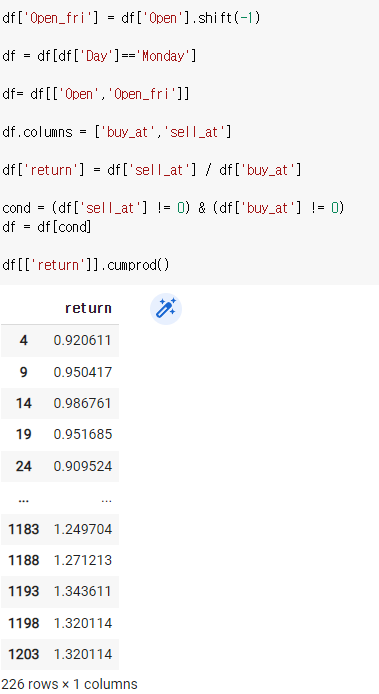
최종적으로 수익률은
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]df[['return']].cumprod().iloc[-1,-1] -1

이제 이것을 함수로 만들면
>def get_return_mf(code):
df = fdr.DataReader(code,'2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]return df[['return']].cumprod().iloc[-1,-1] -1

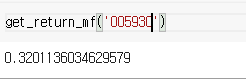
이제 월 금 전략이 가장 잘 맞는 종목을 추려보자
!pip install dart-fss
설치 후 코드스니펫 가져와 붙여넣자
import dart_fss as dart_fss
import pandas as pdapi_key = 'API키 입력하기'
dart_fss.set_api_key(api_key=api_key)all = dart_fss.api.filings.get_corp_code()
df = pd.DataFrame(all)
df_listed = df[df['stock_code'].notnull()]
for row in df_listed.sample(10)[['stock_code','corp_name']].itertuples():
print(row)
마지막 반복문 부분만 때서 코드로 따로 만듦녀 안해도 되는 부분을 빼고 실행할 수 있다.

row[1]은 회사코드, row[2]는 회사명을 뜻한다.
이것을 여러 회사에 적용해서 최고 효율의 회사를 봐보자
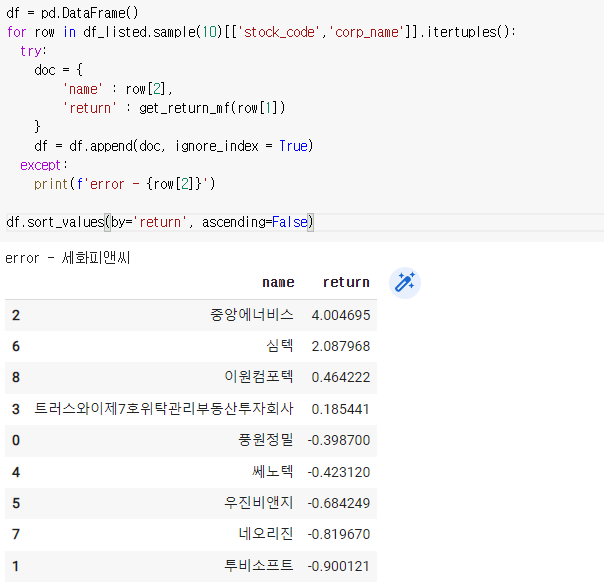
df = pd.DataFrame()
for row in df_listed.sample(10)[['stock_code','corp_name']].itertuples():
try:
doc = {
'name' : row[2],
'return' : get_return_mf(row[1])
}
df = df.append(doc, ignore_index = True)
except:
print(f'error - {row[2]}')df.sort_values(by='return', ascending=False)
{kind=link}
return을 기준으로 내림차순을 해주면 보기 편하다.
자꾸 doc { , } 를 까먹는다 항목당 ,를 꼭 넣어주자
