라이브러리 설치하기
!pip install yfinance pandas-datareader finance-datareader
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()import numpy as np
import pandas as pdimport FinanceDataReader as fdr
df = fdr.DataReader('005930','2018')
df.head()
이러한 코드는 내가 외워서 사용하는게 아니라 따로 저장해뒀다가 가져와서 사용하는 것이다.
데이터를 가져왔으면 원하는 형태로 만들어야된다.
백테스팅 첫번째
1. 사야하는 날 & 파는 가격 구하기
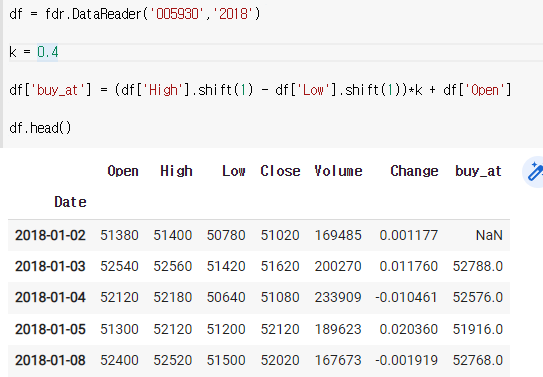
1) 사야하는 가격을 구하기
사야하는 가격 = (어제 최고가 - 어제 최저가)*K + 오늘 최저가
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df.head()
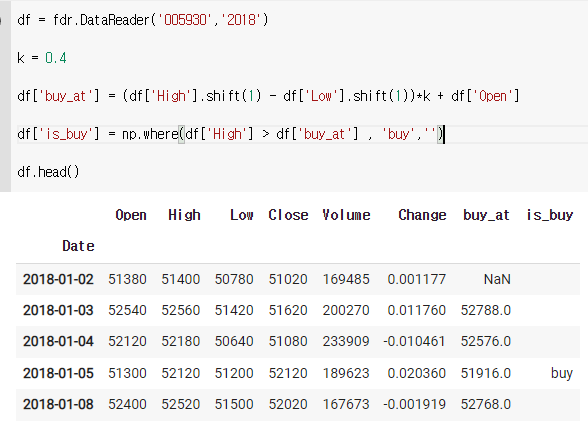
2) 사야하는 날을 구하기
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df.head()
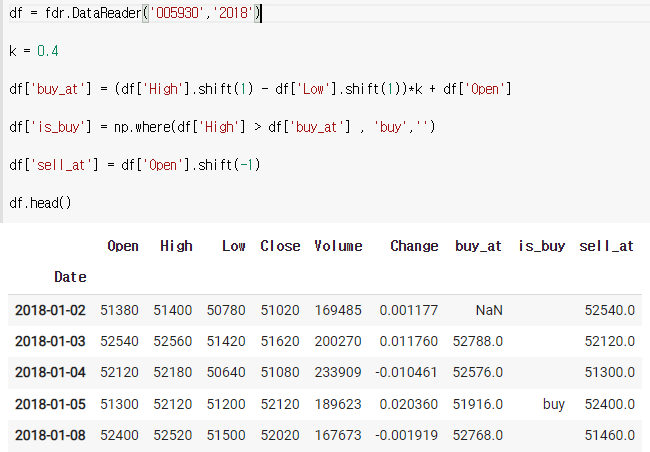
3) 팔아야하는 가격 구하기
buy가 있으면 sell도 있어야되므로
buy에서 한칸 당기면 된다.(-1)
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df.head()
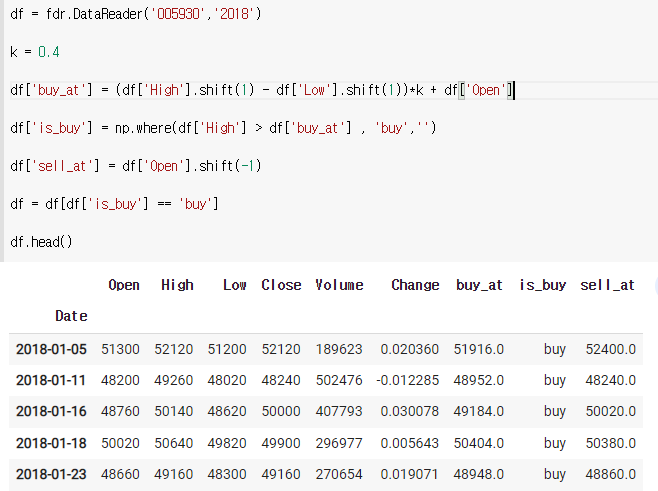
2. 수익률구하기
is_buy 가 있는 행들만 추린 후 buy_at , sell_at 으로 수익률 구하기
1) is_buy가 있는 해들만 추리기
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df.head()
2) buy_at , sell_at 으로 수익률 구하기
먼저 return으로 sell_at/buy_at을 구한다.
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']
df.head()

그 후 return만을 사용해 누적곱을 한 후 맨 마지막 값의 마지막 데이터를 가져오면 수익률이 나온다. 그 후 여기서 1을 빼주면 된다.
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']
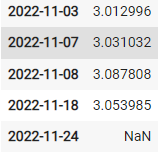
df[['return']].cumprod().iloc[-2,-1] -1

여기서 iloc[-2,-1]의 값이 -2인 이유는 맨 마지막값이 없기 때문에 그 전날의 값을 불러온것이다.
3. 최적의 K 구하기
1) 함수로 만들기
def get_return(code, k):
df = fdr.DataReader(code,'2018')
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'] , 'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']
return df[['return']].cumprod().iloc[-1,-1] -1
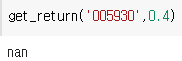
실행해줍니다.
잘 돌아가는지 테스트를 해본다.
2) 잘 돌아가는지 확인되면 반복문으로 계속 돌리면서 뭐가 최적인지 확인한다.
먼저
np.arange(0.4 , 0.6 , 0.01)

0.4에서 0.6까지 0.01씩 증가하는 것을 리스트로 뽑아준다.
반복문으로 만들어주면

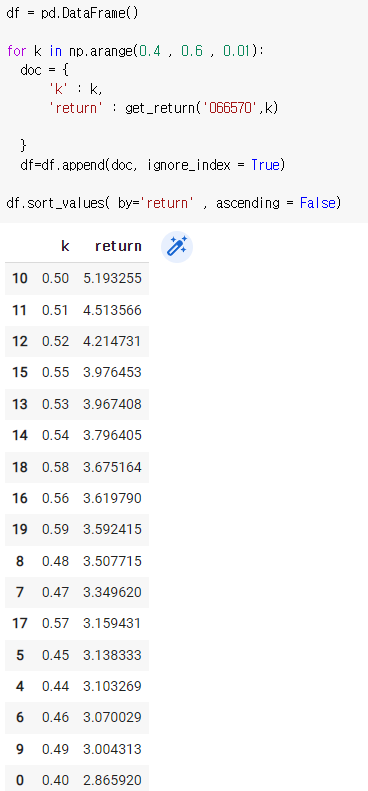
삼성은 값이 없었으므로 LG전자로 해본 결과

일일이 확인하기 어려우므로 데이터프레임으로 만들어서 수익률 순서대로 정렬을 시켜서 맨 위에것을 뽑으면 된다.
df = pd.DataFrame()
for k in np.arange(0.4 , 0.6 , 0.01):
doc = {
'k' : k,
'return' : get_return('066570',k)
}
df=df.append(doc, ignore_index = True)df.sort_values( by='return' , ascending = False)
백테스팅 두번째
1. 요일 표기와 주별 가격 붙이기
df = fdr.DataReader('005930','2018')
df
여기서 df['Date'] 하면 값을 불러올 수 없다. index으로 들어가있고 유일한 값이기도 하기때문이다. 그러므로 이 index를 그냥 reset해주면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df
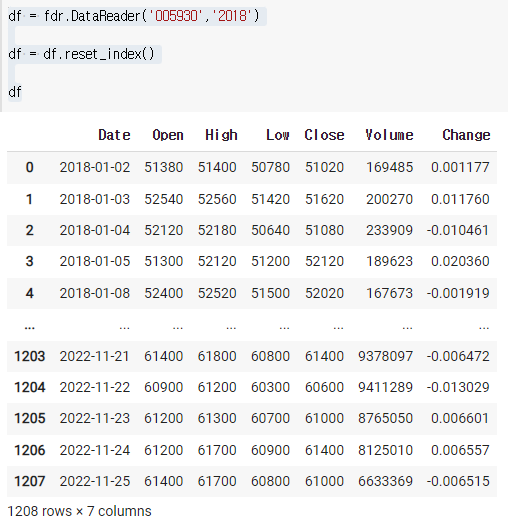
이렇게 초기화해주고 우리는 여기서 Date와 Open만 필요하기 때문에
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df
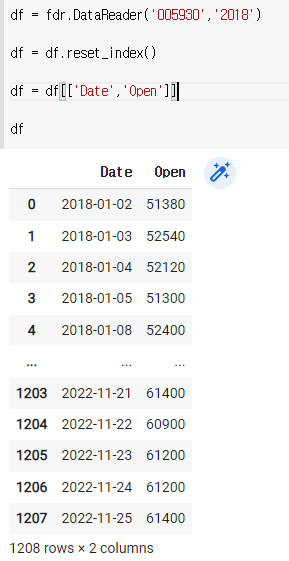
날짜를 넣어준다.
먼저 판다스의 기능을 이용해서 날짜를 숫자로 바꿔준다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Date'] = pd.to_datetime(df['Date'])
df
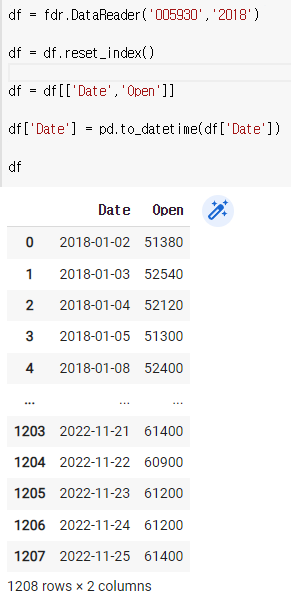
dtypes로 확인해보자
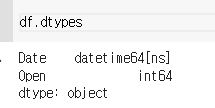
다음으로
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
df
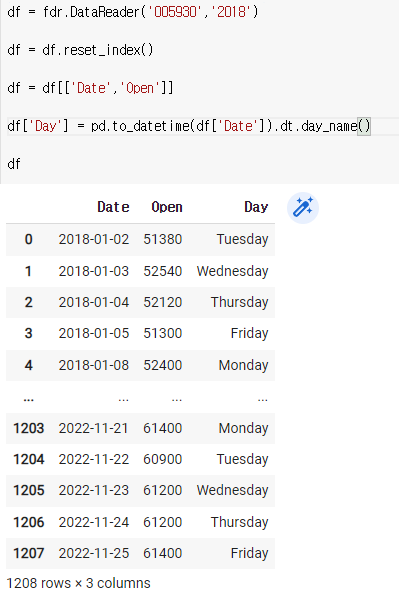
저걸 넣음으로써 뒤에 이렇게 요일이 붙게된다.
이런것은 어떻게 찾냐하면 인터넷에 검색해서 찾으면 된다고 한다.
월요일하고 금요일만 남겨보자
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
df
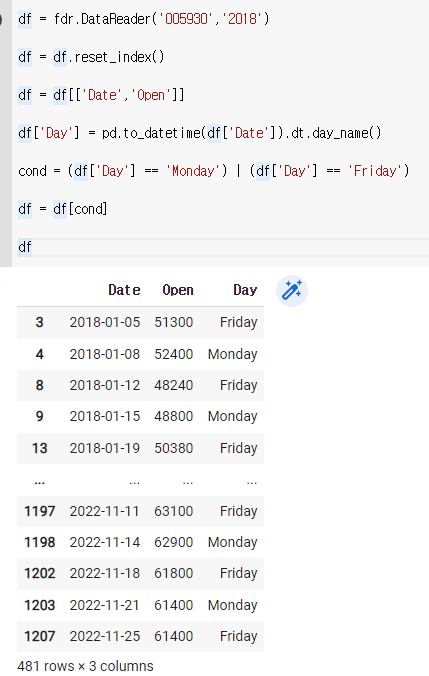
*여기서 또는 대신에 사용된 |는 shift + (역슬레이스)를 치면 나온다.
여기서는 월요일로 시작해서 금요일로 끝나야만 하기 때문에
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])df
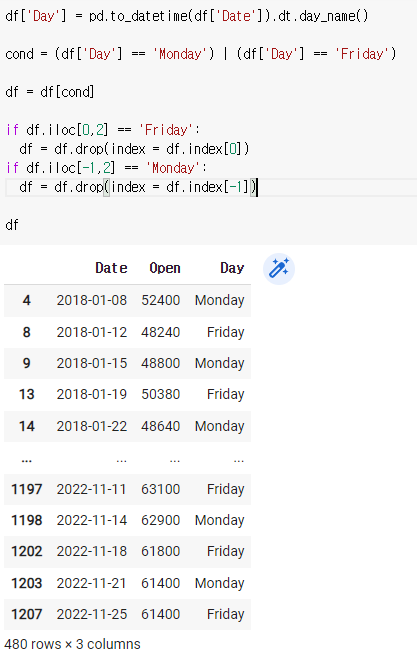
'0번째 줄의 2번째 칸이 Friday면 drop해줘라 index의 0번째줄 전체를' 이라는 뜻이다.
마지막으로 휴일을 고려해보면 Monday나 Friday가 두번연속 나오면 Monday는 앞에줄을 Friday는 뒤에줄을 없애면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df[cond]
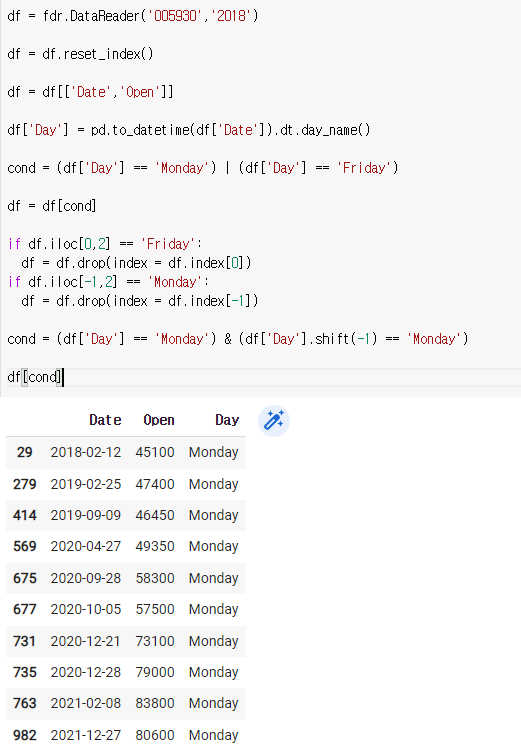
여기 표시된 애들을 싹다 지워줘야 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df
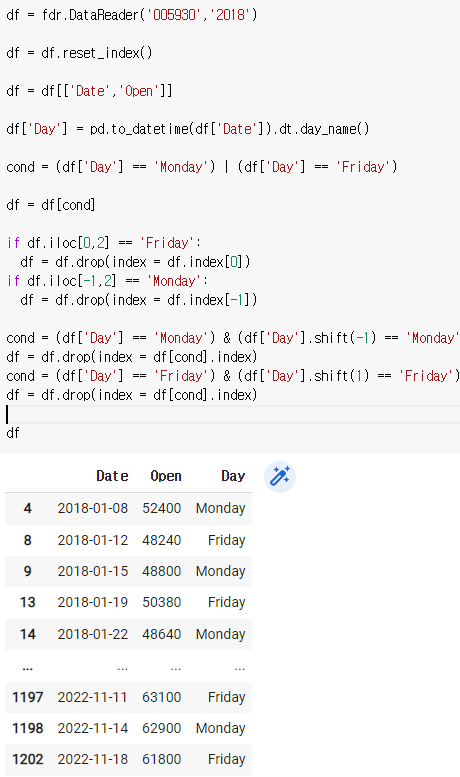
df = df.drop(index = df[cond].index)는 df[cond]자체를 없앤다.
그 다음 수익률을 계산해보자
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df

df['Open_fri'] = df['Open'].shift(-1) 는 오픈의 금요값을 이동시켜서 옆에다 만든 후에
df = df[df['Day']=='Monday']이걸로 월요일 값만 표기를 하면 된다.
그리고 우리한테 필요한 open값과 open_fri값만 가져온 후 이름을 바꿔주면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df
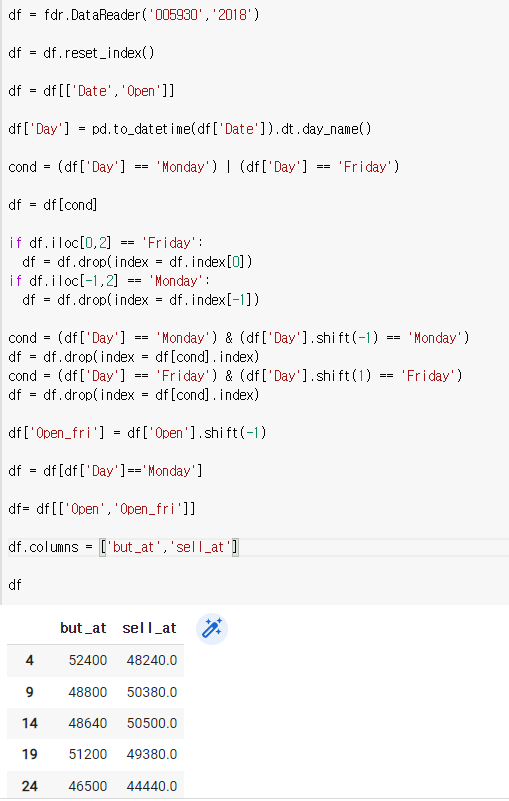
수익률(sell_at/buy_at)로 return값을 만든후에 그 값을 cumprod하면 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
df[['return']].cumprod()
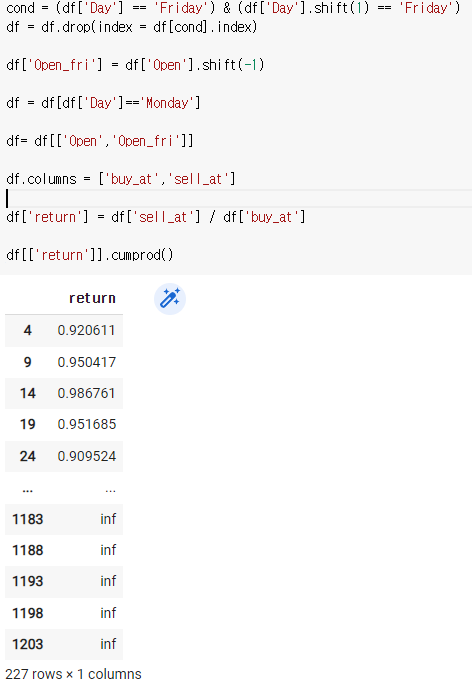
밑에 inf라는 오류가 발생했는데 이는 나누는 값에 0이 들어간 것이다. 이런것들을 싹 없애줘야 된다.
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]df[['return']].cumprod()
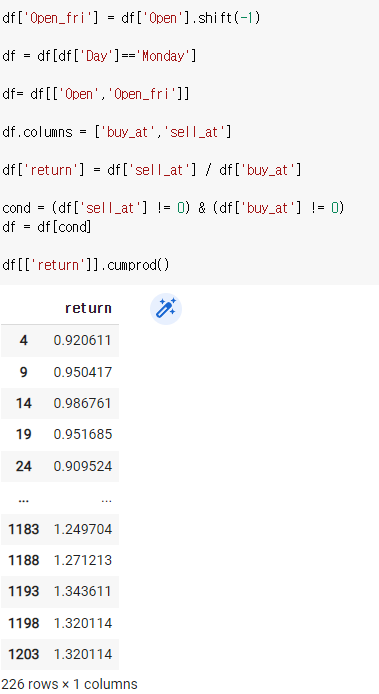
최종적으로 수익률은
df = fdr.DataReader('005930','2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]df[['return']].cumprod().iloc[-1,-1] -1

이제 이것을 함수로 만들면
>def get_return_mf(code):
df = fdr.DataReader(code,'2018')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Monday') | (df['Day'] == 'Friday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day']=='Monday']
df= df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]return df[['return']].cumprod().iloc[-1,-1] -1

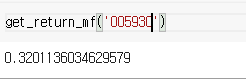
이제 월 금 전략이 가장 잘 맞는 종목을 추려보자
!pip install dart-fss
설치 후 코드스니펫 가져와 붙여넣자
import dart_fss as dart_fss
import pandas as pdapi_key = 'API키 입력하기'
dart_fss.set_api_key(api_key=api_key)all = dart_fss.api.filings.get_corp_code()
df = pd.DataFrame(all)
df_listed = df[df['stock_code'].notnull()]
for row in df_listed.sample(10)[['stock_code','corp_name']].itertuples():
print(row)
마지막 반복문 부분만 때서 코드로 따로 만듦녀 안해도 되는 부분을 빼고 실행할 수 있다.

row[1]은 회사코드, row[2]는 회사명을 뜻한다.
이것을 여러 회사에 적용해서 최고 효율의 회사를 봐보자
df = pd.DataFrame()
for row in df_listed.sample(10)[['stock_code','corp_name']].itertuples():
try:
doc = {
'name' : row[2],
'return' : get_return_mf(row[1])
}
df = df.append(doc, ignore_index = True)
except:
print(f'error - {row[2]}')df.sort_values(by='return', ascending=False)
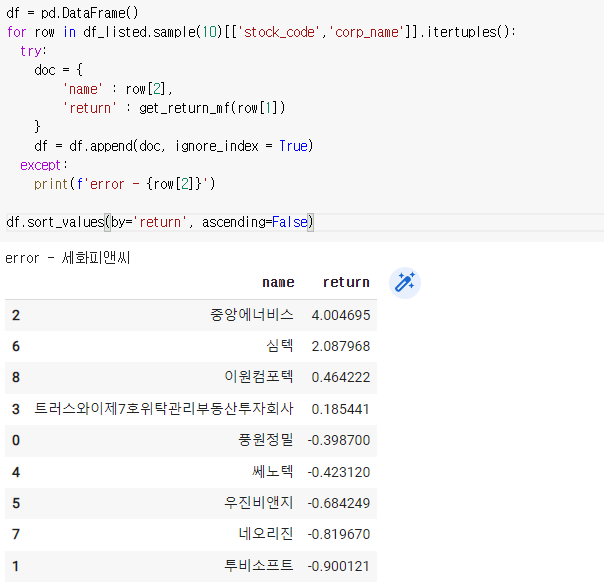
return을 기준으로 내림차순을 해주면 보기 편하다.
자꾸 doc { , } 를 까먹는다 항목당 ,를 꼭 넣어주자
