관측 가능성(Observability)은 시스템이 생성한 데이터를 기반으로 시스템의 상태를 이해하고 측정하는 능력입니다. 이는 현대적인 애플리케이션과 인프라 관리에서 필수적인 개념으로, 예상치 못한 상황에서 발생하는 데이터를 통해 실행 가능한 인사이트를 얻는 데 중점을 둡니다. 이러한 인사이트는 동적인 환경에서 특히 중요합니다.
관측 가능성의 이점
관측 가능성을 시스템이나 애플리케이션에 구현함으로써 얻을 수 있는 주요 이점 중 하나는 내부 작업에 대한 통찰력입니다. 이를 통해 다음과 같은 혜택을 얻을 수 있습니다:
- 빠른 문제 해결: 시스템의 내부 작업을 더 잘 이해함으로써 문제를 더 신속하게 해결할 수 있습니다.
- 어려운 문제 감지: 일반적인 모니터링으로는 발견하기 어려운 문제를 감지할 수 있습니다.
- 애플리케이션 성능 모니터링: 애플리케이션의 성능 및 상태를 모니터링하여 최적화를 도울 수 있습니다.
- 팀 간 협업 향상: 문제의 원인과 해결 방법을 더 명확하게 전달할 수 있어, 팀 간의 협업이 원활해집니다.
관측 가능성의 필요성
관측 가능성이 없는 경우, 애플리케이션은 블랙박스처럼 작동합니다. 일부 데이터는 들어오고 일부는 나가지만, 내부에서 무슨 일이 일어나는지 전혀 알 수 없습니다. 그러나 관측 가능성을 통해 시스템의 개별 블록들이 어떻게 작동하고 상호작용하는지 파악할 수 있습니다. 이를 통해 문제가 발생했을 때 어떤 구성 요소가 실패했는지, 그 이유는 무엇인지 명확히 이해할 수 있습니다.
현대 시스템에서의 관측 가능성
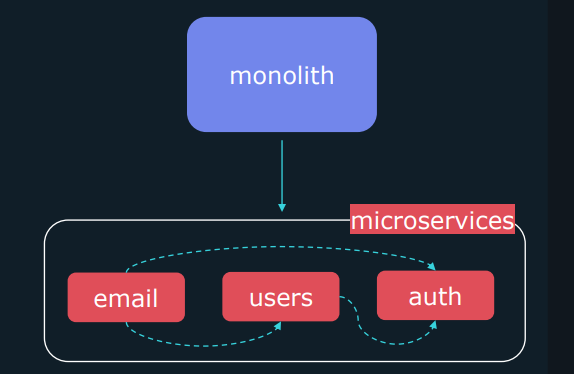
시간이 지나면서 애플리케이션과 시스템의 아키텍처는 점점 더 복잡해지고 있습니다. 특히 마이크로서비스 아키텍처를 채택하는 기업이 증가하면서 관측 가능성의 중요성도 더욱 부각되고 있습니다. 전통적인 모놀리틱 구조에서는 단일 애플리케이션에 대한 로그와 데이터를 한 번에 볼 수 있었지만, 마이크로서비스 아키텍처에서는 여러 개별 구성 요소가 서로 상호작용합니다. 이러한 복잡성으로 인해 문제 해결도 어려워지며, 각각의 구성 요소가 어떻게 연결되어 있는지 파악하는 것이 중요해졌습니다.
관측 가능성의 세 가지 기둥: 로그, 메트릭스, 트레이스
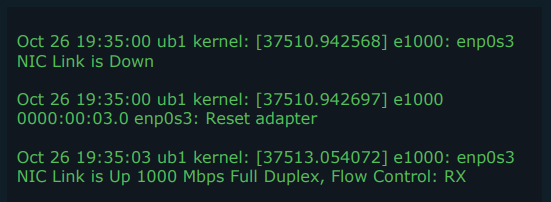
- 로그(Log): 로그는 발생한 사건에 대한 기록입니다. 이는 특정 사건에 대한 정보를 포함하며, 가장 일반적인 관측 자료입니다. 로그는 사건이 발생한 시점과 특정 사건에 대한 메시지를 포함합니다.
-
메트릭스(Metrics): 메트릭스는 시스템 상태를 숫자로 표현합니다. 예를 들어 CPU 부하, 열린 파일 수, API 응답 시간 등이 있습니다. 메트릭스는 메트릭 이름, 값, 타임스탬프, 추가 정보 등의 요소로 구성됩니다.

-
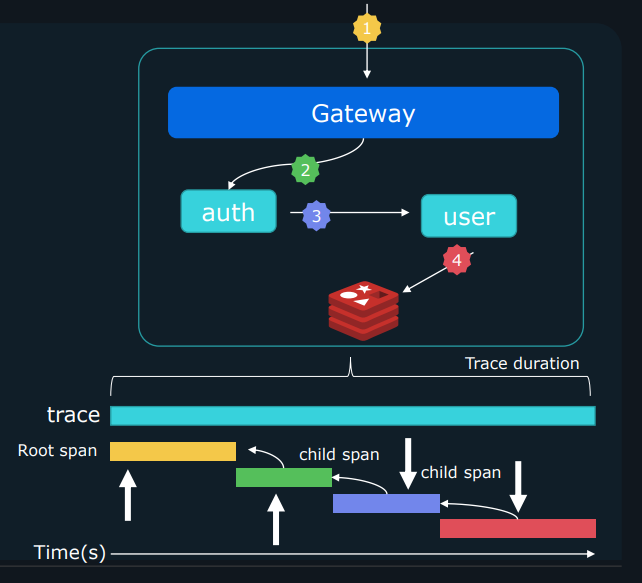
트레이스(Trace): 트레이스는 시스템을 통과하는 요청을 추적합니다. 이를 통해 각 단계마다 애플리케이션이 어떻게 작동하는지 이해할 수 있습니다. 각 요청은 '스팬(Span)'이라는 이벤트로 구성되며, 스팬은 시작 시간, 지속 시간, 부모 ID 등을 추적합니다.
Prometheus와 관측 가능성
Prometheus는 메트릭스를 수집하고 집계하는 데 특화된 모니터링 솔루션입니다. Prometheus는 로그나 트레이스를 처리하지 않으며, 오로지 메트릭스에 집중합니다. 따라서 관측 가능성을 완벽히 구현하기 위해서는 다른 애플리케이션과 함께 사용해야 합니다.
마치며
관측 가능성은 복잡한 현대 시스템에서 필수적인 요소입니다. 시스템의 상태를 보다 명확하게 파악하고, 문제를 신속히 해결하며, 효율적인 운영을 지원하는 관측 가능성의 세 가지 기둥을 통해 더 나은 시스템 관리와 성능을 기대할 수 있습니다. 관측 가능성의 구현은 시스템 운영과 개발팀 모두에게 큰 가치를 제공하며, 궁극적으로는 사용자 경험을 개선하는 데 기여합니다.
