10:00 ~ 13:00
어제 밤에 실험을 하면서 코드가 잘 못 작성됐다는 사실을 뒤늦게 발견했다. 코드 테스크를 위해 데이터 하나를 뽑아서 넣었는데, 함수를 해당 데이터로만 추론하도록 작성했었다.
어처구니 없는 실수에서 수정해서 돌리니 이번에는 출력 파싱 문제가 있었다. GPT는 프롬프팅이 잘 먹었지만, 백틱이 들어간 경우에 에러가 발생했었다. 어떻게 하면 코드 블럭을 다시 파싱할 수 있을지 찾아보았다. 코드를 여러 가지로 수정하면서 실험을 진행했다. 덕분에 충전한 크레딧이 살살 녹았다...
13:00 ~ 16:00
OutputFixingParser를 활용하면 더 안전하게 파싱할 수 있다는 걸 발견했다. 처음에는 Langchain 말고 openai 모듈을 사용하려고 했었다. 파이프라이닝 중간을 interrupt하기 위해서는 좀 더 낮은 레벨의 스키마를 사용해야 한다고 판단했었다. 하지만 막상 사용해보니 파싱 과정이 복잡했고, 변경도 까다로웠다. Langchain 공식 문서를 쭉 훑어보다가 OutputFixingParser를 발견했고 적용하니 정상적으로 실험을 할 수 있었다. 최초로 정상적인 실험을 마치니 결과가 예상과 전혀 다르게 나왔다.
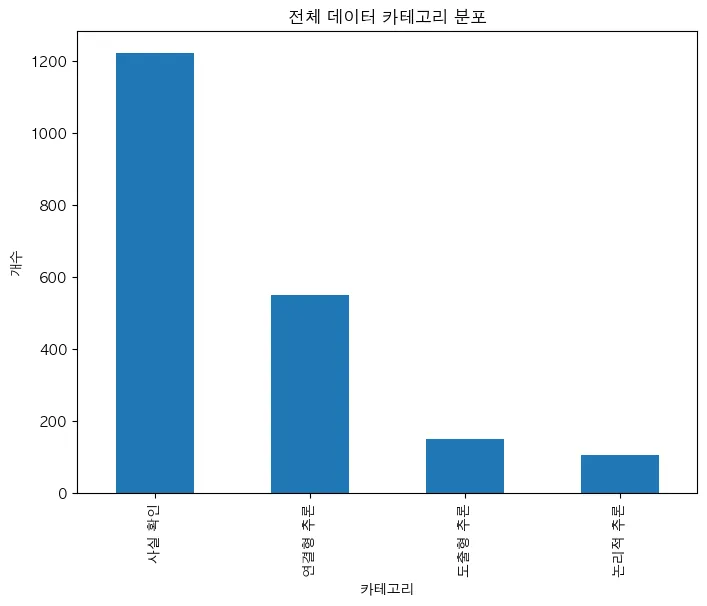
문제 데이터를 직접 살펴보면 배경지식이 필요한 경우가 매우 많았는데, 단순한 사실 확인 유형이 가장 많은게 이해가 되지 않았다. 프롬프트와 유형 분류를 다시 고민했다.
16:00 ~ 19:00
리팩토링 PR 리뷰하면서 많은 내용을 배웠다. PreTrainedTokenizer와 PreTrainedTokenizerFast의 차이점은 이전 프로젝트로 얄팍하게 배웠었다. 전자는 파이썬으로 구동되고, 후자는 Rust로 작성된 코드로 돌아간다는 차이점이었다. 리팩토링 PR에서 커밋 기록을 보니, 타입 힌트를 PreTrainedTokenizerFast로 명시했다. 이유는 .vocab 린트가 PreTrainedTokenizer에는 적용되지 않기 때문이었다. 리뷰를 하면서 PreTrainedTokenizerFast를 호출하면 해당하는 토크나이저가 없는 경우에는 PreTrainedTokenzier 형식으로 로드한다는 점을 알게 됐다.
문제 유형 분류 기준을 좀 더 명확하게 설정했다. 설정한 기준은 다음과 같다.
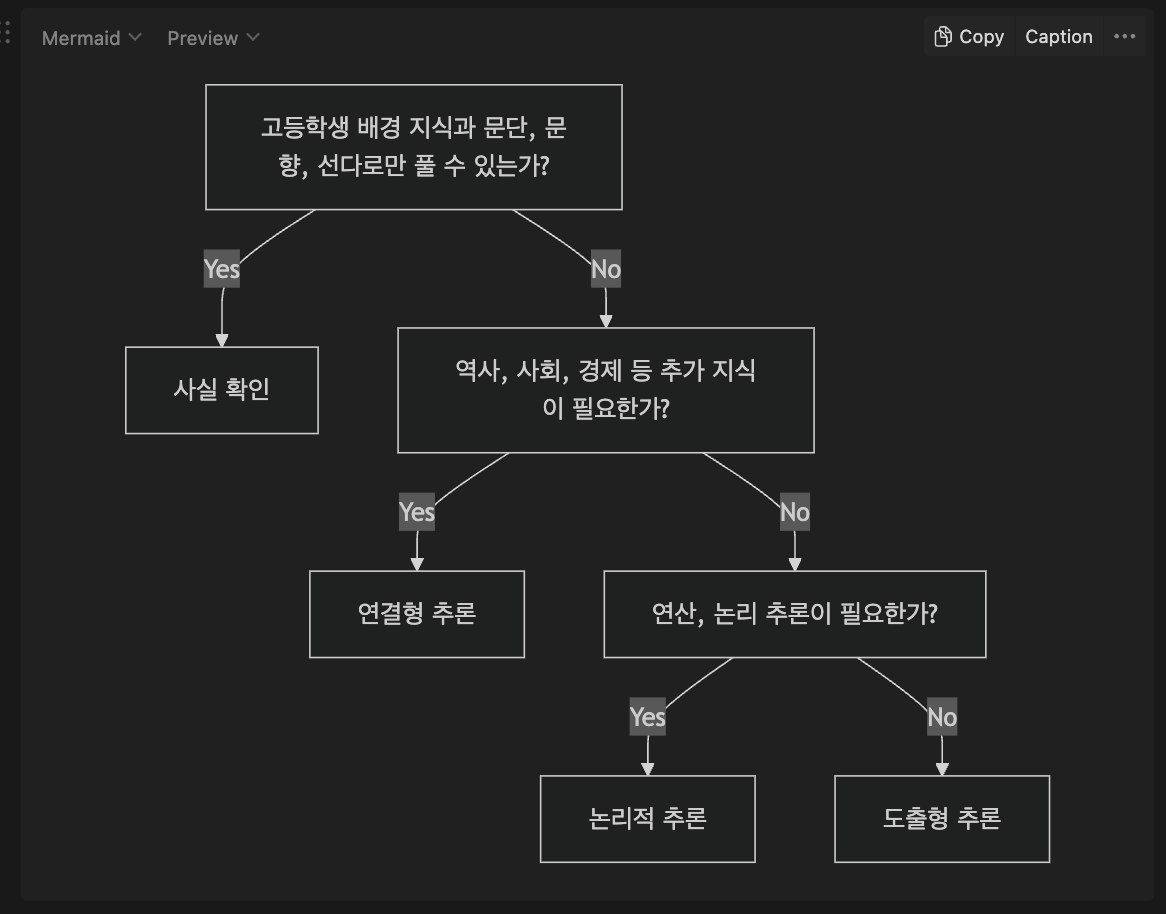
위 분류 기준을 사용해 ToT를 적용해서 프롬프트를 다시 설계하고 실험을 돌리고 있다. 실험 결과는 역시 사실 확인 문항이 많이 나왔는데, 자세히 살펴보니 신문 기사를 그대로 크롤링해오고 기사 네용을 묻는 문항이 많았다. 위 기준에 따라 연결형 추론과 도출형 추론이 좀 애매하게 분류가 되긴했지만, 나름 괜찮은 결과라고 생각이 들어 PR을 날렸다.
