부스트캠프 AI NLP 14주차
1.[부스트캠프] Day 66 회고

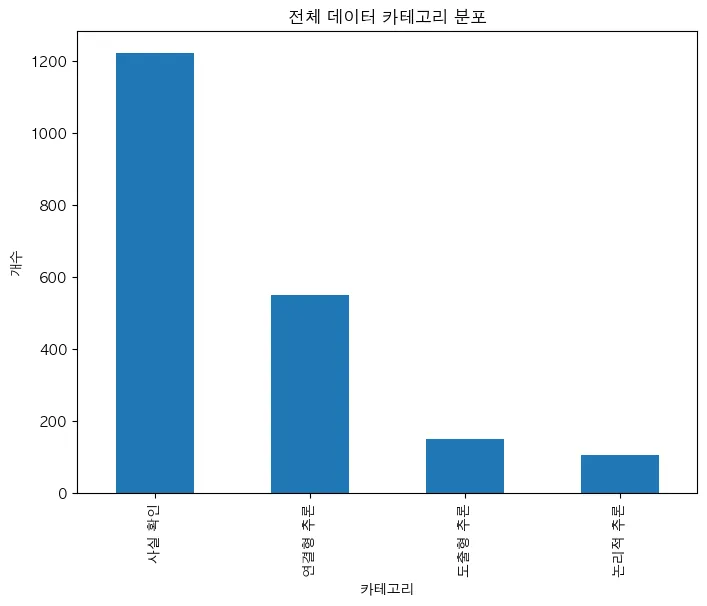
본격적으로 데이터 EDA에 착수했다. gpt 4o mini를 활용해 문제 유형을 분류했다. 분류 카테고리는 다음과 같았다.사실 확인 유형: 지문 내 정보를 대조하면서 정답을 고르는 유형도출형 추론 유형: 지문 내 정보를 가공해 정답을 도출하는 유형연결형 추론 유형: 지
2.[부스트캠프] Day 67 회고
어제 밤에 실험을 하면서 코드가 잘 못 작성됐다는 사실을 뒤늦게 발견했다. 코드 테스크를 위해 데이터 하나를 뽑아서 넣었는데, 함수를 해당 데이터로만 추론하도록 작성했었다. 어처구니 없는 실수에서 수정해서 돌리니 이번에는 출력 파싱 문제가 있었다. GPT는 프롬프팅이
3.[부스트캠프] Day 68 회고
Teacher-Student 모델을 도입하려고 했다. 그러나 데이터 분포가 여러모로 이상하다는 걸 발견했다. 우선, 문제 자체가 이상한 경우가 많았다. 문제 지시 사항이 모호해서 무엇을 대상으로 문제를 풀어야 하는지 불분명한 경우다. 그 다음, 문제 유형이 수능과 다른
4.[부스트캠프] Day 69 회고
멘토링을 했다. 멘토님꼐서 프로젝트 진행 사항 피드백, 논문 읽기/찾기/활용하기 방법, Mixed Precision & Gradient Accumulation & Gradient Checkpointing & Activation Checkpointing을 소개해주셨다.
5.[부스트캠프] Day 70 회고
데이터 증강을 여러 세부 테스크로 나눠서 진행했다. 우선 데이터 분류가 먼저 선행되어야한다고 판단했다. 이전에 제시한 데이터 증강 기준에 따르면 유형이 바뀌면서 데이터에 추가하는 작업이기 때문이다. 분류가 완료되면 외적 추론 유형에서 내적 추론 유형으로 문제를 수정하면