논문 정보
- Title: Learning Data Augmentation Strategies for Object Detection
- Authors: Zoph, Barret, et al. (Google Research)
- Conference: ECCV 2020
- Posted: March 16, 2022.
Abstract
Data augmentation은 딥러닝 모델 학습에서 핵심적인 요소이며, 이미지 분류(Image Classification)에서는 성능 향상 효과가 잘 알려져 있다.
그러나 Object Detection에서는 데이터 증강의 효과와 최적 전략이 충분히 연구되지 않았다. Detection은 bounding box 주석 비용이 높아 데이터 수가 제한적인 경우가 많기 때문에, 데이터 증강의 중요성이 오히려 더 크다.
본 논문에서는
- 이미지 분류에서 사용하던 증강 기법을 Detection에 적용했을 때의 한계를 보이고,
- Object Detection에 특화된 데이터 증강 정책을 자동으로 학습하는 방법을 제안한다.
1. Introduction
딥러닝 모델은 대규모 데이터에서 가장 강력한 성능을 보이며, 이를 보완하기 위한 방법으로 데이터 증강이 널리 사용되어 왔다.
이미지 분류 분야에서는 좌우 반전, 이동, 색상 변형 등의 수작업 증강 전략이 표준처럼 사용되고 있다.
최근에는 이러한 수작업 설계 대신,
- 데이터로부터 최적의 증강 정책을 학습하는 AutoAugment 계열 연구들이 등장했고
- 이미지 분류 성능에서 큰 향상을 보여주었다.
하지만 Object Detection에서는 다음과 같은 추가적인 어려움이 존재한다.
- Bounding box 위치·크기를 함께 고려해야 함
- 객체 내부만 변형하거나, 기하 변환 시 box 정합성 유지 필요
- Classification 증강 전략을 그대로 쓰면 효과가 제한적
이 논문은 이러한 문제의식에서 출발하여
“Detection을 위한 증강 정책은 Detection 데이터로 직접 학습되어야 한다”는 가설을 검증한다.
2. Related Work
기존 데이터 증강 연구는 대부분 특정 데이터셋 또는 모델 구조에 강하게 의존해 왔다.
- MNIST: elastic distortion
- ImageNet: random crop, flip
- Object Detection: flip, multi-scale training, object-centric crop
일부 연구에서는
- Random Erasing / Cutout
- Cut-and-Paste
- Adversarial Occlusion
등을 사용해 detection 성능을 개선하려 했으나, 일반화 가능한 정책 설계는 어려웠다.
한편, AutoAugment, Smart Augmentation 등은 이미지 분류(Classification) 문제에 한정되어 적용되었으며, Detection 특유의 bounding box 제약을 다루지 못했다.
본 연구는
- Bounding box를 직접 고려한 연산을 포함하고
- Validation 성능(mAP)을 기준으로 Detection 전용 증강 정책을 자동 탐색한다는 점에서 기존 연구와 차별된다.
3. Methods
Augmentation Policy Definition
데이터 증강 정책(policy)은 K개의 sub-policy로 구성된다.
학습 중 각 이미지마다 sub-policy 하나를 무작위로 선택하여 적용한다.
각 sub-policy는
- N = 2개의 augmentation operation으로 구성되며
- 각 operation은 다음 3요소로 정의된다.
(Operation, Probability, Magnitude)
- Probability는 해당 연산을 적용할 확률이며,
- Magnitude는 변형 강도를 의미한다.
Augmentation Operations
총 22개의 augmentation operation을 정의하며, 세 가지 범주로 구분된다.
(1) Color Operations
Bounding box 위치 변화 없음
- Equalize
- Contrast
- Brightness
- Color
- Sharpness
- Solarize / SolarizeAdd
=> 이미지 분류에서 차용한 연산
(2) Geometric Operations
이미지와 bounding box를 함께 변형
- Rotate
- ShearX / ShearY
- TranslateX / TranslateY
=> 기하 변환 시 bounding box 좌표와 크기를 함께 수정하여 정합성 유지
(3) Bounding Box Only Operations
- BBox Only Equalize
- BBox Only TranslateY
- BBox Only Rotate
- BBox Only FlipLR
=> Bounding box 내부 픽셀만 변형, box 위치·크기는 유지
=> 객체 표현 다양성 증가 + 배경 정보 보존
Search Space & Optimization
- Magnitude: 0~10 구간을 6단계로 이산화
- Probability: 6단계로 이산화
Search space 크기:
=> RNN Controller + PPO 기반 Reinforcement Learning으로 탐색
Reward: Validation set의 mAP
Search Setup
- COCO training set 중 5K 이미지만 사용
- Detector: RetinaNet + ResNet-50
- Controller는 20K policies를 탐색
- TPU 400개, 48시간 소요
=> 소규모 데이터로 찾은 정책이 전체 COCO에도 일반화됨
4. Results
4.1 Learning a Data Augmentation Policy
학습된 정책을 분석한 결과,
- Rotate 연산이 가장 빈번하게 등장
- Equalize, BBox Only TranslateY도 자주 사용됨
특히 Rotate는 bounding box가 커지는 부작용이 있음에도 불구하고
Detection 성능에 매우 효과적임이 확인되었다.
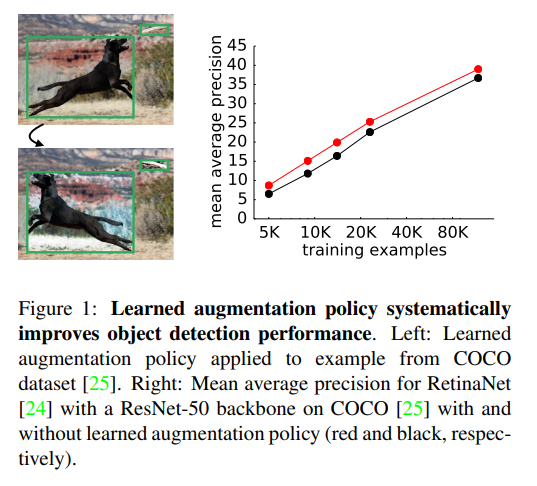
4.2 Learned Augmentation Policy Improves Object Detection
COCO + RetinaNet 실험 결과:
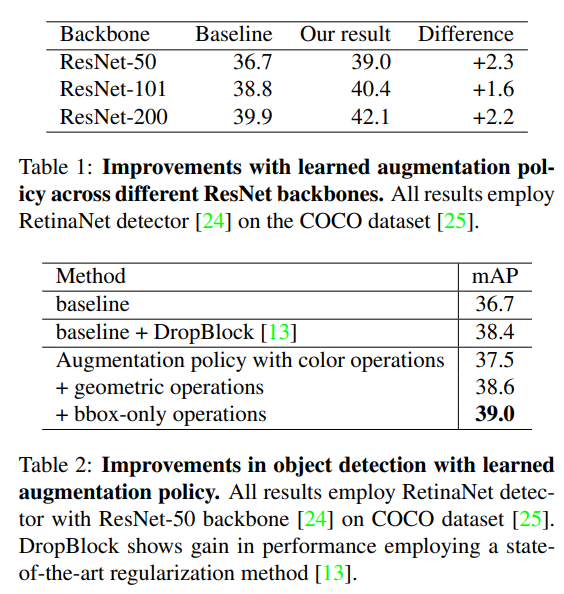
기존 정규화 기법 DropBlock보다 더 큰 성능 향상을 보였다.
4.3 Exploiting learned augmentation policies achieves state-of-the-art object detection
- Backbone: AmoebaNet-D
- Detector: NAS-FPN
- Image size: 1536×1536
- Single-scale inference
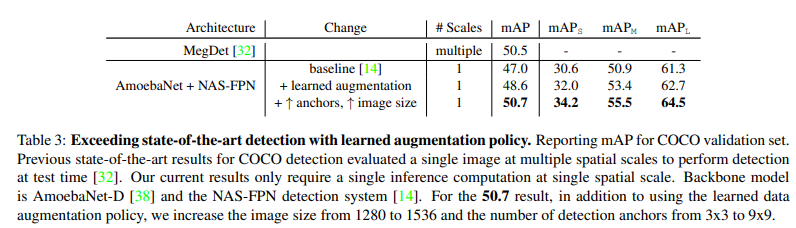
=> 50.7 mAP (COCO)
=> Single-stage detector 기준 SOTA 달성
4.4 Transfer to Other Datasets
PASCAL VOC 2007 실험:
- Faster R-CNN + ResNet-101
- COCO에서 학습한 policy를 그대로 적용

=> mAP@0.5 +2.7% 향상
4.5 Effect of Dataset Size
- 데이터가 적을수록 효과 증가
- Small object(AP_S)에서 특히 큰 향상
9K + learned augmentation > 15K baseline
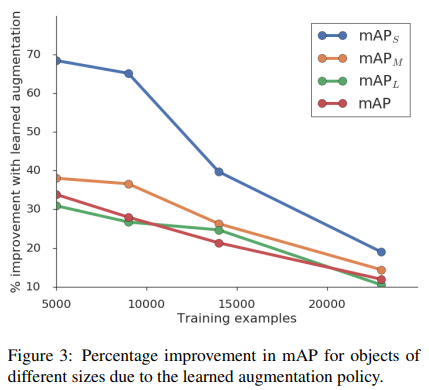
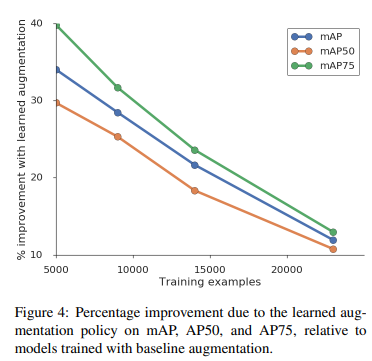
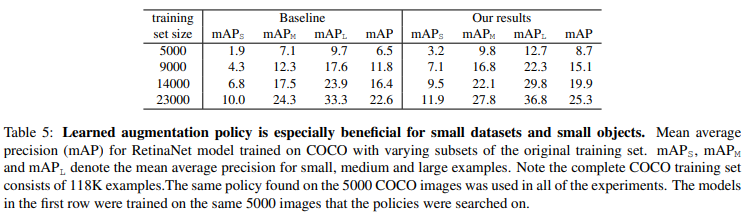
=> 증강 정책이 데이터 증가 효과를 대체
4.6 Regularization Effect
- Learned augmentation 적용 시:
- Training loss 증가
- Weight L2 norm 감소
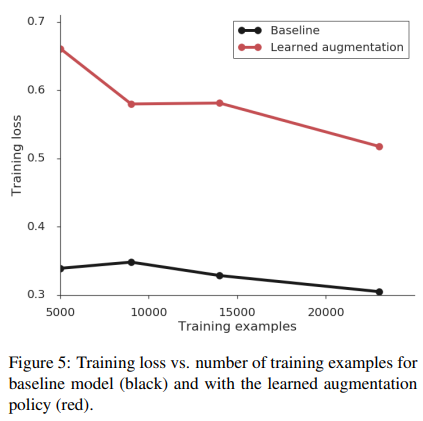
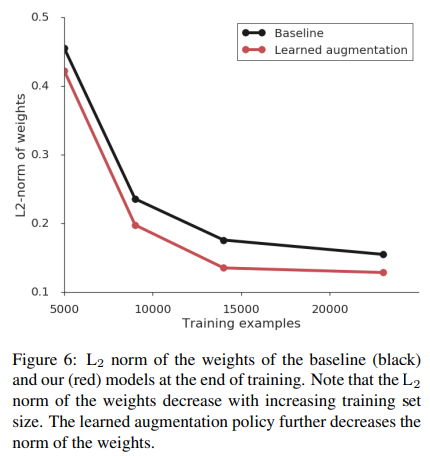
=> 강한 정규화 효과
=> Mixup, DropBlock과 병행 효과는 거의 없음
5. Discussion
학습된 데이터 증강 정책은
- 다양한 데이터셋, 모델, 해상도에서 일반화 가능
- 소규모 데이터 환경에서 특히 강력
추가 데이터 수집 대신 증강 정책 학습이 비용 대비 효율적인 대안이 될 수 있음을 시사함.
Appendix.
A.1 Augmentation Operation Search Space (Table 6)
아래 표는 Controller가 선택할 수 있는 모든 transformation 연산과
각 연산에 대해 예측 가능한 magnitude 범위를 정리한 것이다.
=> 일부 연산(예: Equalize)은 magnitude가 존재하지 않는다.

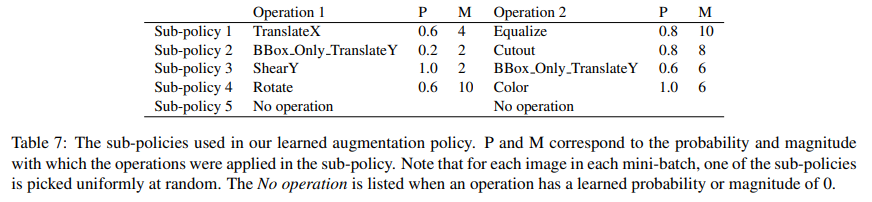
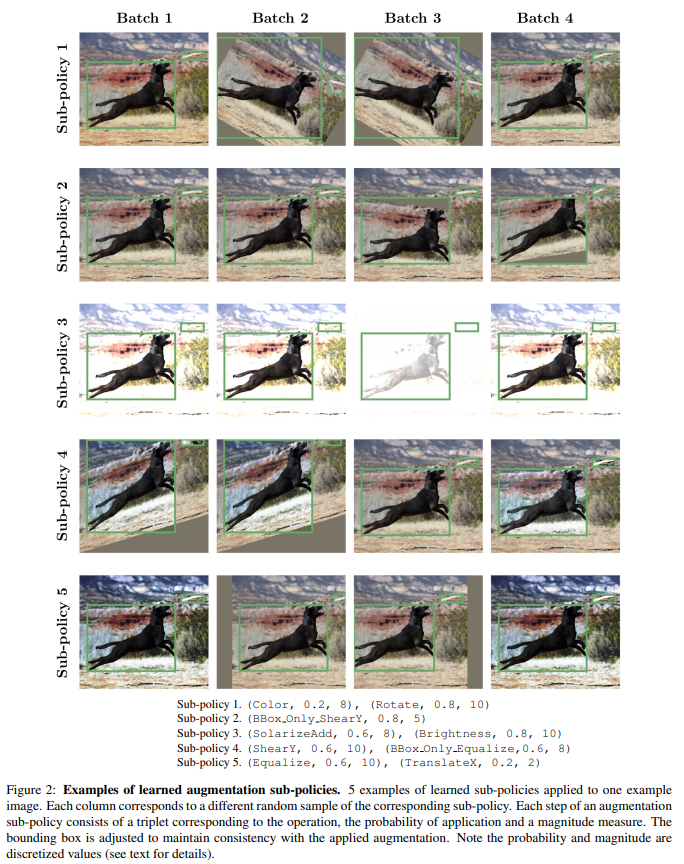
A.2 Learned Augmentation Sub-Policies (Table 7)
아래는 최종적으로 선택된 augmentation policy에 포함된 5개의 sub-policy 구성이다.
- 각 이미지마다 sub-policy 하나를 uniform random으로 선택
- 각 sub-policy는 2개의 연산으로 구성
- P: 적용 확률, M: magnitude