논문 정보
- Title: Fast R-CNN
- Authors: Ross Girshick (Microsoft Research)
- Conference: ICCV 2015
- Posted: March 01, 2022.
Abstract
본 논문은 Fast Region-based Convolutional Network (Fast R-CNN) 을 제안한다.
Fast R-CNN은 기존 R-CNN 계열 객체 검출기의 속도·학습 복잡도 문제를 근본적으로 개선하면서, 동시에 검출 정확도(mAP)를 향상시킨다.
Fast R-CNN은
- 전체 이미지를 한 번만 ConvNet에 통과시키고
- RoI Pooling을 통해 proposal별 feature를 추출하며
- 분류(classification)와 bounding box regression을 단일 네트워크에서 공동 학습한다.
그 결과,
- VGG16 기준 R-CNN 대비 학습 9× 빠름
- 테스트 속도 213× 향상
- PASCAL VOC 2012에서 66% mAP 달성
을 보인다
1. Introduction
딥러닝 기반 ConvNet은 이미지 분류뿐 아니라 객체 검출에서도 큰 성과를 냈다.
그러나 객체 검출은 단순 분류와 달리 다음과 같은 추가적인 한계를 갖는다.
- 수많은 객체 후보 영역(object proposals) 을 처리해야 함
- 후보 영역은 대체로 부정확한 위치이므로, 정밀한 localization 필요
이로 인해 기존 방법들은
- 다단계(multi-stage) 학습 파이프라인
- 높은 계산 비용과 저장 공간 요구
- 느린 추론 속도
라는 문제를 갖는다.
본 논문은 이러한 복잡성을 제거하기 위해 분류와 위치 보정을 하나의 네트워크에서 end-to-end로 학습하는 Fast R-CNN을 제안한다.
1.1 R-CNN and SPPnet
R-CNN의 한계
R-CNN은 proposal마다 ConvNet을 개별 적용하여 높은 정확도를 달성했지만, 다음 문제가 있다.
- Multi-stage training
- ConvNet fine-tuning
- SVM 학습
- Bounding box regressor 학습
- 막대한 저장 비용
- 모든 proposal feature를 디스크에 저장
- VGG16 기준 수백 GB 필요
- 매우 느린 추론
- proposal마다 ConvNet forward
- VGG16 기준 이미지당 47초
SPPnet의 한계
SPPnet은 convolution feature map을 공유하여 속도를 크게 개선했지만,
- 여전히 multi-stage 학습
- SPP layer 이전의 convolution layer를 fine-tuning 불가
- 깊은 네트워크(VGG16)에서 성능 한계
를 가진다.
1.2 Contributions
Fast R-CNN의 핵심 기여는 다음과 같다.
- R-CNN / SPPnet 대비 더 높은 mAP
- 단일 단계(single-stage) 학습
- 모든 convolution layer fine-tuning 가능
- feature 캐싱 불필요 → 디스크 사용 제거
2. Fast R-CNN Architecture and Training
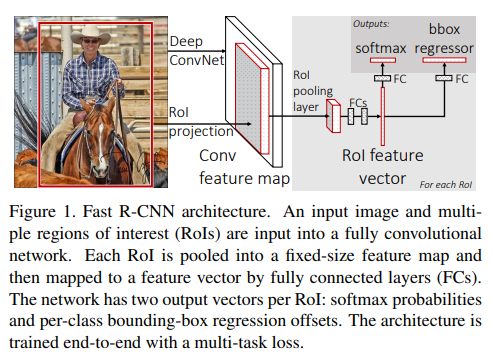
Fast R-CNN은 다음 입력을 받는다.
- 전체 이미지
- 객체 proposal 집합 (e.g., Selective Search)
전체 이미지를 ConvNet에 통과시켜 conv feature map을 생성한 뒤, 각 proposal에 대해 RoI Pooling을 적용한다.
이후 fully connected layer를 거쳐, 각 RoI마다 두 개의 출력이 생성된다.
- Softmax classifier: K개 클래스 + background
- Bounding box regressor: 클래스별 4차원 offset
2.1 The RoI Pooling Layer
RoI Pooling은
- 서로 다른 크기의 RoI를
- 고정 크기 H × W feature map으로 변환한다.
RoI는 (r, c, h, w)로 정의되며, 이를 H × W grid로 분할한 뒤 max pooling을 수행한다.
이는 SPPnet의 spatial pyramid pooling의 특수한 경우(단일 level) 이다.
2.2 Initializing from Pre-trained Networks
ImageNet pre-trained network를 Fast R-CNN으로 변환할 때:
- 마지막 pooling -> RoI Pooling으로 교체
- ImageNet classifier -> detection용 classifier + bbox regressor로 교체
- 입력을 (image, RoI list) 형태로 수정
2.3 Fine-tuning for detection
Fast R-CNN은 모든 layer를 end-to-end로 학습할 수 있다.
이를 가능하게 한 핵심은 mini-batch 구성 방식이다.
Multi-task Loss.
Fast R-CNN은 각 RoI에 대해 분류(classification) 와 위치 보정(localization) 을 동시에 학습하기 위해 multi-task loss를 사용한다.
각 RoI에 대한 전체 loss는 다음과 같이 정의된다.
Classification Loss
분류 손실은 softmax 출력에 대한 log loss이다.
Localization Loss
Bounding box regression에는 Smooth L1 loss를 사용한다.
Smooth L1 함수는 다음과 같이 정의된다:
Mini-batch sampling.
- 한 mini-batch에 N = 2 images
- 각 이미지당 64 RoIs
- 총 RoI 수: 128
같은 이미지에서 나온 RoI들은
- convolution 연산을 공유하므로
- 학습 속도가 64× 이상 향상
Back-propagation through RoI pooling layers.
RoI Pooling layer에서의 back-propagation은
max pooling에서 선택된 argmax 위치로만 gradient를 전달하는 방식으로 이루어진다.
설명을 단순화하기 위해, 하나의 mini-batch에 하나의 이미지만 포함된 경우
()를 가정한다.
(인 경우에도 각 이미지는 독립적으로 처리되므로 동일하게 확장 가능하다.)
Notation (RoI Pooling)
- : RoI pooling layer로 입력되는 번째 activation
- : 번째 RoI에서 번째 pooling output
- : RoI 의 번째 pooling cell에 대응하는 input index 집합 (즉, 해당 pooling sub-window에 포함되는 activation들의 index 집합)
RoI Pooling Forward Pass
RoI Pooling layer에서 각 pooling output 는
해당 sub-window 내의 activation 중 최댓값을 선택하여 계산된다.
여기서 는 sub-window 내에서 activation 값이 최대가 되는 input index를 의미한다.
즉, RoI Pooling은 각 RoI를 고정 크기의 grid로 분할한 뒤, 각 grid cell마다 max pooling을 수행하는 연산이다.
Backward Pass (Gradient Propagation)
RoI Pooling layer의 backward 함수는
argmax switch를 따라 gradient를 누적(accumulate) 한다.
각 input activation 에 대한 loss의 미분은 다음과 같이 계산된다.
여기서,
- 조건이 참이면 1
- 거짓이면 0
SGD Hyper-parameters.
Fully Connected Layers Classification layer
- weights는 다음 분포에서 초기화된다.
Bounding-box regression layer
- weights는 다음 분포에서 초기화된다.
Bias
- 모든 bias는 0으로 초기화된다.
2.4 Scale invariance
두 가지 전략을 비교한다.
- Single-scale (brute force)
- s = 600 고정
- 네트워크가 직접 scale-invariance 학습
- Multi-scale (image pyramid)
- 여러 해상도 사용
- 연산 비용 증가
실험 결과, 깊은 네트워크에서는 single-scale이 속도, 정확도 균형이 가장 좋음
3. Fast R-CNN detection
Fast R-CNN 네트워크가 fine-tuning 된 이후, 객체 검출(detection)은 사실상 하나의 forward pass를 수행하는 것으로 이루어진다.
(단, object proposal은 사전에 계산되어 있다고 가정한다.)
네트워크의 입력은 다음과 같다.
- 입력 이미지 (또는 image pyramid, 여러 이미지의 리스트 형태)
- 점수를 매길 개의 object proposal
테스트 시 은 일반적으로 약 2000개이며, 실험에 따라 약 45k까지 증가하는 경우도 고려한다.
Image Pyramid 사용 시 RoI 할당
Image pyramid를 사용하는 경우, 각 RoI 는 scale이 적용된 RoI의 면적이 픽셀에 가장 가까워지도록 적절한 pyramid scale에 할당된다.
Detection Output
각 테스트 RoI 에 대해 forward pass는 다음 두 출력을 생성한다.
- 클래스 posterior 확률 분포
- Bounding-box regression offsets
Bounding-box regression은 각 클래스 에 대해 개별적으로 예측되며, RoI 에 대한 상대적 offset 형태로 출력된다.
Detection Confidence
RoI 가 클래스 에 속할 detection confidence는 softmax 출력 확률을 그대로 사용한다.
Non-Maximum Suppression (NMS)
각 클래스에 대해 독립적으로 Non-Maximum Suppression (NMS) 를 수행하며,
R-CNN에서 사용한 동일한 알고리즘과 설정을 따른다.
3.1 Truncated SVD for faster detection
전체 이미지 분류(image classification)에서는 fully connected layer의 계산 비용이 convolution layer에 비해 작다.
그러나 객체 검출에서는
- 처리해야 할 RoI 수가 매우 많고
- 전체 forward pass 시간의 거의 절반이 fully connected layer 계산에 사용된다.
=> 이를 가속하기 위해 Truncated SVD를 적용한다.
SVD 기반 Fully Connected Layer 압축
Fully connected layer의 weight matrix 가 크기일 때, 이를 다음과 같이 근사 분해한다.
여기서,
-
: 상위 개의 left-singular vector -
: 상위 개의 singular value를 갖는 대각 행렬 -
: 상위 개의 right-singular vector
Parameter Reduction 효과
기존 파라미터 수는 다음과 같다.
Truncated SVD 적용 후 파라미터 수는 다음과 같이 감소한다.
인 경우,
파라미터 수와 연산량이 크게 감소한다.
Network 구조 변경
Truncated SVD를 적용하면,
- 기존의 하나의 fully connected layer를
- 두 개의 fully connected layer로 대체한다.
구성은 다음과 같다.
1. 첫 번째 FC layer
- weight:
- bias 없음
- 두 번째 FC layer
- weight:
- 기존 의 bias 사용
두 layer 사이에는 비선형 활성함수(non-linearity)를 적용하지 않는다.
4. Main results
4.1 Experimental setup
- Backbone: CaffeNet(S), VGG-M(M), VGG16(L)
- Single-scale (s = 600)
- Bounding box regression 사용
4.2 VOC 2010 and 2012 results
- VOC12 test:
- 65.7% mAP
- 추가 데이터 사용 시 68.4%
- 기존 R-CNN 기반 방법 대비
- 2 orders of magnitude faster
- 동일 backbone 기준 최고 성능
4.3 VOC 2007 results
- Fast R-CNN: 66.9% mAP
- R-CNN: 66.0%
- SPPnet: 63.1%
=> Conv layer fine-tuning 효과가 핵심
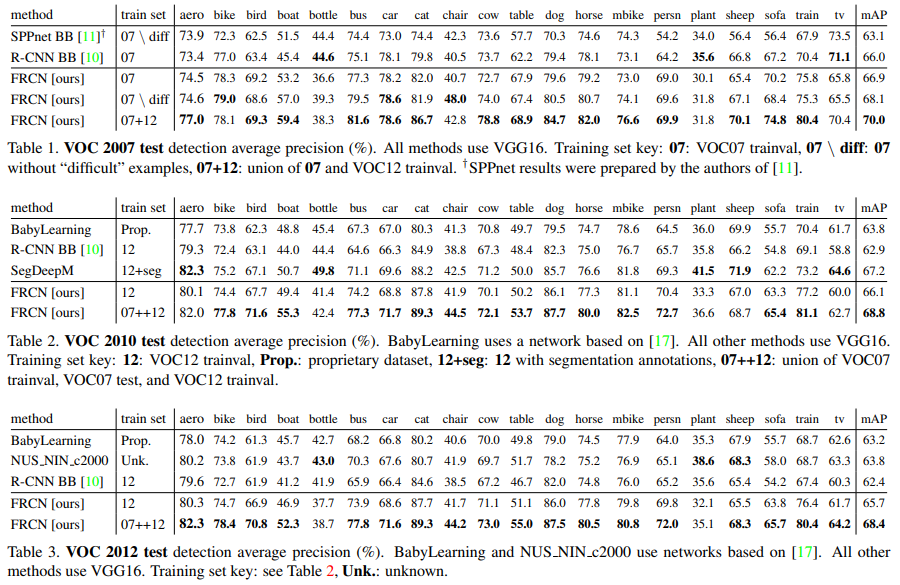
4.4 Training and testing time
- VGG16 기준:
- Training: 84h → 9.5h
- Testing: 47s → 0.22s/image (with SVD)
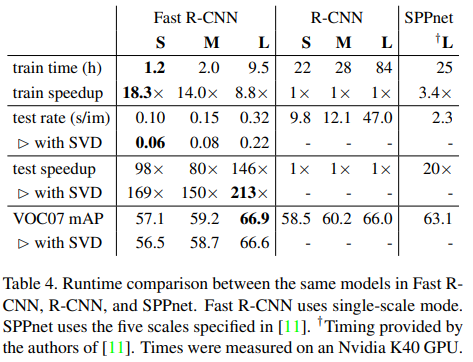
Truncated SVD. (속도 개선 분석)
Truncated SVD는 모델 압축(model compression) 기법으로, Fast R-CNN에서 detection 속도를 크게 향상시키면서도 정확도(mAP) 손실을 최소화한다.
논문에서는 Truncated SVD를 적용함으로써
- detection time을 30% 이상 감소
- mAP 감소는 약 0.3%p
- 추가 fine-tuning 없이도 적용 가능
함을 보인다.

적용 대상 Layer (VGG16)
Truncated SVD는 VGG16의 fully connected layer에 적용된다.
-
fc6 : 25088 × 4096 weight matrix
-> 상위 1024개 singular value 사용 -
fc7 : 4096 × 4096 weight matrix
-> 상위 256개 singular value 사용
이러한 저랭크 근사를 통해 fully connected layer의 연산량과 파라미터 수를 크게 줄인다.
4.5 Which layers to fine-tune?
VGG16에서
- conv3_1 이상 fine-tuning이면 충분
- conv1, conv2는 일반적 feature

=> 깊은 네트워크일수록 conv layer fine-tuning 필수
5. Design evaluation
5.1 Does multi-task training help?
Multi-task loss 사용 시
- classification-only 대비 +0.8 ~ +1.1 mAP
- Stage-wise 학습보다 항상 우수

5.2 Scale invariance: to brute force or finesse?
- Multi-scale -> 약간의 mAP 증가
- 그러나 속도 손해가 큼
=> Single-scale이 가장 합리적 선택
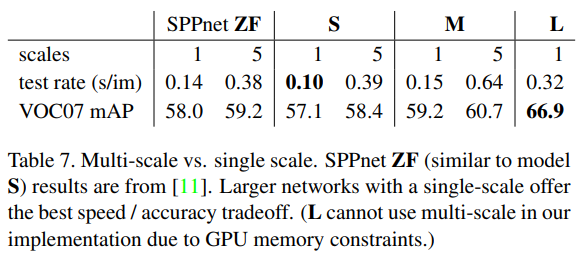
5.3 Do we need more training data?
- VOC07 + VOC12 병합 시 66.9 -> 70.0 mAP
- Fast R-CNN은 추가 데이터에 잘 scale
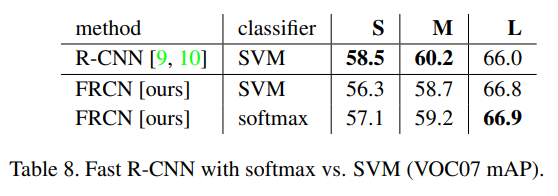
5.4 Do SVMs outperform softmax?
- Softmax가 SVM보다 0.1~0.8 mAP 높음
- Multi-stage SVM 불필요
5.5 Are more proposals always better?
Proposal 수 증가 시
- mAP는 증가 후 감소
- Average Recall(AR)과 mAP는 항상 상관되지 않음
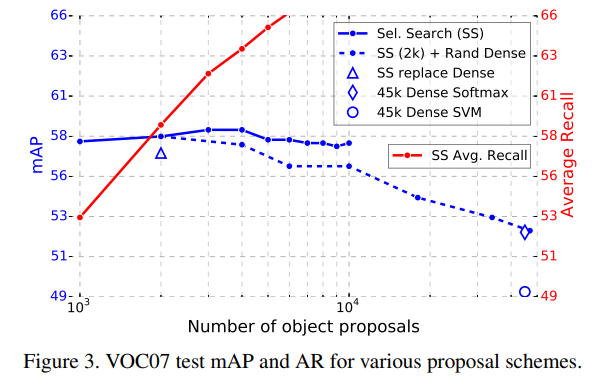
=> Sparse proposal + 강한 classifier가 더 중요
5.6 Preliminary MS COCO Results
Fast R-CNN (VGG16)은 MS COCO에서 PASCAL mAP 35.9%, COCO AP 19.7%의baseline detection 성능을 달성하였다.
6. Conclusion
Fast R-CNN은
- 단순하고
- 빠르며
- 정확한
객체 검출 프레임워크를 제시한다.
특히,
- end-to-end 학습
- RoI Pooling
- multi-task loss
는 이후 Faster R-CNN, Mask R-CNN으로 이어지는 Region-based Detection 계열의 핵심 기반이 됨.
